Проектирование IT-систем
Это перевод на русский язык курса разработчика из Apple Karan Pratap Singh.
Оригинальный текст курса на английском языке выложен на GitHub автора, на его личном сайте , а электронная версия книги на leanpub. Пожалуйста, ставьте ⭐ если курс оказался для Вас полезен!
Содержание
-
Вступление
-
Глава I
-
Глава II
-
Глава III
- Многозвенная архитектура
- Брокеры сообщений
- Очереди сообщений
- Публикация/подписка
- Корпоративная сервиса шина (ESB)
- Монолитная и Микросервисная архитектура
- Event-Driven Architecture (EDA)
- Генерация событий
- Command and Query Responsibility Segregation (CQRS)
- API шлюзы
- REST, GraphQL, gRPC
- Long polling, WebSockets, Server-Sent Events (SSE)
-
Глава IV
-
Глава V
-
Приложение
Что такое системное проектирование?
Прежде чем мы начнем этот курс, давайте поговорим о том, что такое системное проектирование.
Системное проектирование - это процесс определения архитектуры, интерфейсов и данных для системы, которая удовлетворяет определенным требованиям. Системное проектирование соответствует потребностям вашего бизнеса или организации через последовательные и эффективные системы. Для этого требуется системный подход к созданию и инжинирингу систем. Хорошее системное проектирование требует от нас думать обо всем, начиная от инфраструктуры и заканчивая данными и их хранением.
Почему системное проектирование так важно?
Системное проектирование помогает нам определить решение, которое удовлетворяет бизнес-требованиям. Это одно из первых решений, которые мы можем принять при построении системы. Часто это крайне важно думать на высоком уровне, поскольку эти решения очень сложно исправить позднее. Это также облегчает обоснование и управление архитектурными изменениями по мере развития системы.
IP
IP-адрес - это уникальный адрес, который идентифицирует устройство в Интернете или локальной сети. IP означает "Протокол интернета", который представляет собой набор правил, регулирующих формат данных, отправляемых через Интернет или локальную сеть.
По сути, IP-адреса являются идентификатором, который позволяет отправлять информацию между устройствами в сети. Они содержат информацию о местоположении и обеспечивают доступность устройств для обмена данными. Интернету необходим способ различать разные компьютеры, маршрутизаторы и веб-сайты. IP-адреса предоставляют такой способ и являются важной частью работы Интернета.
Версии
Существуют различные версии IP-адресов:
IPv4
Оригинальный Интернет-протокол - это IPv4, который использует 32-битную числовую точечно-десятичную нотацию и позволяет использовать около 4 миллиардов IP-адресов. Изначально этого было более чем достаточно, но по мере роста использования интернета нам понадобилось что-то лучшее.
Пример: 102.22.192.181
IPv6
IPv6 - это новый протокол, который был представлен в 1998 году. Развёртывание началось в середине 2000-х годов, и поскольку число пользователей интернета выросло в геометрической прогрессии, оно продолжается до сих пор.
Этот новый протокол использует 128-битную алфавитно-цифровую шестнадцатеричную нотацию. Это означает, что IPv6 может обеспечить около ~340e+36 IP-адресов. Этого более чем достаточно для удовлетворения растущего спроса на многие годы вперёд.
Пример: 2001:0db8:85a3:0000:0000:8a2e:0370:7334
Типы
Давайте обсудим типы IP-адресов:
Публичный
Публичный IP-адрес - это адрес, где один основной адрес связан со всей вашей сетью. В этом типе IP-адреса каждое подключенное устройство имеет один и тот же IP-адрес.
Пример: IP-адрес, предоставленный вашему маршрутизатору поставщиком услуг интернета.
Приватный
Приватный IP-адрес - это уникальный IP-номер, назначаемый каждому устройству, подключающемуся к вашей сети интернет, включая устройства, такие как компьютеры, планшеты и смартфоны, используемые в вашем доме.
Пример: IP-адреса, создаваемые вашим домашним маршрутизатором для ваших устройств.
Статический
Статический IP-адрес не меняется и создаётся вручную, в отличие от автоматического назначения. Эти адреса обычно более дорогие, но более надёжные.
Пример: Они обычно используются для важных вещей, таких как надёжные геолокационные службы, удалённый доступ, хостинг серверов и т. д.
Динамический
Динамический IP-адрес меняется с течением времени и не всегда остаётся таким же. Он назначается сервером динамической конфигурации хоста (DHCP). Динамические IP-адреса являются наиболее распространённым типом IP-адресов. Они дешевле в развёртывании и позволяют повторно использовать IP-адреса в сети по мере необходимости.
Пример: Они более часто используются для оборудования потребителей и личного использования.
Модель OSI
Модель OSI - это логическая и концептуальная модель, которая определяет сетевое взаимодействие, используемое системами, открытыми для взаимодействия и связи с другими системами. Модель открытой системной интеркоммуникации (OSI) также определяет логическую сеть и эффективно описывает передачу компьютерных пакетов с использованием различных уровней протоколов.
Модель OSI можно рассматривать как универсальный язык компьютерных сетей. Она основана на концепции разделения системы связи на семь абстрактных уровней, каждый из которых стекается на предыдущий.
Почему модель OSI важна?
Модель открытой системной интеркоммуникации (OSI) определила общие термины, используемые в обсуждениях и документировании сетевых технологий. Это позволяет нам разбирать очень сложные процессы связи и оценивать их компоненты.
Хотя данная модель не непосредственно реализуется в сетях TCP/IP, которые наиболее распространены сегодня, она по-прежнему может помочь нам во многом:
- Упростить процесс поиска и угрозы по всему стеку протоколов.
- Поощрять производителей аппаратного обеспечения создавать сетевые продукты, способные взаимодействовать друг с другом по сети.
- Быть неотъемлемой частью формирования мышления о безопасности.
- Разделять сложные функции на более простые компоненты.
Слои
Можно выделить следующие семь абстрактных слоев OSI-модели, от верхнего уровня к нижнему:
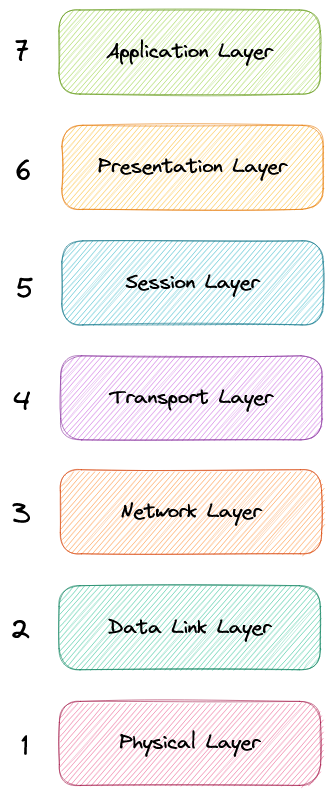
Прикладной уровень (Application)
Этот уровень единственный прямо взаимодействует с данными от пользователя. Программные приложения, такие как веб-браузеры и почтовые клиенты, полагаются на прикладной уровень для инициирования коммуникации. Однако следует четко понимать, что клиентские программные приложения не являются частью прикладного уровня; скорее, прикладной уровень отвечает за протоколы и манипуляции данными, на которых программное обеспечение основывается для представления значимых данных пользователю. Протоколы прикладного уровня включают HTTP и SMTP.
Уровень представления (Presentation)
Уровень представления также называется уровнем трансляции. Здесь данные от прикладного уровня извлекаются и манипулируются в соответствии с необходимым форматом для передачи по сети. Функции уровня представления включают трансляцию, шифрование/дешифрование и сжатие.
Сеансовый уровень (Session)
Этот уровень отвечает за открытие и закрытие коммуникации между двумя устройствами. Время между открытием и закрытием коммуникации известно как сеанс. Сеансовый уровень обеспечивает, чтобы сеанс оставался открытым достаточно долго для передачи всех обмениваемых данных, а затем быстро закрывает сеанс, чтобы избежать расточительного расходования ресурсов. Сеансовый уровень также синхронизирует передачу данных с контрольными точками.
Транспортный уровень (Transport)
Транспортный уровень (также известный как уровень 4) отвечает за конечно-конечное взаимодействие между двумя устройствами. Это включает в себя взятие данных с сеансового уровня и разбиение их на части, называемые сегментами, перед отправкой на сетевой уровень (уровень 3). Он также отвечает за сборку сегментов на принимающем устройстве в данные, которые может использовать сеансовый уровень.
Сетевой уровень (Network)
Сетевой уровень отвечает за облегчение передачи данных между двумя различными сетями. Сетевой уровень разбивает сегменты с транспортного уровня на более мелкие единицы, называемые пакетами, на устройстве отправителя, а затем собирает эти пакеты на устройстве получателя. Сетевой уровень также находит оптимальный физический путь для достижения данных до их назначения, это известно как маршрутизация. Если два устройства, обменивающихся данными, находятся в одной сети, то сетевой уровень не требуется.
Канальный уровень (Data Link)
Канальный уровень очень похож на сетевой уровень, за исключением того, что он облегчает передачу данных между двумя устройствами в одной сети. Канальный уровень берет пакеты с сетевого уровня и разбивает их на более мелкие части, называемые кадрами.
Физический уровень (Physical)
На этом уровне находится физическое оборудование, участвующее в передаче данных, такое как кабели и коммутаторы. Это также уровень, на котором данные преобразуются в поток битов, который представляет собой последовательность единиц и нулей. Физический уровень обоих устройств также должен договориться о соглашении по сигналу, чтобы единицы можно было различить от нулей на обоих устройствах.
Протоколы TCP и UDP
TCP
Протокол управления передачей (TCP) ориентирован на установление соединения, что означает, что после установки соединения данные могут передаваться в обе стороны. У TCP встроены системы проверки ошибок и гарантии доставки данных в том порядке, в котором они были отправлены, что делает его идеальным протоколом для передачи информации, такой как статические изображения, файлы данных и веб-страницы.
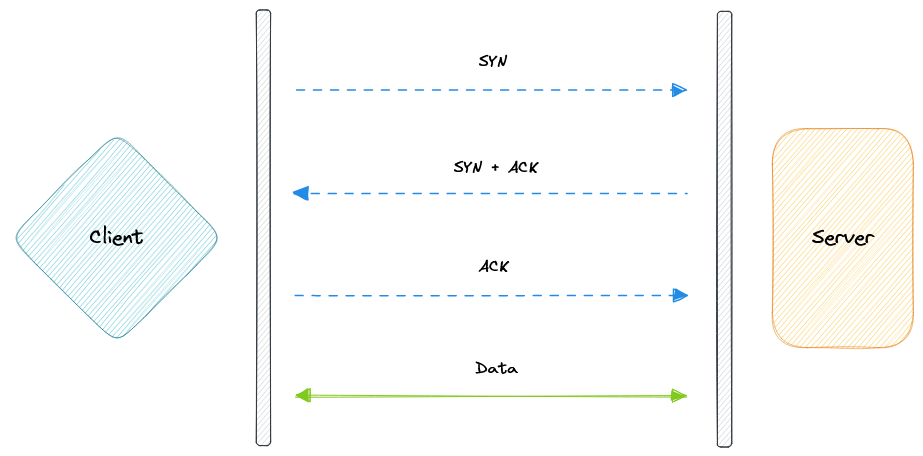
Но хотя TCP инстинктивно надежен, его механизмы обратной связи также приводят к бóльшему накладному расходу, что влечет за собой более интенсивное использование доступной пропускной способности в сети.
UDP
Протокол пользовательских дейтаграмм (UDP) - это более простой, безсоединительный интернет-протокол, в котором проверка ошибок и восстановление не требуются. С UDP нет накладных расходов на открытие соединения, поддержание соединения или завершение соединения. Данные непрерывно отправляются получателю, вне зависимости от того, получает ли он их или нет.
Он широко предпочтителен для реального времени связи, такой как трансляция или многопрограммная передача сети. Мы должны использовать UDP вместо TCP, когда нам нужна минимальная задержка, и потеря данных хуже, чем задержка данных.
TCP против UDP
TCP - это протокол, ориентированный на установление соединения, в то время как UDP - это протокол без установления соединения. Одно из ключевых различий между TCP и UDP - это скорость, поскольку TCP сравнительно медленнее, чем UDP. В целом, UDP является более быстрым, простым и эффективным протоколом, однако повторная передача потерянных пакетов данных возможна только с TCP.
TCP обеспечивает упорядоченную доставку данных от пользователя к серверу (и наоборот), в то время как UDP не предназначен для точечного обмена данными, и не проверяет готовность получателя.
| Функция | TCP | UDP |
|---|---|---|
| Подключение | Требует установленного соединения | Протокол без установления соединения |
| Гарантированная доставка | Может гарантировать доставку данных | Не может гарантировать доставку данных |
| Переотправка | Возможна повторная отправка потерянных пакетов | Нет повторной отправки потерянных пакетов |
| Скорость | Медленнее, чем UDP | Быстрее, чем TCP |
| Рассылка | Не поддерживает рассылку | Поддерживает рассылку |
| Сферы применения | HTTPS, HTTP, SMTP, POP, FTP, и т. д. | Видеопотоки, DNS, VoIP, и т. д. |
Domain Name System (DNS)
Ранее мы узнали о IP-адресах, которые позволяют каждой машине подключаться к другим машинам. Но, как мы знаем, людям удобнее работать с именами, чем с числами. Легче запомнить имя, например, google.com, чем что-то вроде 122.250.192.232.
Это приводит нас к системе доменных имен (DNS), которая является иерархической и децентрализованной системой именования, используемой для преобразования человеко-читаемых доменных имен в IP-адреса.
Как работает DNS
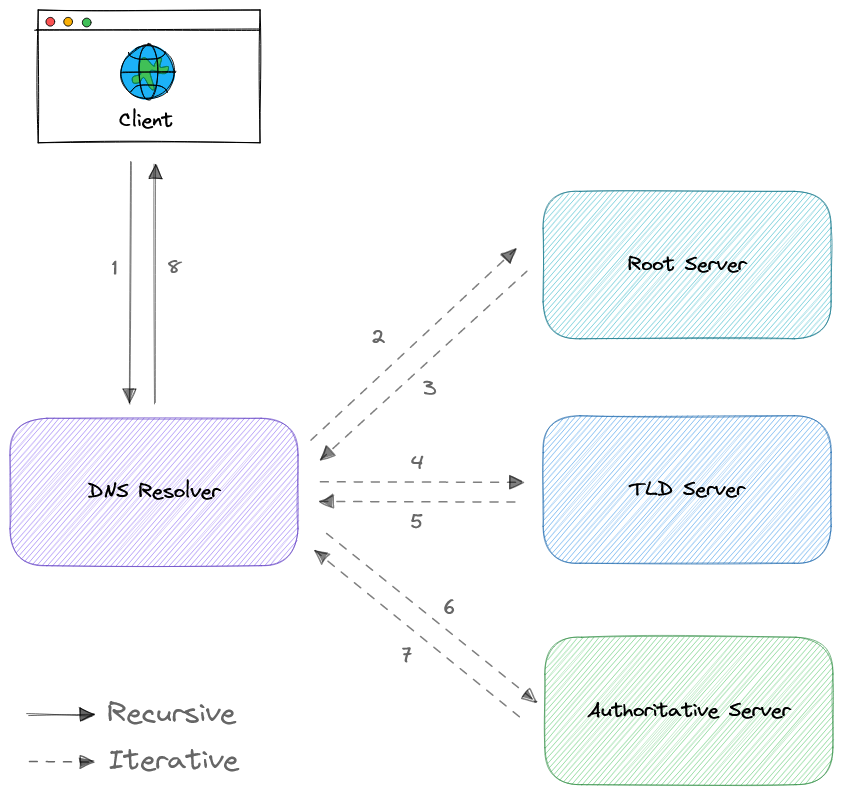
DNS-запрос включает в себя следующие восемь шагов:
- Клиент вводит example.com в веб-браузер, запрос отправляется в интернет и получается DNS-резольвером.
- Резольвер рекурсивно запрашивает DNS корневой сервер.
- Корневой сервер отвечает резольверу адресом доменного имени верхнего уровня (TLD).
- Резольвер затем делает запрос к TLD-серверу
.com. - Сервер TLD затем отвечает IP-адресом сервера имен домена, example.com.
- Наконец, рекурсивный резольвер отправляет запрос на сервер имен домена.
- IP-адрес для example.com затем возвращается резольверу с сервера имен.
- DNS-резольвер затем отвечает веб-браузеру IP-адресом исходного запрошенного домена.
После того как IP-адрес был разрешен, клиент должен иметь возможность запросить контент по разрешенному IP-адресу. Например, разрешенный IP может возвращать веб-страницу для отображения в браузере.
Типы серверов
Теперь давайте рассмотрим четыре основные группы серверов, составляющих инфраструктуру DNS.
DNS-резольвер
DNS-резольвер (также известный как рекурсивный DNS-резольвер) - это первый этап в DNS-запросе. Рекурсивный резольвер действует как посредник между клиентом и DNS-сервером имен. После получения DNS-запроса от веб-клиента рекурсивный резольвер либо отвечает кэшированными данными, либо отправляет запрос корневому DNS-серверу, за которым следует запрос к DNS-серверу TLD, а затем последний запрос к авторитетному DNS-серверу. После получения ответа от авторитетного DNS-сервера, содержащего запрошенный IP-адрес, рекурсивный резольвер отправляет ответ клиенту.
Корневой DNS-сервер
Корневой DNS-сервер принимает запрос рекурсивного резольвера, включающий доменное имя, и отвечает, направляя рекурсивный резольвер к DNS-серверу TLD на основе расширения этого домена (.com, .net, .org и т. д.). Корневые DNS-серверы находятся под надзором некоммерческой организации под названием Интернет-корпорация по присвоению имен и номеров (ICANN).
Существует 13 корневых DNS-серверов, известных каждому рекурсивному резольверу. Следует отметить, что хотя существует 13 корневых DNS-серверов, это не означает, что в системе корневых DNS-серверов есть только 13 машин. Существует 13 типов корневых DNS-серверов, но у каждого из них есть несколько копий по всему миру, которые используют маршрутизацию Anycast для обеспечения быстрых ответов.
TLD nameserver
Top Level Domain (TLD) nameserver поддерживает информацию для всех доменных имен, которые имеют общее доменное расширение, такое как .com, .net или что-то ещё после последней точки в URL-адресе.
Управление серверами имен верхнего уровня доменного имени осуществляется Управлением назначения интернет-ресурсов (IANA), которое является подразделением ICANN. IANA разделяет сервера имен верхнего уровня доменного имени на две основные группы:
- Общие домены верхнего уровня: Это домены, такие как
.com,.org,.net,.eduи.gov. - Домены верхнего уровня по странам: Это включает любые домены, которые специфичны для страны или региона. Примеры включают
.uk,.us,.ruи.jp.
Авторитетный DNS-сервер
Авторитетный сервер имен обычно является последним шагом резольвера в пути к IP-адресу. Авторитетный сервер имен содержит информацию, специфичную для обслуживаемого имени домена (например, google.com), и может предоставить рекурсивному резольверу IP-адрес этого сервера, найденного в DNS-записи типа A, или, если домен имеет запись CNAME (псевдоним), он предоставит рекурсивному резольверу псевдоним домена, после чего рекурсивный резольвер должен будет выполнить новый DNS-запрос, чтобы получить запись от авторитетного сервера имен (чаще всего запись типа A, содержащую IP-адрес). Если не удается найти домен, возвращается сообщение NXDOMAIN.
Типы запросов
Существует три типа запросов в DNS-системе:
Рекурсивный
В рекурсивном запросе DNS-клиент требует, чтобы DNS-сервер (обычно рекурсивный DNS-резольвер) отвечал клиенту либо запрошенной ресурсной записью, либо сообщением об ошибке, если резольвер не может найти запись.
Итеративный
В итеративном запросе DNS-клиент предоставляет имя хоста, а DNS-резольвер возвращает наилучший ответ, который может. Если DNS-резольвер имеет соответствующие DNS-записи в своем кэше, он возвращает их. Если нет, он направляет DNS-клиента к корневому серверу или другому авторитетному серверу имен, который находится ближе всего к требуемой DNS-зоне. Затем DNS-клиент должен повторить запрос напрямую к DNS-серверу, на который он был направлен.
Не рекурсивный
Не рекурсивный запрос - это запрос, в котором DNS-резольвер уже знает ответ. Он либо немедленно возвращает DNS-запись, потому что уже хранит ее в локальном кэше, либо запрашивает DNS-сервер имен, который является авторитетным для этой записи, что означает, что он определенно содержит правильный IP-адрес для этого имени хоста. В обоих случаях нет необходимости в дополнительных раундах запросов (как в рекурсивных или итеративных запросах). Вместо этого ответ немедленно возвращается клиенту.
Типы записей
DNS-записи (также известные как файлы зон) - это инструкции, которые находятся на авторитетных DNS-серверах и содержат информацию о домене, включая IP-адрес, связанный с этим доменом, и способ обработки запросов для этого домена.
Эти записи представляют собой серию текстовых файлов, написанных в так называемом синтаксисе DNS. Синтаксис DNS - это просто строка символов, используемая в качестве команд, которые указывают DNS-серверу, что делать. У всех DNS-записей также есть "TTL", что означает время жизни, и указывает, как часто DNS-сервер будет обновлять эту запись.
Существует больше типов записей, но на данный момент давайте рассмотрим некоторые из наиболее часто используемых:
- A (Address record): Это запись, которая содержит IP-адрес домена.
- AAAA (IPv6 Address record): Запись, которая содержит IPv6-адрес домена (в отличие от записей A, которые хранят IPv4-адрес).
- CNAME (Canonical Name record): Перенаправляет один домен или поддомен на другой домен, НЕ предоставляет IP-адрес.
- MX (Mail exchanger record): Направляет почту на почтовый сервер.
- TXT (Text Record): Эта запись позволяет администратору сохранять текстовые заметки в записи. Эти записи часто используются для защиты электронной почты.
- NS (Name Server records): Хранит сервер имен для записи DNS.
- SOA (Start of Authority): Хранит административную информацию о домене.
- SRV (Service Location record): Указывает порт для конкретных служб.
- PTR (Reverse-lookup Pointer record): Предоставляет обратное преобразование имени домена.
- CERT (Certificate record): Хранит открытые ключевые сертификаты.
Поддомены
Поддомен - это дополнительная часть основного имени нашего домена. Он обычно используется для логического разделения веб-сайта на разделы. Мы можем создать несколько поддоменов или дочерних доменов на основном домене.
Например, blog.example.com, где blog - это поддомен, example - это основной домен, а .com - это домен верхнего уровня (TLD). Аналогичные примеры могут быть support.example.com или careers.example.com.
DNS-зоны
DNS-зона - это отдельная часть пространства доменов, которая делегируется юридическому лицу, такому как человек, организация или компания, ответственному за поддержку DNS-зоны. DNS-зона также представляет собой административную функцию, позволяющую осуществлять детализированный контроль над компонентами DNS, такими как авторитетные серверы имен.
Кэширование DNS
Кэш DNS (иногда называемый кэшем резольвера DNS) - это временная база данных, поддерживаемая операционной системой компьютера, которая содержит записи всех недавних посещений и попыток посещений веб-сайтов и других интернет-доменов. Другими словами, кэш DNS - это просто память о недавних DNS-запросах, к которой наш компьютер может быстро обратиться, когда он пытается определить, как загрузить веб-сайт.
Система доменных имен реализует время жизни (TTL) на каждой DNS-записи. TTL указывает количество секунд, в течение которого запись может быть кэширована DNS-клиентом или сервером. Когда запись хранится в кэше, сохраняется значение TTL, которое сопровождало ее. Сервер продолжает обновлять TTL записи, хранящейся в кэше, отсчитывая каждую секунду. Когда оно достигает нуля, запись удаляется или удаляется из кэша. В этот момент, если получен запрос на эту запись, DNS-сервер должен начать процесс разрешения.
Обратное DNS
Обратное DNS-разрешение — это DNS-запрос для определения доменного имени, связанного с заданным IP-адресом. Это осуществляет противоположное действие по сравнению с более распространенным прямым DNS-запросом, при котором система DNS запрашивается для возврата IP-адреса. Процесс обратного разрешения IP-адреса использует записи PTR. Если на сервере нет записи PTR, он не может выполнить обратный поиск.
Обратные поиски часто используются почтовыми серверами. Почтовые серверы проверяют и определяют, пришло ли сообщение электронной почты с действительного сервера, прежде чем принять его на свою сеть. Многие почтовые серверы отклоняют сообщения от любого сервера, который не поддерживает обратные поиски или считается весьма маловероятным для подлинного.
Примечание: Обратные DNS-запросы не всегда приняты к использованию, поскольку они не являются критическими для нормального функционирования интернета.
Примеры
Примеры наиболее широко используемых DNS-решений:
Балансировка нагрузки
Балансировщик нагрузки позволяет распределить траффик между несколькими ресурсами и обеспечивает высокую степень доступности и надежности, переадресовывая запросы только на доступные сервисы. Это позволяет системе быть гибкой, позволяя добавлять и исключать ресурсы в зависимости от нагрузки.
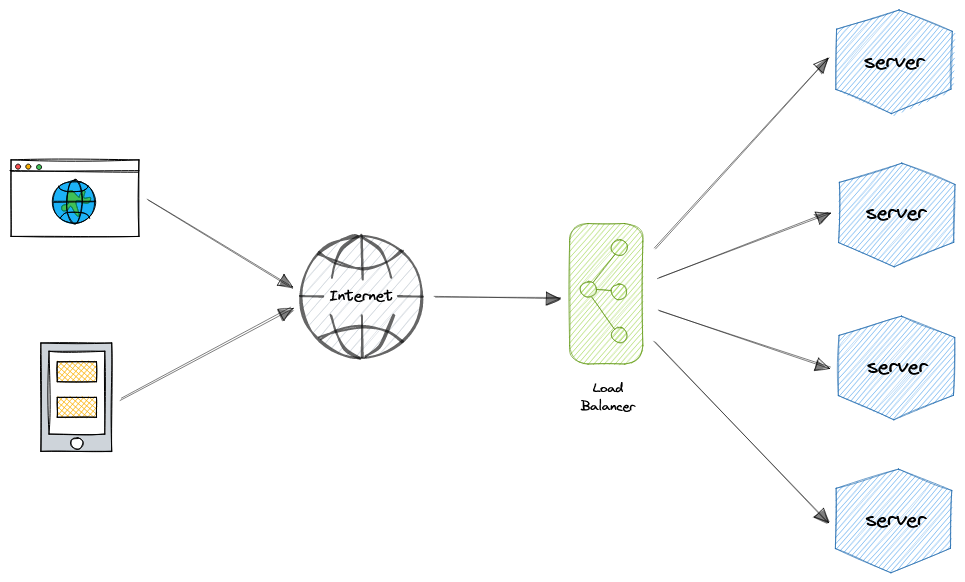
Для дополнительной масштабируемости и резервирования можно использовать балансировщик на каждом слое нашей системы:

А зачем?
Современные сайты с высоким трафиком должны обслуживать сотни тысяч, если не миллионы, одновременных запросов от пользователей или клиентов. Для эффективного масштабирования и удовлетворения этого высокого объема запросов современные лучшие практики в области вычислений обычно требуют добавления большего количества серверов.
Балансировщик нагрузки может находиться перед серверами и направлять запросы клиентов по всем серверам, способным выполнить эти запросы таким образом, чтобы максимизировать скорость и использование мощности. Это гарантирует, что ни один сервер не перегружен, что может привести к снижению производительности. Если один сервер выходит из строя, балансировщик нагрузки перенаправляет трафик на оставшиеся онлайн-серверы. Когда к группе серверов добавляется новый сервер, балансировщик нагрузки автоматически начинает отправлять запросы на него.
Распределение нагрузки
Это является ключевой функцией балансировщиков. Есть несколько принятых вариантов распределения нагрузки:
- Host-based: Распределяет запросы на основе запрашиваемого имени хоста.
- Path-based: Использует я распределения запросов URL целиком, а не только хост.
- Content-based: Исследует весь запрос целиком. Например в таком случае запрос может распределяться в зависимости от значение какого-либо параметра.
Уровни
Обычно балансировщики нагрузки работают на одном из двух уровней:
Сетевой уровень
Это балансировщик нагрузки, который работает на транспортном уровне сети, также известном как уровень 4. Он выполняет маршрутизацию на основе сетевой информации, такой как IP-адреса, и не способен выполнять маршрутизацию на основе содержимого. Это часто выделенные аппаратные устройства, способные работать с высокой скоростью.
Прикладной уровень
Это балансировщик нагрузки, который работает на уровне приложения, также известном как уровень 7. Балансировщики нагрузки могут прочитывать запросы полностью и выполнять маршрутизацию на основе содержимого. Это позволяет управлять нагрузкой на основе полного понимания трафика.
Типы
Давайте рассмотрим разные типы балансировщиков нагрузки:
Программное обеспечение
Программные балансировщики нагрузки обычно легче внедрить, чем аппаратные версии. Они также часто более экономичны и гибки, и используются в сочетании с средами разработки программного обеспечения. Программный подход дает нам гибкость настройки балансировщика нагрузки под конкретные потребности нашей среды. Увеличение гибкости может потребовать больше работы по настройке балансировщика нагрузки. По сравнению с аппаратными версиями, которые предлагают более закрытый подход, программные балансировщики дают нам больше свободы для внесения изменений и обновлений.
Программные балансировщики нагрузки широко используются и доступны как установочные решения, требующие конфигурации и управления, так и как управляемые облачные сервисы.
Аппаратное обеспечение
Как следует из названия, аппаратный балансировщик нагрузки зависит от физического оборудования, установленного на месте, для распределения трафика приложений и сети. Эти устройства могут обрабатывать большой объем трафика, но часто имеют значительную цену и относительно ограничены в гибкости.
Аппаратные балансировщики нагрузки включают в себя проприетарное программное обеспечение, которое требует обслуживания и обновлений с выпуском новых версий и патчей безопасности.
DNS
Балансировка нагрузки DNS - это практика настройки домена в системе доменных имен (DNS) таким образом, чтобы запросы клиентов к домену распределялись по группе серверных машин.
К сожалению, у балансировки нагрузки DNS есть врожденные проблемы, ограничивающие ее надежность и эффективность. Самым значимым из них является то, что DNS не проверяет отказы серверов и сетей или ошибки. Он всегда возвращает один и тот же набор IP-адресов для домена, даже если серверы выключены или недоступны.
Routing Algorithms
Теперь давайте обсудим наиболее распространенные алгоритмы маршрутизации:
- Round-robin: Запросы распределяются по приложениям в циклическом порядке.
- Weighted Round-robin: Основан на простом методе Round-robin и учитывает различные характеристики серверов, такие как вычислительная мощность и обработка трафика, с использованием весов, которые могут быть назначены администратором через записи DNS.
- Least Connections: Новый запрос отправляется на сервер с наименьшим текущим количеством соединений с клиентами. Относительная вычислительная мощность каждого сервера учитывается при определении того, у кого меньше всего соединений.
- Least Response Time: Отправляет запросы на сервер, выбранный формулой, которая объединяет самое быстрое время ответа и наименьшее количество активных соединений.
- Least Bandwidth: Этот метод измеряет трафик в мегабитах в секунду (Mbps) и отправляет запросы клиентов на сервер с наименьшим количеством Mbps трафика.
- Hashing: Распределяет запросы на основе ключа, который мы определяем, такого как IP-адрес клиента или URL запроса.
Преимущества
Балансировка нагрузки также играет ключевую роль в предотвращении простоев, другие преимущества балансировки нагрузки включают в себя следующее:
- Масштабируемость
- Отказоустойчивость
- Гибкость
- Эффективность
Резервные балансировщики нагрузки
Как вы, возможно, уже догадались, сам балансировщик нагрузки может быть единственной точкой отказа. Для преодоления этого может использоваться второй или N количество балансировщиков нагрузки в режиме кластера.
И, если обнаруживается сбой и активный балансировщик нагрузки выходит из строя, другой пассивный балансировщик нагрузки может взять на себя его функции, что сделает нашу систему более устойчивой к отказам.
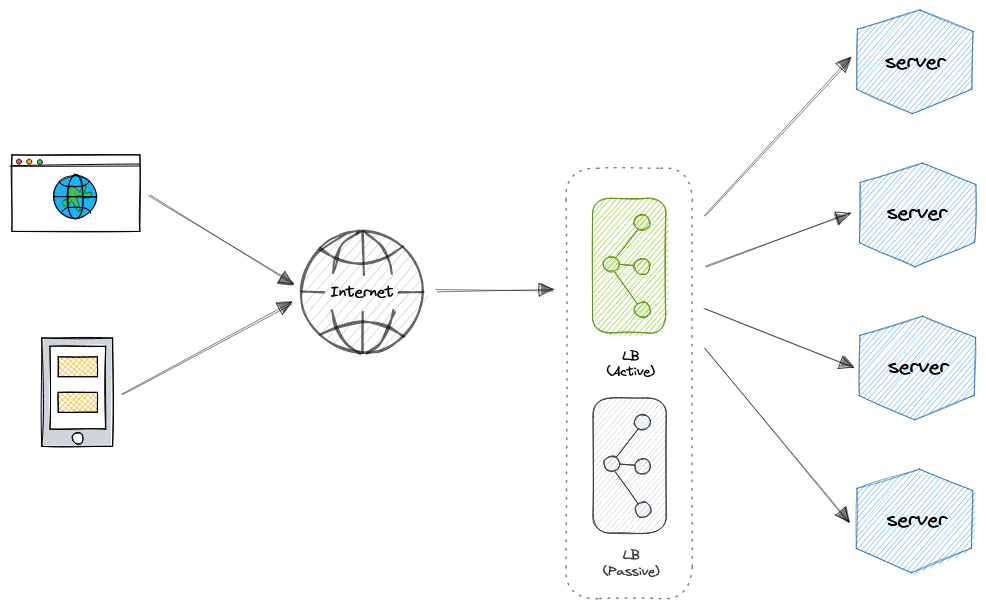
Features
Вот некоторые распространенные желаемые функции балансировщиков нагрузки:
- Автомасштабирование: Запуск и выключение ресурсов в зависимости от условий спроса.
- Клейкие сессии: Возможность назначить тот же пользовательский или устройственный ресурс тому же ресурсу для поддержания состояния сеанса на ресурсе.
- Проверка состояния: Возможность определить, отключен ли ресурс или работает плохо, чтобы удалить ресурс из пула балансировки нагрузки.
- Устойчивые соединения: Разрешение серверу открывать постоянное соединение с клиентом, такое как WebSocket.
- Шифрование: Обработка зашифрованных соединений, таких как TLS и SSL.
- Сертификаты: Предоставление клиенту сертификатов и аутентификация клиентских сертификатов.
- Сжатие: Сжатие ответов.
- Кэширование: Балансировщик нагрузки на уровне приложения может предлагать возможность кэшировать ответы.
- Логирование: Логирование метаданных запроса и ответа может служить важным следом для аудита или источником данных аналитики.
- Трассировка запросов: Присвоение каждому запросу уникального идентификатора для целей логирования, мониторинга и устранения неполадок.
- Перенаправления: Возможность перенаправления входящего запроса на основе таких факторов, как запрошенный путь.
- Фиксированный ответ: Возврат статического ответа на запрос, такого как сообщение об ошибке.
Примеры
Ниже приведены некоторые часто используемые в IT-индустрии балансировщики:
- Amazon Elastic Load Balancing
- Azure Load Balancing
- GCP Load Balancing
- DigitalOcean Load Balancer
- Nginx
- HAProxy
Кластеризация
На более высоком уровне компьютерный кластер представляет собой группу из двух или более компьютеров, или узлов, которые работают параллельно для достижения общей цели. Это позволяет распределить рабочие нагрузки, состоящие из большого количества индивидуальных, параллелизуемых задач, между узлами в кластере. В результате эти задачи могут использовать объединенную память и вычислительную мощность каждого компьютера для повышения общей производительности.
Для создания компьютерного кластера каждый отдельный узел должен быть подключен к сети для обеспечения межузлового взаимодействия. Затем программное обеспечение может быть использовано для объединения узлов и формирования кластера. Возможно, на каждом узле может быть общее устройство хранения и/или локальное хранилище.
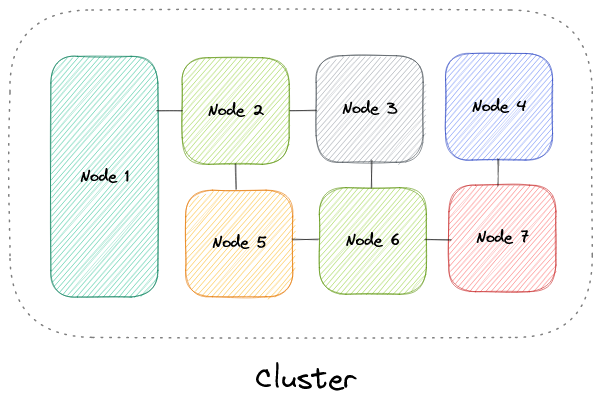
Обычно, как минимум один узел назначается ведущим и действует как точка входа в кластер. Ведущий узел может быть ответственен за делегирование входящей работы другим узлам и, при необходимости, агрегирование результатов и возврат ответа пользователю.
Идеально, кластер функционирует так, как если бы он был единым системным блоком. Пользователь, получающий доступ к кластеру, не должен знать, является ли система кластером или отдельным компьютером. Более того, кластер должен быть спроектирован для минимизации задержек и предотвращения узких мест в межузловом общении.
Типы
Компьютерные кластеры обычно можно классифицировать по трем типам:
- Высокодоступные или с отказоустойчивые
- Балансировка нагрузки
- Высокопроизводительные вычисления
Конфигурации
Два наиболее распространенных варианта конфигурации кластеров с высокой доступностью (HA) - это активный-активный и активный-пассивный.
Активный-активный
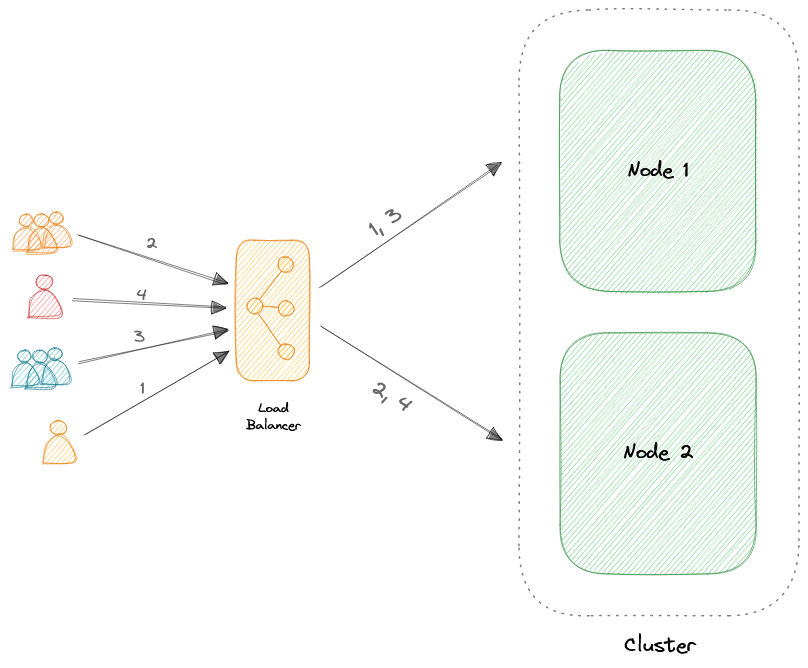
Активно-активный кластер обычно состоит по крайней мере из двух узлов, которые одновременно активно выполняют одинаковый тип сервиса. Основная цель активно-активного кластера - достижение балансировки нагрузки. Балансировщик нагрузки распределяет рабочие нагрузки по всем узлам, чтобы предотвратить перегрузку любого отдельного узла. Поскольку доступно больше узлов для обслуживания, также будет улучшение пропускной способности и времени отклика.
Active-Passive
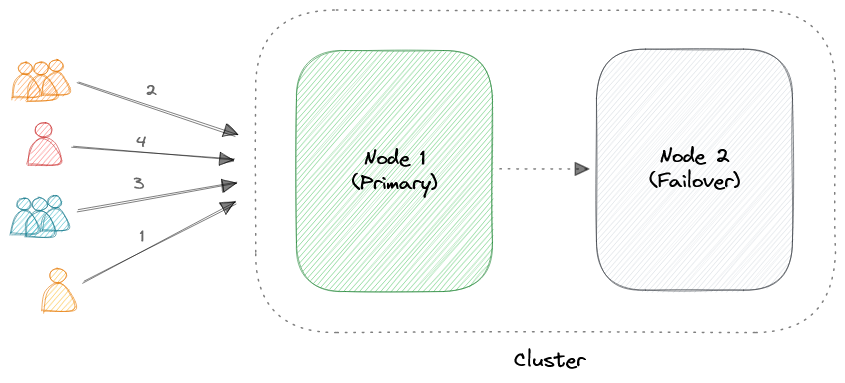
Как и конфигурация кластера активный-активный, кластер активный-пассивный также состоит по крайней мере из двух узлов. Однако, как подразумевает название активный-пассивный, не все узлы будут активными. Например, в случае двух узлов, если первый узел уже активен, то второй узел должен быть пассивным или в режиме ожидания.
Преимущества
Четыре основных преимущества кластерных вычислений следующие:
- Высокая доступность
- Масштабируемость
- Производительность
- Экономическая эффективность
Load balancing vs Clustering
Балансировка нагрузки имеет некоторые общие черты с кластеризацией, но это разные процессы. Кластеризация обеспечивает избыточность, увеличивает мощность и доступность. Серверы в кластере осведомлены друг о друге и работают сообща в рамках общей цели. Но с балансировкой нагрузки серверы не осведомлены друг о друге. Вместо этого они реагируют на запросы, получаемые от балансировщика нагрузки.
Мы можем применять балансировку нагрузки в сочетании с кластеризацией, но она также применима в случаях, когда независимые серверы разделяют общую цель, такую как запуск веб-сайта, бизнес-приложения, веб-сервиса или другого IT-ресурса.
Challenges
Самая очевидная проблема, с которой сталкивается кластеризация - это увеличение сложности установки и обслуживания. Операционная система, приложение и его зависимости должны быть установлены и обновлены на каждом узле.
Это становится еще более сложным, если узлы в кластере неоднородны. Использование ресурсов для каждого узла также должно быть тщательно отслежено, а журналы должны быть агрегированы, чтобы убедиться, что программное обеспечение работает правильно.
Кроме того, управление хранилищем становится более сложным, общее устройство хранения должно предотвращать перезапись узлов друг другом, и распределенные хранилища данных должны быть синхронизированы.
Примеры
Кластеризация широко распространена в IT-индустрии и часто многие технологии и сервисы поддерживают того или иного рода clustering-режим. Например:
- Контейнеры (e.g. Kubernetes, Amazon ECS)
- СУБД (e.g. Cassandra, MongoDB)
- Кэш (e.g. Redis)
Кэширование
"В IT есть только две сложные вещи: инвалидация кэша и вопросы именования." - Phil Karlton

Кэш в первую очередь предназначен для увеличения производительности извлечения данных, сокращая необходимость доступа к более медленному основному уровню хранения. Жертвуя емкостью ради скорости, кэш обычно хранит подмножество данных временно, в отличие от баз данных, данные в которых обычно полные и долговечные.
Кэши используют принцип локальности ссылок "недавно запрошенные данные вероятно будут запрошены снова".
Caching and Memory
Как память компьютера, кэш представляет собой компактную, быстродействующую память, которая хранит данные в иерархии уровней, начиная с уровня один и последовательно продвигаясь оттуда. Они обозначаются как L1, L2, L3 и так далее. Кэш также записывается по запросу, например, когда произошло обновление и новые данные нужно сохранить в кэше, заменяя старые данные, которые были сохранены.
Независимо от того, читается ли или записывается кэш, это происходит блок за блоком. Каждый блок также имеет тег, который содержит местоположение, где данные были сохранены в кэше. Когда данные запрашиваются из кэша, происходит поиск по тегам, чтобы найти конкретный контент, который необходим на уровне один (L1) памяти. Если правильные данные не найдены, производятся дополнительные поиски в L2.
Если данные не найдены там, поиски продолжаются в L3, затем в L4 и так далее, пока они не будут найдены, затем они считываются и загружаются. Если данные вообще не найдены в кэше, они записываются в него для быстрого извлечения в следующий раз.
Cache hit and Cache miss
Cache hit
Cache hit - это ситуация, когда запрашиваемые данные успешно получены из кэша. Теги быстро ищутся в памяти и когда данные найдены и прочитаны это называется cache hit.
Cold, Warm, and Hot Caches
Cache-hit принято характеризовать словами cold, warm или hot для описания скорости, с которой данные считываются.
Горячий кэш - это случай, когда данные были считаны из памяти с максимально возможной скоростью. Это происходит, когда данные извлекаются из L1.
Холодный кэш - это медленнейшая возможная скорость для считывания данных, хотя она все равно успешна, поэтому все равно считается кэш-попаданием. Данные просто находятся ниже в иерархии памяти, такие как в L3 или ниже.
Warm cache - используется для описания данных, которые находятся в L2 или L3. Это не так быстро, как горячий кэш, но все равно быстрее, чем холодный кэш. Обычно называть кэш теплым используется для выражения того, что он медленнее и ближе к холодному кэшу, чем к горячему.
Промах кэша
Промах кэша происходит, когда память проверяется, и данные не находятся. В этом случае содержимое передается и записывается в кэш.
Инвалидация кэша
Инвалидация кэша - это процесс, при котором компьютерная система объявляет записи кэша недействительными и удаляет их или заменяет их. Если данные изменяются, они должны быть инвалидированы в кэше, иначе это может вызвать несогласованное поведение приложения. Существует три вида систем кэширования:
Write-through cache

Данные записываются в кэш и в соответствующую базу данных одновременно.
Плюсы: Быстрое чтение, полная консистентность данных между кэшем и долговременным хранилищем.
Минусы: Большие задержки для операций записи.
Write-around cache

Запросы на запись идут напрямую в базу данных или другое долговременное хранилище в обход кэша.
Плюсы: Может снизить задержки.
Минусы: Приводит к увеличению доли cache misses, а потому кэшу приходится чаще читать из базы данных. Как результат, это может привести к увеличению задержек при операциях чтения для приложений, которые одинаково часто читают и записывают данные. Чтение осуществляется с более медленных источников и с большими задержками.
Write-back cache

Где запись происходит только в кэширующем слое, и подтверждается сразу после завершения записи в кэш. Затем кэш асинхронно синхронизирует эту запись с базой данных.
Преимущества: Это приведет к снижению задержки и высокой пропускной способности для приложений с интенсивной записью.
Недостатки: Существует риск потери данных в случае аварии кэширующего слоя. Мы можем улучшить это, имея более одного репликата, подтверждающего запись в кэше.
Политики вытеснения
Вот некоторые из наиболее распространенных политик вытеснения из кэша:
- Первый вошел - первый вышел (FIFO): Кэш вытесняет первый доступный блок без учета того, как часто или сколько раз он использовался ранее.
- Последний вошел - первый вышел (LIFO): Кэш вытесняет блок, к которому обращались последним, без учета того, как часто или сколько раз он использовался ранее.
- Наименее недавно использованный (LRU): Вытесняет наименее недавно использованные элементы.
- Наиболее недавно использованный (MRU): В отличие от LRU, вытесняет наиболее недавно использованные элементы.
- Наименее часто использованный (LFU): Считает, насколько часто элемент нужен. Те, которые используются реже всего, вытесняются первыми.
- Случайная замена (RR): Случайным образом выбирает кандидата и вытесняет его, чтобы освободить место, когда это необходимо.
Distributed Cache
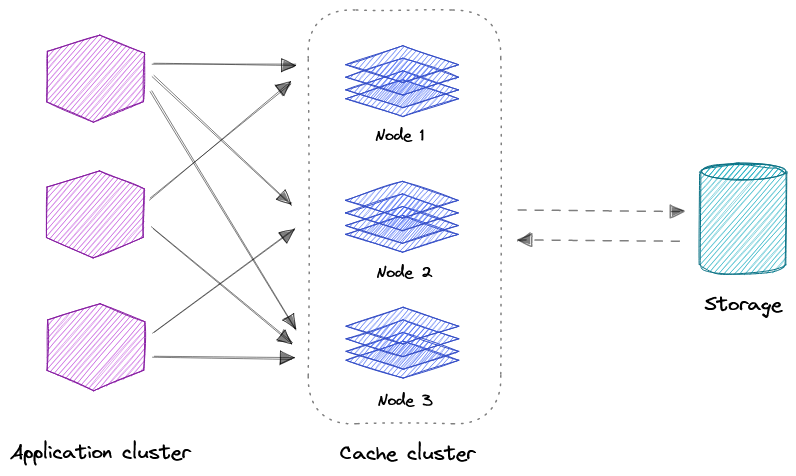
Распределенный кэш - это система, которая объединяет оперативную память (RAM) нескольких компьютеров в сети в единую память данных, используемую в качестве кэша данных для быстрого доступа к данным. В то время как большинство кэшей традиционно находятся на одном физическом сервере или аппаратном компоненте, распределенный кэш может превысить ограничения по памяти одного компьютера, объединяя несколько компьютеров.
Global Cache
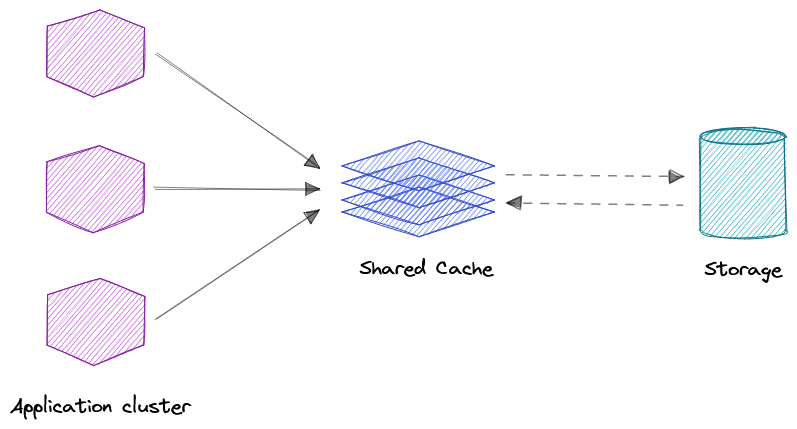
Как следует из названия здесь мы имеем один общий кэш, который используют все ноды приложения. Если запрашиваемые данные в глобальном кэше не найдены, то ответственность самого кэша получить отсутствующий кусок данных из стоящего за ним хранилища данных.
Применение
Кэширование может иметь множество практических применений, таких как:
- Кэширование баз данных
- Сеть доставки контента (CDN)
- Кэширование системы доменных имен (DNS)
- Кэширование API
Когда не использовать кэширование?
Давайте также рассмотрим некоторые сценарии, когда не следует использовать кэш:
- Кэширование бесполезно, когда доступ к кэшу занимает столько же времени, сколько доступ к основному источнику данных.
- Кэширование работает не так хорошо, когда запросы имеют низкую повторяемость (большую случайность), потому что производительность кэширования зависит от повторяющихся шаблонов доступа к памяти.
- Кэширование неэффективно, когда данные часто изменяются, поскольку кэшированная версия становится несогласованной, и основной источник данных должен быть доступен каждый раз.
Преимущества
Вот некоторые преимущества кэширования:
- Улучшает производительность
- Сокращает задержку
- Уменьшает нагрузку на базу данных
- Сокращает сетевые затраты
- Увеличивает пропускную способность чтения
Examples
Вот список некоторых популярных систем, использующихся для кэширования:
Content Delivery Network (CDN)
Content delivery network (CDN) - это географически распределенная группа серверов, работающих совместно для наиболее быстрой доставки интернет контента пользователю. Обычно посредством CDN клиент получает статические файлы: HTML/CSS/JS, картинки, видео.
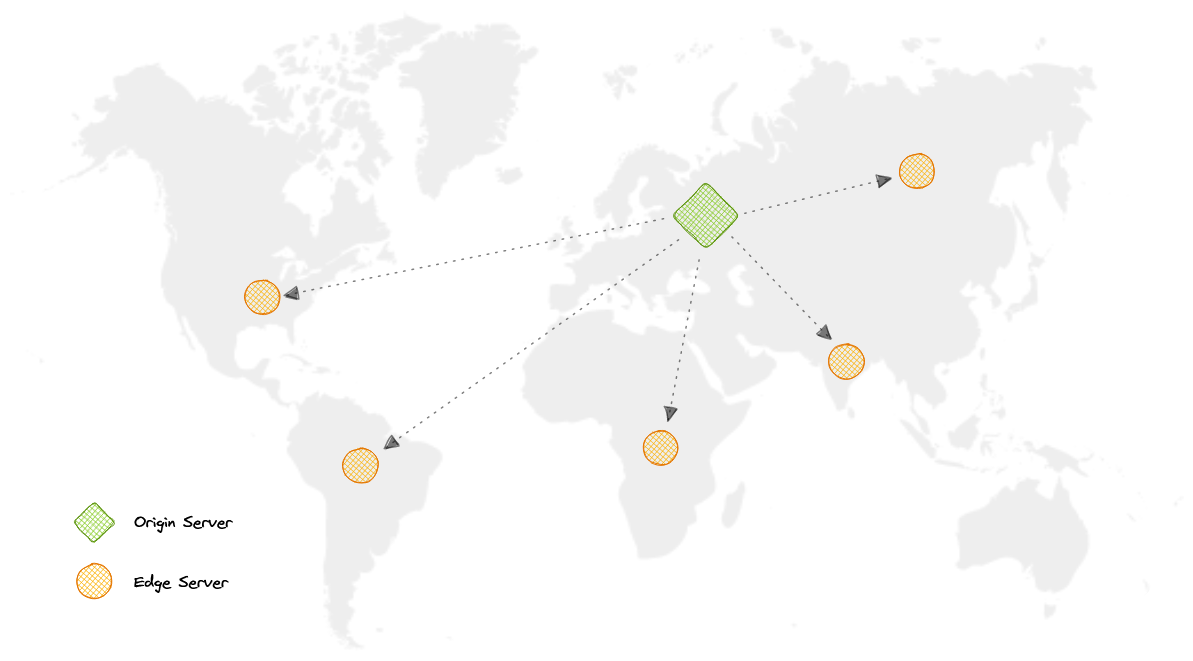
Why use a CDN?
Content Delivery Network (CDN) повышает доступность и избыточность ресурсов, одновременно снижая затраты на трафик и улучшая безопасность. Предоставляя контент через CDN можно значительно повысить скорость, поскольку пользователи будут получать ресурсы из дата-центров, расположенных рядом и одновременно наши сервера освободятся от части нагрузки.
How does a CDN work?
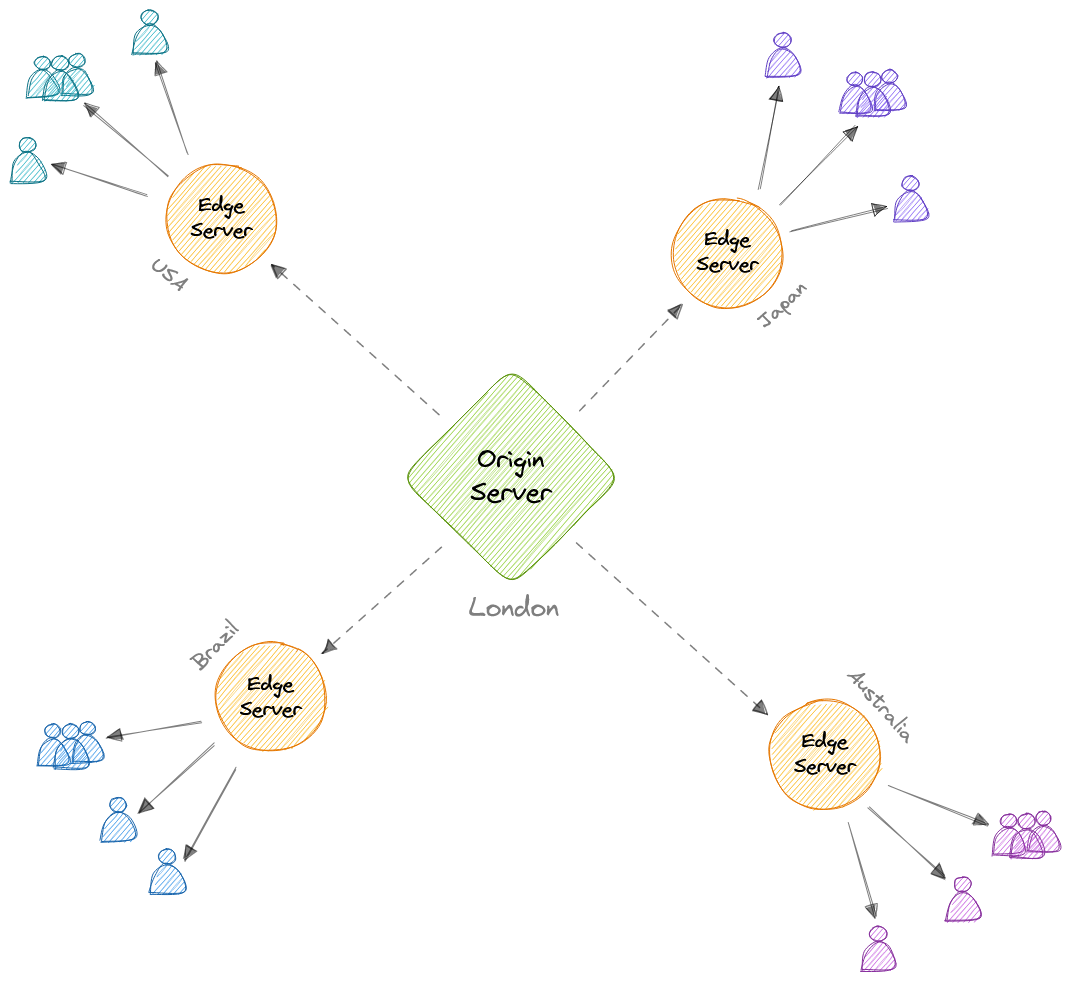
В CDN (сети доставки контента) исходный сервер содержит оригинальные версии контента, в то время как краевые серверы представлены множеством и распределены по различным местоположениям по всему миру.
Для минимизации расстояния между посетителями и сервером веб-сайта CDN хранит кэшированную версию своего контента в нескольких географических точках, известных как краевые местоположения. Каждое краевое местоположение содержит несколько кэширующих серверов, ответственных за доставку контента посетителям в своей близости.
Как только статические ресурсы кэшированы на всех серверах CDN для определенного местоположения, все последующие запросы посетителей веб-сайта к статическим ресурсам будут обслуживаться с этих краевых серверов, а не с источника, тем самым уменьшая нагрузку на источник и повышая масштабируемость.
Например, когда кто-то в Великобритании запрашивает наш веб-сайт, который может быть размещен в США, он будет обслуживаться из ближайшего краевого местоположения, такого как Лондонское краевое местоположение. Это намного быстрее, чем полный запрос к исходному серверу, что сокращает задержку.
Types
CDNs сервисы в целом делятся на два типа:
Push CDNs
Push CDN'ы получают новый контент при каждом изменении на сервере. Мы полностью отвечаем за предоставление контента, загрузку напрямую в CDN и изменение URL-адресов, чтобы они указывали на CDN. Мы можем настраивать срок действия контента и время его обновления. Контент загружается только тогда, когда он новый или измененный, минимизируя трафик, но максимизируя использование хранилища.
Сайты с небольшим количеством трафика или сайты с контентом, который не часто обновляется, хорошо работают с push CDN. Контент размещается на CDN только один раз, вместо того чтобы быть периодически запрашиваемым.
Pull CDNs
В случае Pull CDN кэш обновляется на основе запроса. Когда клиент отправляет запрос, требующий получения статических ресурсов из CDN, если их нет в CDN, то он будет получать вновь обновленные ресурсы из исходного сервера и заполнять свой кэш этими новыми ресурсами, а затем отправлять эти новые кэшированные ресурсы пользователю.
В отличие от Push CDN, это требует меньше обслуживания, потому что обновления кэша на узлах CDN выполняются на основе запросов клиента к исходному серверу. Сайты с высоким трафиком хорошо работают с Pull CDN, поскольку трафик более равномерно распределен, и на CDN остается только недавно запрошенный контент.
Недостатки
Как мы все знаем, хорошие вещи приносят дополнительные расходы, поэтому давайте обсудим некоторые недостатки CDN:
- Дополнительные расходы: Использование CDN может быть дорогим, особенно для сервисов с высоким трафиком.
- Ограничения: Некоторые организации и страны заблокировали домены или IP-адреса популярных CDN.
- Местоположение: Если большинство нашей аудитории находится в стране, где у CDN нет серверов, данные на нашем веб-сайте могут приходиться проходить большее расстояние, чем без использования какого-либо CDN.
Примеры
Вот несколько широко используемых CDN:
Прокси
Прокси-сервер - это посредник, являющийся промежуточным аппаратным или программным обеспечением между клиентом и сервером. Он получает запросы от клиентов и передает их на исходные серверы. Обычно прокси используются для фильтрации запросов, регистрации запросов или иногда трансформации запросов (добавление/удаление заголовков, шифрование/дешифрование или сжатие).
Types
Существуют два типа прокси:
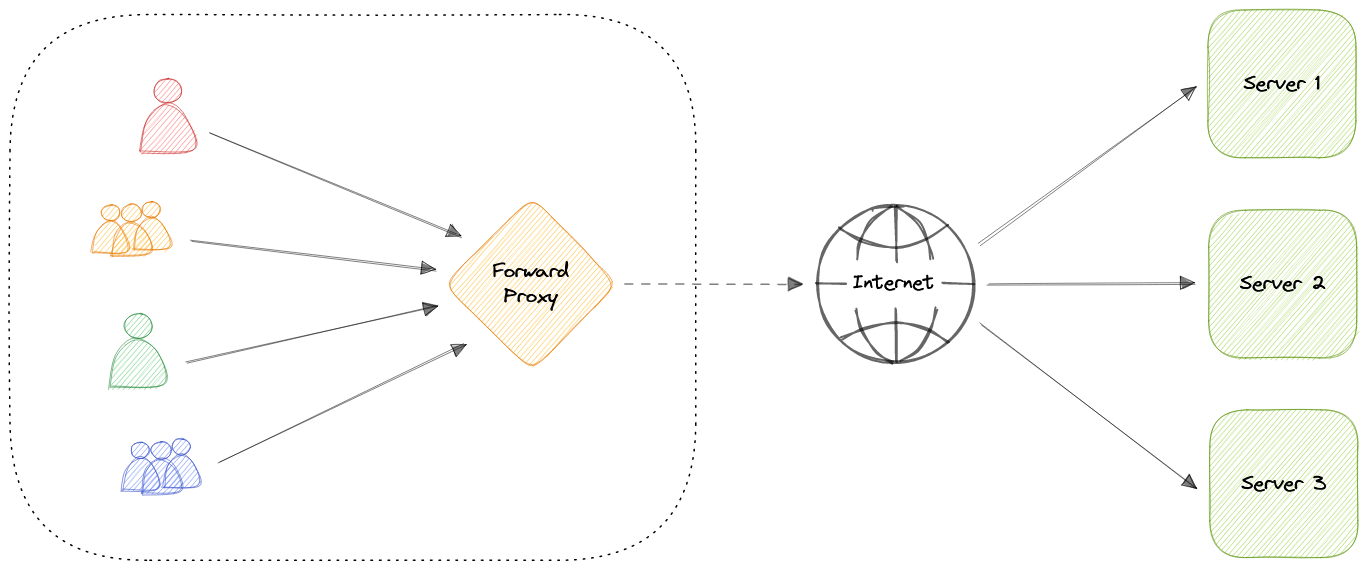
Forward Proxy
Прямой прокси, часто называемый просто прокси или прокси сервер или веб-прокси - это сервер, который расположен перед определенными клиентскими машинами. Когда с этих компьютеров делаются запросы к сайтам и сервисам в интернете, прокси сервер перехватывает эти запросы и затем взаимодействует с веб-серверами от имени этих клиентов, как посредник (middleman).
Преимущества
Вот некоторые преимущества прокси-сервера:
- Блокировка доступа к определенному контенту
- Позволяет получать доступ к ограниченному географически контенту
- Обеспечивает анонимность
- Избегает других ограничений в интернете
Хотя прокси обеспечивают анонимность, они всё ещё могут отслеживать наши личные данные. Установка и обслуживание прокси-сервера могут быть дорогостоящими и требуют конфигураций.
Reverse Proxy
Обратный прокси-сервер - это сервер, который находится перед одним или несколькими веб-серверами и перехватывает запросы от клиентов. Когда клиенты отправляют запросы на исходный сервер веб-сайта, эти запросы перехватываются обратным прокси-сервером.
Разница между прямым и обратным прокси-серверами незначительна, но важна. Упрощенным способом описания этой разницы можно назвать то, что прямой прокси-сервер находится перед клиентом и гарантирует, что ни один исходный сервер никогда не общается напрямую с этим конкретным клиентом. С другой стороны, обратный прокси-сервер находится перед исходным сервером и гарантирует, что ни один клиент никогда не общается напрямую с этим исходным сервером.
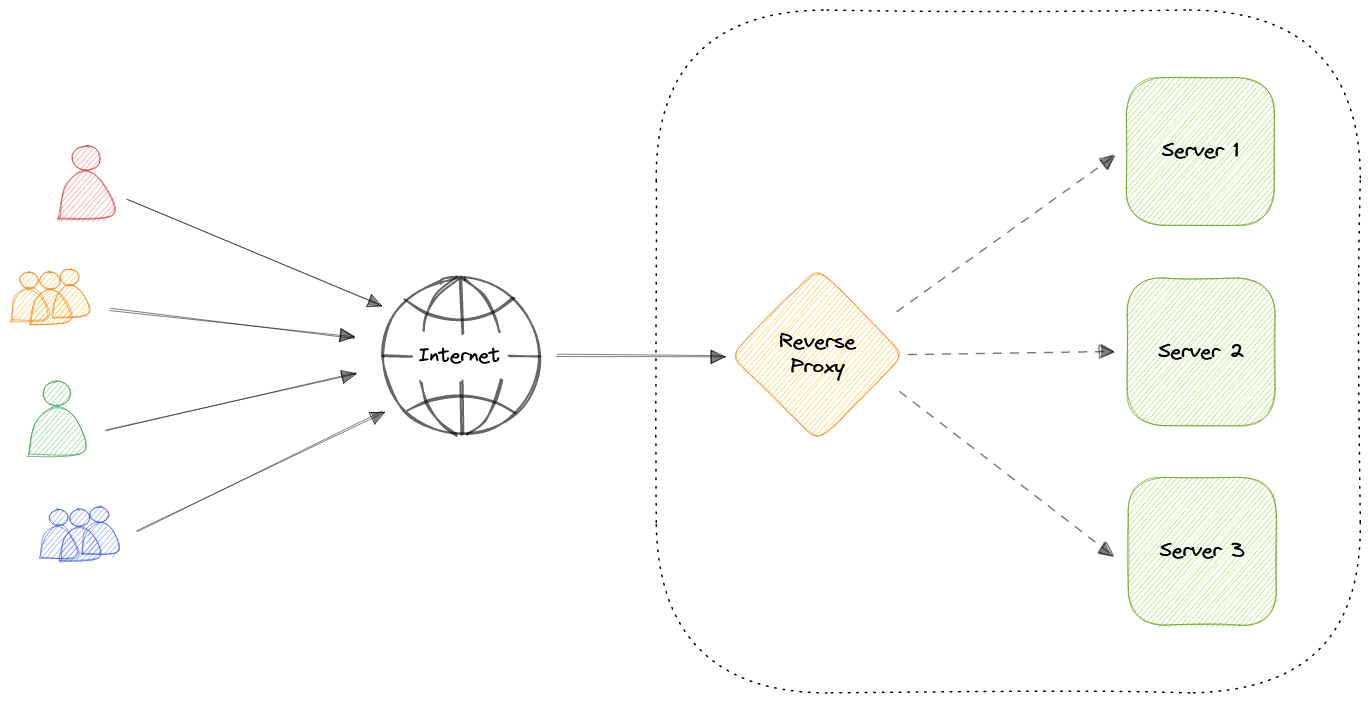
Внедрение обратного прокси приводит к увеличению сложности. Одиночный обратный прокси является единой точкой отказа, настройка нескольких обратных прокси (т.е. резервирование) еще более увеличивает сложность.
Преимущества
Вот некоторые преимущества использования обратного прокси:
- Улучшенная безопасность
- Кэширование
- Шифрование SSL
- Балансировка нагрузки
- Масштабируемость и гибкость
Балансировщик vs Обратный прокси
Подождите, разве обратный прокси похож на балансировщик нагрузки? Ну, нет, так как балансировщик нагрузки полезен, когда у нас есть несколько серверов. Часто балансировщики направляют трафик на набор серверов, выполняющих одну и ту же функцию, в то время как обратные прокси могут быть полезны даже с одним веб-сервером или сервером приложений. Обратный прокси также может действовать как балансировщик нагрузки, но не наоборот.
Да, вы правы! Хотя как обратные прокси, так и балансировщики нагрузки могут находиться между клиентами и серверами, они выполняют разные функции.
Балансировщик нагрузки в первую очередь используется для распределения входящих запросов клиентов по нескольким серверам, чтобы гарантировать, что ни один сервер не перегружен, тем самым улучшая надежность и масштабируемость. Он особенно полезен в условиях высокого трафика, когда несколько серверов выполняют одну и ту же функцию.
С другой стороны, обратный прокси сосредоточен на перехвате запросов клиентов и их пересылке на сервера внутри сети. Он часто используется для повышения безопасности, улучшения производительности и предоставления дополнительных функций, таких как кэширование и завершение SSL. Обратный прокси также может действовать как балансировщик нагрузки, распределяя запросы между несколькими серверами, но его функциональность превосходит простое балансирование нагрузки.
Таким образом, хотя обратный прокси может выполнять роль балансировщика нагрузки, балансировщик нагрузки не может выполнять все функции обратного прокси.
Примеры
Ниже приведены некоторые популярные прокси решения:
Доступность сервисов
Доступность - это время, в течение которого система остается работоспособной для выполнения своих функций в определенный период. Это простая мера процента времени, в течение которого система, сервис или устройство остается работоспособным в нормальных условиях.
Девятки доступности
Доступность часто количественно измеряется как время безотказной работы (или простой) в процентах от времени доступности службы. Обычно измеряется в количестве 9.
$$ Доступность = \frac{Время \space безотказной \space работы}{(Время \space безотказной \space работы + Время \space простоя)} $$
Если доступность составляет 99,00%, говорят о "2 девятках" доступности, и если это 99,9%, то говорят о "3 девятках" и так далее.
| Доступность (Проценты) | Простой (Год) | Простой (Месяц) | Простой (Неделя) |
|---|---|---|---|
| 90% (одна девятка) | 36.53 дня | 72 часа | 16.8 часа |
| 99% (две девятки) | 3.65 дня | 7.20 часа | 1.68 часа |
| 99.9% (три девятки) | 8.77 часа | 43.8 минуты | 10.1 минута |
| 99.99% (четыре девятки) | 52.6 минуты | 4.32 минуты | 1.01 минута |
| 99.999% (пять девяток) | 5.25 минуты | 25.9 секунды | 6.05 секунд |
| 99.9999% (шесть девяток) | 31.56 секунд | 2.59 секунд | 604.8 миллисекунд |
| 99.99999% (семь девяток) | 3.15 секунд | 263 миллисекунд | 60.5 миллисекунд |
| 99.999999% (восемь девяток) | 315.6 миллисекунд | 26.3 миллисекунд | 6 миллисекунд |
| 99.9999999% (девять девяток) | 31.6 миллисекунд | 2.6 миллисекунды | 0.6 миллисекунд |
Доступность в последовательном и параллельном исполнении
Если сервис состоит из нескольких компонентов, подверженных отказам, общая доступность сервиса зависит от того, находятся ли компоненты в последовательности или в параллели.
Последовательное исполнение
Общая доступность уменьшается, когда два компонента находятся в последовательности.
$$ Доступность \space (Общая) = Доступность \space (Foo) * Доступность \space (Bar) $$
Например, если у обоих Foo и Bar каждый имеет доступность 99.9%, их общая доступность в последовательности составит 99.8%.
Параллельное исполнение
Общая доступность увеличивается, когда два компонента находятся в параллели.
$$ Доступность \space (Общая) = 1 - (1 - Доступность \space (Foo)) * (1 - Доступность \space (Bar)) $$
Например, если у обоих Foo и Bar каждый имеет доступность 99.9%, их общая доступность в параллели составит 99.9999%.
Доступность против Надежности
Если система надежна, она доступна. Однако, если она доступна, это не обязательно означает, что она надежна. Другими словами, высокая надежность способствует высокой доступности, но возможно достичь высокой доступности даже с ненадежной системой.
Высокая доступность против Устойчивости к сбоям
И высокая доступность, и устойчивость к сбоям применяются для обеспечения высокого уровня времени безотказной работы. Однако они достигают цели по-разному.
Устойчивая к сбоям система не имеет прерывания обслуживания, но требует значительно более высоких затрат, в то время как высокодоступная система имеет минимальные перерывы в обслуживании. Для обеспечения устойчивости к сбоям требуется полная аппаратная избыточность, так как при отказе основной системы без потери времени безотказной работы должна вступить в действие другая система.
Масштабируемость
Масштабируемость - это мера того, насколько хорошо система реагирует на изменения, добавляя или удаляя ресурсы для удовлетворения требований.
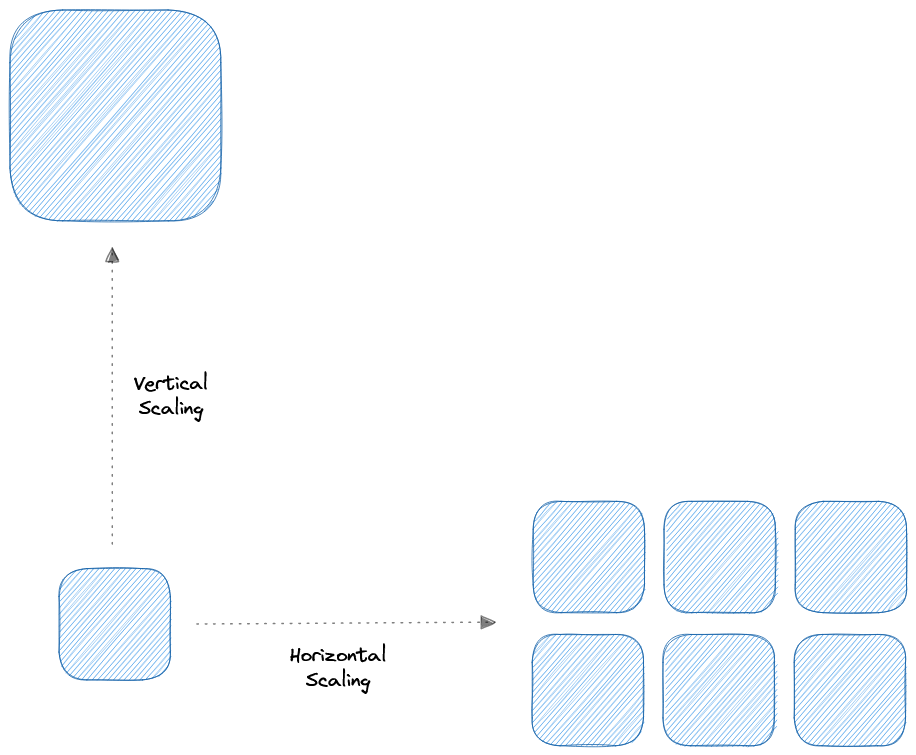
Горизонтальное масштабирование
Горизонтальное масштабирование (также известное как масштабирование вверх) расширяет масштабируемость системы путем добавления большей мощности к существующему компьютеру. Другими словами, горизонтальное масштабирование означает улучшение возможностей приложения путем увеличения мощности оборудования.
Преимущества
- Прост в реализации
- Легче управлять
- Данные согласованы
Недостатки
- Риск высокого времени простоя
- Труднее обновить
- Может быть единой точкой отказа
Вертикальное масштабирование
Вертикальное масштабирование (также известное как масштабирование вниз) расширяет масштаб системы путем добавления большего количества машин. Оно улучшает производительность сервера путем добавления большего количества экземпляров к существующему пулу серверов, позволяя более равномерно распределить нагрузку.
Преимущества
- Увеличенная избыточность
- Лучшая устойчивость к отказам
- Гибкость и эффективность
- Более простое обновление
Недостатки
- Увеличенная сложность
- Несогласованность данных
- Увеличенная нагрузка на службы нижнего уровня
Хранилище данных
Хранение - это механизм, позволяющий системе сохранять данные, как временно, так и постоянно. Эта тема часто пропускается в контексте проектирования системы, однако важно иметь базовое понимание некоторых общих типов техник хранения, которые могут помочь нам настроить наши хранилища более эффективно. Давайте обсудим некоторые важные концепции хранения:
RAID
RAID (Redundant Array of Independent Disks) - это способ сохранения одних и тех же данных на нескольких жестких дисках или твердотельных накопителях (SSD) для защиты данных в случае отказа диска.
Существуют разные уровни RAID, и не все из них имеют цель обеспечить избыточность. Давайте обсудим некоторые часто используемые уровни RAID:
- RAID 0: Также известный как разделение на полосы, данные равномерно разбиваются на все диски в массиве.
- RAID 1: Также известный как зеркалирование, по крайней мере, два диска содержат точную копию набора данных. Если один диск выходит из строя, другие продолжат работу.
- RAID 5: Разделение с четностию. Требует использования как минимум 3 дисков, разделение данных на несколько дисков, как RAID 0, но также имеет четность, распределенную по дискам.
- RAID 6: Разделение с двойной четностью. RAID 6 похож на RAID 5, но данные о четности записываются на два диска.
- RAID 10: Комбинирует разделение на полосы и зеркалирование из RAID 0 и RAID 1. Обеспечивает безопасность путем зеркалирования всех данных на вторичных дисках и одновременного разделения на каждый набор дисков для ускорения передачи данных.
Сравнение
Давайте сравним все особенности различных уровней RAID:
| Характеристики | RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 |
|---|---|---|---|---|---|
| Описание | Полосование | Зеркалирование | Полосование с четности | Полосование с двойной четностью | Полосование и зеркалирование |
| Минимальное количество дисков | 2 | 2 | 3 | 4 | 4 |
| Производительность чтения | Высокая | Высокая | Высокая | Высокая | Высокая |
| Производительность записи | Высокая | Средняя | Высокая | Высокая | Средняя |
| Стоимость | Низкая | Высокая | Низкая | Низкая | Высокая |
| Устойчивость к отказам | Нет | Отказ одного диска | Отказ одного диска | Отказ двух дисков | До одного отказа диска в каждом подмассиве |
| Использование емкости | 100% | 50% | 67%-94% | 50%-80% | 50% |
Тома
Том - это фиксированный объем хранения на диске или ленте. Термин "том" часто используется как синоним для самого хранилища, но возможно, что один диск содержит более одного тома, или том может охватывать более одного диска.
File storage
Хранилище файлов - это решение для хранения данных в виде файлов и представления их конечным пользователям в виде иерархической структуры каталогов. Основное преимущество заключается в том, что это предоставляет простое в использовании решение для хранения и извлечения файлов. Для поиска файла в файловом хранилище требуется полный путь к файлу. Это экономично и легко структурировано и обычно находится на жестких дисках, что означает, что для пользователя и на самом диске оно выглядит одинаково.
Example: Amazon EFS, Azure files, Google Cloud Filestore, etc.
Block storage
Блочное хранилище делит данные на блоки (части) и хранит их как отдельные элементы. Каждому блоку данных присваивается уникальный идентификатор, что позволяет системе хранения размещать меньшие части данных там, где это наиболее удобно.
Блочное хранилище также отделяет данные от сред пользователей, что позволяет данным распределяться по нескольким средам. Это создает несколько путей к данным и позволяет пользователю быстро их извлекать. Когда пользователь или приложение запрашивает данные из блочной системы хранения, подлежащая система хранения собирает блоки данных и представляет данные пользователю или приложению.
Example: Amazon EBS.
Object Storage
Object storage - также известный как object-based storage, разбивает файлы на части, называемые объектами. И затем эти объекты хранятся в едином репозитории, которое может быть распределено по разным сетевым системам.
Пример: Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
NAS
NAS (Network Attached Storage) - это устройство хранения данных, подключенное к сети, которое позволяет хранить и извлекать данные из центрального местоположения для авторизованных пользователей сети. Устройства NAS гибкие, что означает, что по мере необходимости дополнительного хранилища мы можем добавлять к тому, что у нас уже есть. Они быстрее, менее затратны и обеспечивают все преимущества общедоступного облака на месте, предоставляя нам полный контроль.
HDFS
Hadoop Distributed File System (HDFS) - это распределенная файловая система, предназначенная для работы на оборудовании стандартного класса. HDFS обладает высокой стойкостью к отказам и спроектирована для развертывания на недорогом оборудовании. Она обеспечивает высокую пропускную способность доступа к данным приложений и подходит для приложений с большими объемами данных. У HDFS много сходств с существующими распределенными файловыми системами.
HDFS спроектирована для надежного хранения очень больших файлов на машинах в больших кластерах. Она хранит каждый файл как последовательность блоков, причем все блоки в файле, кроме последнего блока, имеют одинаковый размер. Блоки файла реплицируются для обеспечения устойчивости к отказам.
Базы данных и СУБД
Что такое база данных?
База данных - это организованная коллекция структурированной информации, или данных, обычно хранящаяся электронно в компьютерной системе. База данных обычно управляется Системой Управления Базами Данных (СУБД). Вместе данные и СУБД, а также связанные с ними приложения, называются базовой системой, часто сокращенно называемой просто базой данных.
Что такое СУБД?
Для работы с базой данных обычно требуется комплексная программа для работы с базами данных, известная как Система Управления Базами Данных (СУБД). СУБД служит интерфейсом между базой данных и ее конечными пользователями или программами, позволяя пользователям извлекать, обновлять и управлять организацией и оптимизацией информации. СУБД также облегчает наблюдение и контроль за базами данных, обеспечивая различные административные операции, такие как мониторинг производительности, настройка и резервное копирование и восстановление.
Компоненты
Вот некоторые общие компоненты, присутствующие в различных базах данных:
Схема
Роль схемы состоит в определении формы структуры данных и указании, какие виды данных могут располагаться где. Схемы могут быть строго применяемыми ко всей базе данных, слабо применяемыми к части базы данных или вообще отсутствовать.
Таблица
Каждая таблица содержит различные столбцы, как в электронной таблице. Таблица может иметь как два столбца, так и сто или более столбцов, в зависимости от вида информации, размещаемой в таблице.
Столбец
Столбец содержит набор значений определенного типа, одно значение для каждой строки базы данных. Столбец может содержать текстовые значения, числа, перечисления, временные метки и т. д.
Строка
Данные в таблице записываются в строках. В таблице может быть тысячи или миллионы строк с какой-либо определенной информацией.
Types

Ниже приведены различные типы баз данных:
SQL и NoSQL базы данных это большие темы, которые будут рассмотрены отдельно в разделах SQL базы данных и NoSQL базы данных. Узнай, чем они отличаются друг от друга в разделе SQL vs NoSQL databases.
Проблемы
Некоторые распространенные проблемы, с которыми сталкиваются при работе с базами данных в масштабе:
- Поглощение значительного увеличения объема данных: Взрыв данных, поступающих от датчиков, подключенных машин и десятков других источников.
- Обеспечение безопасности данных: Взломы данных происходят повсюду в наши дни, и сейчас важнее, чем когда-либо, обеспечить безопасность данных, но при этом обеспечить их легкий доступ для пользователей.
- Справление с ростом спроса: Компаниям необходим доступ к данным в реальном времени для поддержки своевременного принятия решений и использования новых возможностей.
- Управление и поддержка базы данных и инфраструктуры: Поскольку базы данных становятся более сложными, а объемы данных растут, компании сталкиваются с расходами на привлечение дополнительных кадров для управления их базами данных.
- Устранение ограничений масштабируемости: Бизнес должен расти, чтобы выжить, и его управление данными должно расти вместе с ним. Однако очень сложно предсказать, сколько мощности потребуется компании, особенно с базами данных на собственных серверах.
- Обеспечение требований к местоположению данных, суверенитету данных или требованиям к задержке: Некоторые организации имеют использование, которые лучше всего подходят для выполнения на собственных серверах. В таких случаях идеальными являются инженерные системы, предварительно настроенные и предварительно оптимизированные для выполнения базы данных.
SQL
Реляционная база данных (SQL) - это набор данных с заранее определенными отношениями между ними. Эти данные организованы в виде набора таблиц с колонками и строками. Таблицы используются для хранения информации об объектах, представленных в базе данных. Каждая колонка в таблице содержит определенный тип данных, а поле хранит фактическое значение атрибута. Строки в таблице представляют собой набор связанных значений одного объекта или сущности.
Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, и строки между несколькими таблицами могут быть связаны с использованием внешних ключей. Эти данные могут быть доступны различными способами, не изменяя сами таблицы базы данных. Базы данных SQL обычно следуют модели согласованности ACID consistency model.
Материлизованные представления
Материализованное представление - это предварительно вычисленный набор данных, полученный из спецификации запроса и сохраненный для последующего использования. Поскольку данные предварительно вычислены, выполнение запроса к материализованному представлению происходит быстрее, чем выполнение запроса к базовой таблице вида. Это различие в производительности может быть значительным, когда запрос выполняется часто или достаточно сложен.
Он также позволяет подмножества данных и улучшает производительность сложных запросов, выполняемых на больших объемах данных, что уменьшает нагрузку на сеть. Существуют и другие способы использования материализованных представлений, но они в основном используются для повышения производительности и репликации.
N+1 query problem
Проблема запроса N+1 возникает, когда слой доступа к данным выполняет N дополнительных SQL-запросов для извлечения тех же данных, которые могли быть получены при выполнении первичного SQL-запроса. Чем больше значение N, тем больше запросов будет выполнено, тем больше будет влияние на производительность.
Это часто наблюдается в GraphQL и инструментах ORM (отображение объектно-реляционной модели), и может быть решено путем оптимизации SQL-запроса или использования загрузчика данных, который пакетирует последовательные запросы и делает единственный запрос к данным внутри.
Преимущества
Давайте посмотрим на некоторые преимущества использования реляционных баз данных:
- Простота и точность
- Доступность данных
- Консистентность данных
- Гибкость
Недостатки
Ниже приведены недостатки реляционных баз данных:
- Дорогая поддержка (обслуживание)
- Тяжелый процесс модификации схемы
- Проблемы производительности при сложных запросах (join, denormalization, etc.)
- Тяжелый процесс горизонтального масштабирования
Примеры
Вот примеры популярных реляционных баз данных:
NoSQL
NoSQL - это широкая категория баз данных, которые не используют SQL в качестве основного языка доступа к данным. Такие базы данных иногда также называют нереляционными базами данных. В отличие от реляционных баз данных, данные в базе данных NoSQL не обязаны соответствовать предварительно определенной схеме. Базы данных NoSQL следуют модели согласованности BASE.
Ниже приведены различные типы баз данных NoSQL:
Документ
Документоориентированная база данных (также известная как база данных ориентированная на документы или хранилище документов) - это база данных, которая хранит информацию в документах. Они являются универсальными базами данных, которые обслуживают различные сценарии использования как транзакционных, так и аналитических приложений.
Преимущества
- Интуитивно-понятные и гибкие
- Хорошо горизонтально масштабируются
- Отсутствие схемы
Недостатки
- Отсутствие схемы
- Нет реляционных связей
Примеры
Key-value
Преимущества
- Простота и производительность
- Высокая масштабируемость для высоких объемов трафика
- Управление сеансами
- Оптимизированные поиски
Недостатки
- Основные операции CRUD
- Нельзя фильтровать значения
- Отсутствие возможностей индексации и сканирования
- Не оптимизированы для сложных запросов
Примеры
Graph
Графовая база данных - это NoSQL база данных, которая использует графовые структуры для семантических запросов с узлами, ребрами и свойствами для представления и хранения данных вместо таблиц или документов.
Граф связывает элементы данных в хранилище с набором узлов и ребер, ребра представляют отношения между узлами. Отношения позволяют прямо связывать данные в хранилище и, во многих случаях, извлекать их с помощью одной операции.
Преимущества
- Скорость запросов
- Гибкость и адаптивность
- Явное представление данных
Недостатки
- Сложность
- Отсутствие стандартизированного языка запросов
Примеры использования
- Выявление мошенничества
- Рекомендательные системы
- Социальные сети
- Картографирование сети
Примеры
Временные ряды
База данных временных рядов - это база данных, оптимизированная для данных с метками времени или временных рядов.
Преимущества
- Быстрая вставка и извлечение данных
- Эффективное хранение данных
Примеры использования
- Данные Интернета вещей (IoT)
- Анализ метрик
- Мониторинг приложений
- Понимание финансовых тенденций
Примеры
Широкие колонки
Базы данных с широкими колонками, также известные как хранилища с широкими колонками, не имеют схемы данных. Данные хранятся в семействах столбцов, а не в строках и столбцах.
Преимущества
- Высокая масштабируемость, могут обрабатывать петабайты данных
- Идеально подходят для реального времени приложений обработки больших данных
Недостатки
- Дорого
- Увеличенное время записи
Примеры использования
- Бизнес-аналитика
- Хранение данных на основе атрибутов
Примеры
Мульти-модельные
Мульти-модельные базы данных объединяют различные модели баз данных (например, реляционные, графовые, ключ-значение, документы и т. д.) в единое, интегрированное хранилище данных. Это означает, что они могут адаптироваться к различным типам данных, индексам, запросам и хранить данные в более чем одной модели.
Преимущества
- Гибкость
- Подходит для сложных проектов
- Согласованные данные
Недостатки
- Сложность
- Меньшая зрелость
Примеры
SQL vs NoSQL
В мире баз данных существуют два основных типа решений: SQL (реляционные) и NoSQL (нереляционные) базы данных. Оба они отличаются способом, как они были созданы, типом информации, которую они хранят, и способом её хранения. Реляционные базы данных имеют структурированный формат и предопределенные схемы, в то время как нереляционные базы данных являются неструктурированными, распределенными и имеют динамические схемы.
Различия на высоком уровне
Вот несколько основных различий между SQL и NoSQL:
Хранение
SQL хранит данные в таблицах, где каждая строка представляет сущность, а каждый столбец представляет собой точку данных об этой сущности.
Базы данных NoSQL имеют различные модели хранения данных, такие как ключ-значение, граф, документ и т. д.
Схема
В SQL каждая запись соответствует фиксированной схеме, что означает, что столбцы должны быть определены и выбраны до ввода данных, и каждая строка должна содержать данные для каждого столбца. Схему можно изменить позже, но это включает изменение базы данных с использованием миграций.
В то время как в NoSQL схемы динамичны. Поля могут добавляться на лету, и каждая запись (или эквивалент) не обязана содержать данные для каждого поля.
Запросы
SQL-базы данных используют SQL (структурированный язык запросов) для определения и манипулирования данными, что очень мощно.
В базе данных NoSQL запросы сосредоточены на коллекции документов. У различных баз данных разный синтаксис запросов.
Масштабирование
В большинстве обычных ситуаций SQL-базы данных масштабируются вертикально, что может стать очень дорогим. Возможно масштабирование реляционной базы данных на несколько серверов, но это сложный и времязатратный процесс.
С другой стороны, NoSQL-базы данных масштабируются горизонтально, что означает, что мы легко можем добавлять больше серверов к нашей инфраструктуре NoSQL для обработки больших нагрузок. Любое дешевое аппаратное обеспечение или облачные экземпляры могут размещать базы данных NoSQL, что делает процесс намного более экономичным, чем вертикальное масштабирование. Многие технологии NoSQL также автоматически распределяют данные по серверам.
Надежность
Для подавляющего большинства реляционных баз данных характерно соответствие стандарту ACID. Таким образом, когда речь идет о надежности данных и гарантии безопасного выполнения транзакций, SQL-базы данных остаются более надежным выбором.
Большинство решений NoSQL жертвуют соответствием стандарту ACID ради производительности и масштабируемости.
Причины
Как всегда, мы должны выбирать ту технологию, которая лучше соответствует требованиям. Давайте рассмотрим несколько причин для выбора базы данных на основе SQL или NoSQL:
Для SQL
- Структурированные данные с жесткой схемой
- Реляционные данные
- Необходимость в сложных объединениях
- Транзакции
- Поиск по индексу происходит очень быстро
Для NoSQL
- Динамическая или гибкая схема
- Не реляционные данные
- Нет необходимости в сложных объединениях
- Очень интенсивная по данным нагрузка
- Очень высокая пропускная способность для операций ввода/вывода
Репликация баз данных
Репликация - это процесс обмена информацией для обеспечения согласованности между избыточными ресурсами, такими как несколько баз данных, для повышения надежности, отказоустойчивости или доступности.
Репликация мастер-реплика
Мастер обслуживает чтение и запись, реплицируя записи на один или несколько слейвов, которые обслуживают только чтение. Слейвы также могут реплицировать дополнительные слейвы по дереву. Если мастер выходит из строя, система может продолжать работу только в режиме только для чтения, пока слейв не будет повышен до мастера или не будет назначен новый мастер.
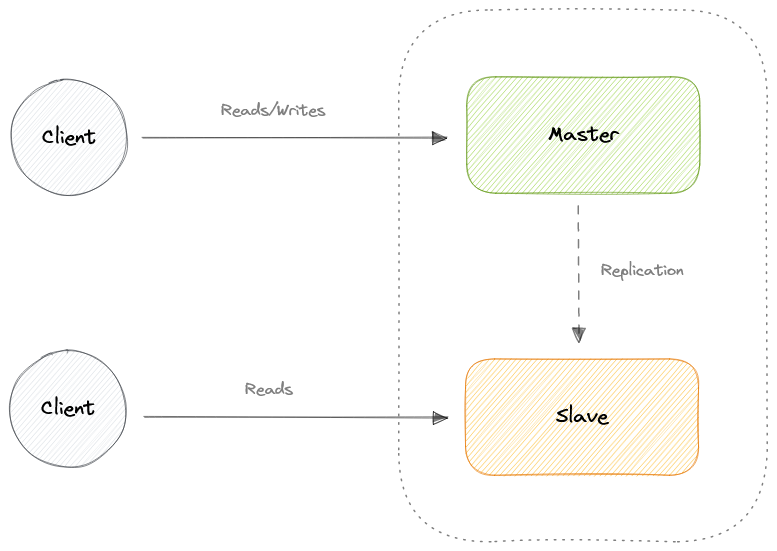
Преимущества
- Резервные копии всей базы данных почти не влияют на основной сервер.
- Приложения могут читать данные с реплик, не влияя на основной сервер.
- Реплики могут быть отключены и синхронизированы обратно с основным сервером без простоя.
Недостатки
- Репликация добавляет больше аппаратных средств и дополнительной сложности.
- Простой и, возможно, потеря данных при отказе основного сервера.
- Вся запись также должна быть сделана на основном сервере в архитектуре мастер-реплика.
- Чем больше реплик для чтения, тем больше нам нужно реплицировать, что приведет к увеличению задержки репликации.
Репликация мастер-мастер
Оба мастера обслуживают чтение/запись и синхронизируются друг с другом. Если отказывается один из мастеров, система может продолжать работать как с чтением, так и с записью.
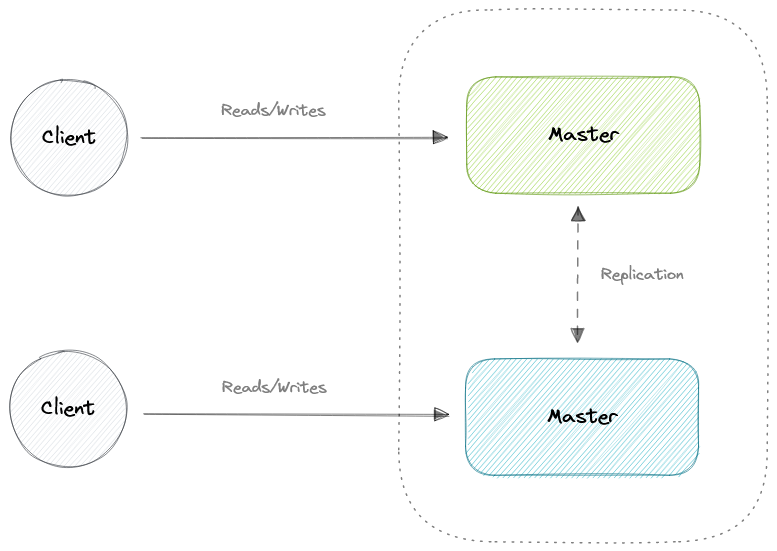
Преимущества
- Приложения могут читать как с первого, так и со второго мастер-узла.
- Распределяет нагрузку на запись между обоими мастер-узлами.
- Простой, автоматический и быстрый переключение на резервный узел.
Недостатки
- Не так просто настраивать и разворачивать, как мастер-слейв.
- Либо большая угроза консистентности данных, либо увеличивается задержка записи из-за синхронизации.
- Появляется проблема разрешения конфликтов по мере добавления дополнительных узлов записи и увеличения задержки.
Synchronous vs Asynchronous replication
Основное различие между синхронным и асинхронным реплицированием заключается в том, как данные записываются на реплику. При синхронном реплицировании данные записываются одновременно на первичное хранилище и на реплику. Таким образом, первичная копия и реплика должны всегда оставаться синхронизированными.
В отличие от этого, при асинхронном реплицировании данные копируются на реплику после того, как данные уже записаны в первичное хранилище. Хотя процесс репликации может происходить почти в реальном времени, более распространено проведение репликации по расписанию, что более экономично.
Индексы
Индексы хорошо известны в контексте баз данных, они используются для улучшения скорости операций по извлечению данных из хранилища данных. Индекс создает компромисс между увеличением накладных расходов на хранение и более медленной записью (поскольку нам необходимо записать данные и обновить индекс) в пользу более быстрых чтений. Индексы используются для быстрого определения местоположения данных без необходимости рассматривать каждую строку в таблице базы данных. Индексы могут быть созданы с использованием одного или нескольких столбцов таблицы базы данных, обеспечивая основу как для быстрого произвольного поиска, так и для эффективного доступа к упорядоченным записям.
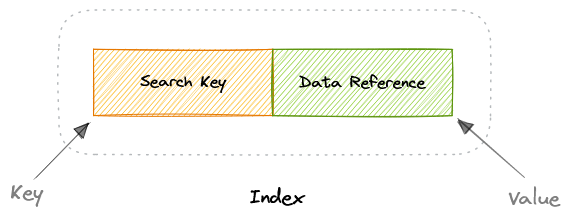
Индекс представляет собой структуру данных, которую можно рассматривать как оглавление, указывающее нам местоположение, где находятся фактические данные. Таким образом, когда мы создаем индекс на столбце таблицы, мы сохраняем этот столбец и указатель на всю строку в индексе. Индексы также используются для создания различных представлений одних и тех же данных. Для больших наборов данных это отличный способ указать различные фильтры или схемы сортировки без необходимости создания нескольких дополнительных копий данных.
Одно из качеств, которым могут обладать индексы баз данных, - это плотность или разреженность. У каждого из этих качеств есть свои компромиссы. Давайте посмотрим, как работает каждый тип индекса:
Dense Index
В плотном индексе - записи индекса создаются для каждой записи таблицы. Записи могут быть получены напрямую, така как в записи индекса помимо ключа поиска содержится указатель на реальную запись.
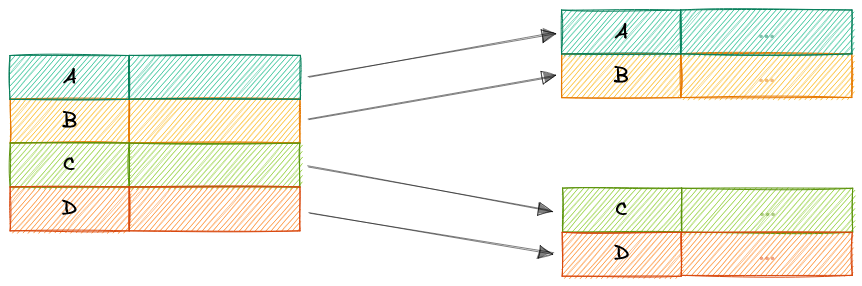
Плотные индексы требуют больше обслуживания по сравнению с разреженными индексами при записи. Поскольку каждая строка должна иметь запись, база данных должна поддерживать индекс при вставках, обновлениях и удалениях. Наличие записи для каждой строки также означает, что плотные индексы будут требовать больше памяти. Преимущество плотного индекса заключается в том, что значения можно быстро найти с помощью простого двоичного поиска. Плотные индексы также не накладывают каких-либо требований на упорядоченность данных.
Sparse Index
В разряженном индексе записи создаются только для некоторых строк таблицы.
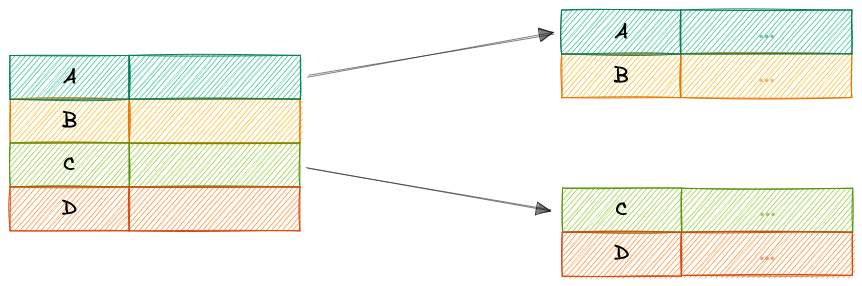
С разреженными индексами процесс обслуживания при записи менее интенсивен, чем у плотных индексов, поскольку они содержат только подмножество значений. Это более легкая нагрузка на обслуживание означает, что вставки, обновления и удаления будут быстрее. Меньшее количество записей также означает, что индекс будет использовать меньше памяти. Поиск данных медленнее, поскольку за двоичным поиском typically следует просмотр страницы. С разреженными индексами также необязательно при работе с упорядоченными данными.
Нормализация и денормализация
Термины
Прежде чем мы продолжим, давайте рассмотрим некоторые часто используемые термины в нормализации и денормализации.
Ключи
Первичный ключ: Столбец или группа столбцов, которые могут быть использованы для уникальной идентификации каждой строки в таблице.
Композитный ключ: Первичный ключ, состоящий из нескольких столбцов.
Суперключ: Набор всех ключей, которые могут уникально идентифицировать все строки в таблице.
Кандидатный ключ: Атрибуты, которые уникально идентифицируют строки в таблице.
Внешний ключ: Ссылка на первичный ключ другой таблицы.
Альтернативный ключ: Ключи, которые не являются первичными ключами, известны как альтернативные ключи.
Вспомогательный ключ: Значение, сгенерированное системой, которое уникально идентифицирует каждую запись в таблице, когда ни один другой столбец не способен обладать свойствами первичного ключа.
Зависимости
Частичная зависимость: Возникает, когда первичный ключ определяет другие атрибуты.
Функциональная зависимость: Это отношение, которое существует между двумя атрибутами, обычно между первичным ключом и неключевым атрибутом в пределах таблицы.
Транзитивная функциональная зависимость: Возникает, когда некоторый неключевой атрибут определяет другой атрибут.
Аномалии
Аномалия базы данных возникает, когда в базе данных есть недостаток из-за неправильного планирования или хранения всего в плоской базе данных. Это обычно устраняется с помощью процесса нормализации.
Существует три типа аномалий базы данных:
Аномалия вставки: Возникает, когда мы не можем вставить определенные атрибуты в базу данных без наличия других атрибутов.
Аномалия обновления: Возникает в случае избыточности данных и частичного обновления. Другими словами, правильное обновление базы данных требует других действий, таких как добавление, удаление или оба действия.
Аномалия удаления: Возникает, когда удаление некоторых данных требует удаления других данных.
Пример
Давайте рассмотрим следующую таблицу, которая не нормализована:
| ID | Name | Role | Team |
|---|---|---|---|
| 1 | Peter | Software Engineer | A |
| 2 | Brian | DevOps Engineer | B |
| 3 | Hailey | Product Manager | C |
| 4 | Hailey | Product Manager | C |
| 5 | Steve | Frontend Engineer | D |
This will cause an insertion anomaly as the team attribute is not yet present. Давайте представим, что мы наняли нового сотрудника "John", но не определили сразу команду, в которой он будет работать. Это приведет к аномалии вставки, так как отсутствует соответствующий аттрибут.
Кроме того, допустим, Hailey из Команды C получил повышение. Чтобы отразить это изменение в базе данных и сохранить консистентность данных нам придется обновить 2 записи, что может привести в свою очередь к аномалии обновления.
И наконец, мы хотим удалить Команду B, но для этого нам также нужно будет удалить информацию (такую как Name и Role). Это пример аномалии удаления.
Нормализация
Нормализация - это процесс организации данных в базе данных. Это включает создание таблиц и установление отношений между этими таблицами в соответствии с правилами, разработанными как для защиты данных, так и для сделать базу данных более гибкой путем устранения избыточности и несогласованных зависимостей. Зачем нам нужна нормализация?
Цель нормализации - устранение избыточных данных и обеспечение их согласованности. Полностью нормализованная база данных позволяет расширять свою структуру для вмещения новых типов данных без существенного изменения существующей структуры. В результате приложения, взаимодействующие с базой данных, минимально затрагиваются.
Normal forms
1NF
Первая нормальная форма (1NF) устанавливает следующие правила для таблицы:
- Повторяющиеся группы не допускаются.
- Каждый набор связанных данных должен иметь первичный ключ.
- Набор связанных данных должен иметь отдельную таблицу.
- Смешивание типов данных в одном столбце не допускается.
2NF
Вторая нормальная форма (2NF) устанавливает следующие правила для таблицы:
- Удовлетворяет первой нормальной форме (1NF).
- Не должно быть частичной зависимости.
3NF
Третья нормальная форма (3NF) устанавливает следующие правила для таблицы:
- Удовлетворяет второй нормальной форме (2NF).
- Транзитивные функциональные зависимости не допускаются.
BCNF
Форма Бойса-Кодда (или BCNF) является немного более сильной версией третьей нормальной формы (3NF), используемой для устранения определенных видов аномалий, с которыми изначально не справляется 3NF. Иногда она также известна как 3.5 нормальная форма (3.5NF).
Для того чтобы таблица находилась в нормальной форме Бойса-Кодда (BCNF), она должна следовать следующим правилам:
- Удовлетворяет третьей нормальной форме (3NF).
- Для каждой функциональной зависимости X → Y, X должен быть суперключом.
Существуют и другие нормальные формы, такие как 4NF, 5NF и 6NF, но мы не будем обсуждать их здесь. Ознакомьтесь с этим удивительным видео, которое подробно объясняет.
В реляционной базе данных отношение часто описывается как "нормализованное", если оно соответствует третьей нормальной форме. Большинство отношений 3NF свободны от аномалий при вставке, обновлении и удалении.
Как и в случае с многими формальными правилами и спецификациями, реальные сценарии не всегда позволяют идеальное соответствие. Если вы решите нарушить одно из первых трех правил нормализации, убедитесь, что ваше приложение предвидит возможные проблемы, такие как избыточные данные и несогласованные зависимости.
Преимущества
Вот некоторые преимущества нормализации:
- Снижает избыточность данных.
- Лучшее проектирование данных.
- Увеличивает согласованность данных.
- Обеспечивает целостность ссылочных связей.
Недостатки
Давайте рассмотрим некоторые недостатки нормализации:
- Сложное проектирование данных.
- Медленная производительность.
- Дополнительная нагрузка при обслуживании.
- Требуются больше соединений (JOIN).
Денормализация
Денормализация - это техника оптимизации базы данных, при которой мы добавляем избыточные данные в одну или несколько таблиц. Это помогает избежать дорогостоящих объединений в реляционной базе данных. Она стремится улучшить производительность чтения за счет некоторого снижения производительности записи. Избыточные копии данных записываются в несколько таблиц, чтобы избежать дорогостоящих объединений.
Когда данные становятся распределенными с помощью таких техник, как федерация и шардинг, управление объединениями по сети еще больше увеличивает сложность. Денормализация может избежать необходимости таких сложных объединений.
Примечание: Денормализация не означает отмену нормализации.
Преимущества
Давайте рассмотрим некоторые преимущества денормализации:
- Получение данных происходит быстрее.
- Запросы составляются проще.
- Уменьшение количества таблиц.
- Удобно управлять.
Недостатки
Ниже приведены некоторые недостатки денормализации:
- Дорогие вставки и обновления.
- Увеличивает сложность проектирования базы данных.
- Увеличивает избыточность данных.
- Больше шансов на несогласованность данных.
Модели согласованности данных
Давайте обсудим модели согласованности ACID и BASE.
ACID
Термин ACID означает Atomicity (Атомарность), Consistency (Согласованность), Isolation (Изолированность) и Durability (Устойчивость). Свойства ACID используются для поддержания целостности данных во время обработки транзакций.
Для поддержания согласованности до и после транзакции реляционные базы данных следуют свойствам ACID. Давайте разберем эти термины:
Атомарность
Все операции в транзакции завершаются успешно или каждая операция отменяется.
Согласованность
После завершения транзакции база данных имеет структурную целостность.
Изолированность
Транзакции не конфликтуют друг с другом. Конфликтный доступ к данным управляется базой данных таким образом, что транзакции кажутся выполняющимися последовательно.
Устойчивость
После завершения транзакции и записи и обновления данных на диске они остаются в системе даже в случае сбоя системы.
BASE
С увеличивающимся объемом данных и высокими требованиями к доступности подход к проектированию баз данных также радикально изменился. Для повышения масштабируемости и одновременно обеспечения высокой доступности мы перемещаем логику из базы данных на отдельные серверы. Таким образом, база данных становится более независимой и сосредоточена на реальном процессе хранения данных.
В мире баз данных NoSQL транзакции ACID менее распространены, поскольку некоторые базы данных ослабляют требования к мгновенной согласованности, актуальности данных и точности для достижения других преимуществ, таких как масштабирование и устойчивость.
Свойства BASE намного менее строгие, чем гарантии ACID, но между этими двумя моделями согласованности нет прямого однозначного соответствия. Давайте разберем эти термины:
Основная доступность
База данных кажется работающей большую часть времени.
Мягкое состояние
Хранилища не обязаны быть согласованными при записи, и различные реплики не обязаны быть взаимно согласованными все время.
Постепенная согласованность
Данные могут быть не согласованными немедленно, но в конечном итоге они становятся согласованными. Чтение в системе все еще возможно, даже если оно не дает правильного ответа из-за несогласованности.
ACID vs BASE Trade-offs
Нет однозначного ответа на вопрос, нужна ли нашему приложению модель согласованности ACID или BASE. Обе модели были разработаны для удовлетворения различных требований. При выборе базы данных мы должны учитывать свойства обеих моделей и требования нашего приложения.
Учитывая слабую согласованность BASE, разработчики должны обладать более глубокими знаниями и строгостью в отношении согласованных данных, если они выбирают хранилище BASE для своего приложения. Важно знать поведение BASE выбранной базы данных и работать в рамках этих ограничений.
С другой стороны, планирование вокруг ограничений BASE иногда может быть серьезным недостатком по сравнению с простотой транзакций ACID. Полностью ACID-совместимая база данных идеально подходит для использования в случаях, когда надежность данных и согласованность являются важными.
Теорема CAP
Теорема CAP говорит, что распределенная система может обеспечить только два из трех желаемых характеристик: Согласованность (Consistency), Доступность (Availability) и Устойчивость к разделению (Partition tolerance).
Согласованность
Согласованность означает, что все клиенты видят одни и те же данные в одно и то же время, независимо от того, к какому узлу они подключены. Для этого, когда данные записываются на один узел, они должны немедленно пересылаться или реплицироваться на все узлы в системе, прежде чем запись будет считаться "успешной".
Доступность
Доступность означает, что любой клиент, запрашивающий данные, получает ответ, даже если один или несколько узлов вышли из строя.
Терпимость к разделению
Терпимость к разделению означает, что система продолжает работать, несмотря на потерю сообщений или частичный сбой. Система, которая терпима к разделению, может выдержать любое количество сбоев сети, которые не приводят к полному сбою всей сети. Данные должны быть достаточно реплицированы среди комбинаций узлов и сетей, чтобы поддерживать систему в рабочем состоянии при периодических сбоях.
Компромисс между согласованностью и доступностью
Мы живем в физическом мире и не можем гарантировать стабильность сети, поэтому распределенные базы данных должны выбирать Терпимость к разделению (P). Это предполагает компромисс между Согласованностью (C) и Доступностью (A).
База данных CA
База данных CA обеспечивает согласованность и доступность на всех узлах. Она не может этого сделать, если есть разделение между любыми двумя узлами в системе, и, следовательно, не может обеспечить отказоустойчивость.
Example: PostgreSQL, MariaDB.
CP database
CP база данных обеспечивает согласованность и устойчивость к разделению за счет отказа от доступности. Когда происходит разделение между любыми двумя узлами, система должна выключить неконсистентный узел до устранения разделения.
Example: MongoDB, Apache HBase.
AP database
AP база данных обеспечивает доступность и устойчивость к разделению за счет согласованности. При разделении все узлы остаются доступными, но узлы, находящиеся в неправильном конце разделения, могут возвращать более старую версию данных, чем другие. Когда разделение разрешается, AP базы данных обычно синхронизируют узлы для устранения всех несогласованностей в системе.
Example: Apache Cassandra, CouchDB.
Теорема PACELC
Теорема PACELC является расширением теоремы CAP. Теорема CAP утверждает, что в случае разделения сети (P) в распределенной системе приходится выбирать между доступностью (A) и согласованностью (C).
PACELC расширяет теорему CAP, вводя задержку (L) как дополнительный атрибут распределенной системы. Теорема утверждает, что даже когда система работает нормально в отсутствие разделений, приходится выбирать между задержкой (L) и согласованностью (C).
The PACELC theorem was first described by Daniel J. Abadi.
Теорема PACELC была разработана для решения ключевого ограничения теоремы CAP, поскольку она не учитывает производительность или задержку.
Например, согласно теореме CAP, база данных может считаться доступной, если запрос возвращает ответ через 30 дней. Очевидно, что такая задержка была бы неприемлемой для любого прикладного приложения в реальном мире.
Транзакции
Транзакция - это серия операций с базой данных, которые считаются "единичной рабочей единицей". Операции в транзакции либо все успешны, либо все откатываются. Таким образом, понятие транзакции поддерживает целостность данных в случае отказа части системы. Не все базы данных выбирают поддержку ACID-транзакций, обычно потому, что они отдают предпочтение другим оптимизациям, которые сложно или теоретически невозможно реализовать вместе.
Обычно реляционные базы данных поддерживают ACID-транзакции, а нереляционные базы данных нет (существуют исключения).
Состояния
Транзакция базы данных может иметь одно из следующих состояний:
Active
В этом состоянии транзакция выполняется. Это начальное состояние каждой транзакции.
Partially Committed
Когда транзакция выполняет свою последнюю операцию, она находится в состоянии частичного подтверждения.
Committed
Если транзакция успешно выполняет все свои операции, она считается подтвержденной. Все ее эффекты теперь окончательно установлены в системе баз данных.
Failed
Транзакция находится в состоянии отказа, если любая из проверок, выполняемых системой восстановления базы данных, завершается неудачно. Транзакция в состоянии отказа больше не может продолжаться.
Aborted
Если любая из проверок завершается неудачно и транзакция находится в состоянии отказа, то менеджер восстановления отменяет все ее операции записи в базе данных, чтобы вернуть базу данных к исходному состоянию до выполнения транзакции. Транзакции в этом состоянии абортируются.
Модуль восстановления базы данных может выбрать одну из двух операций после аборта транзакции:
- Перезапустить транзакцию
- Отменить транзакцию
Terminated
Если нет никакого отката или транзакция происходит из состояния подтверждено, то система согласована и готова к новой транзакции, а старая транзакция завершается.
Распределенные транзакции
Распределенная транзакция - это набор операций с данными, выполняемых в двух или более базах данных. Обычно она координируется через отдельные узлы, соединенные сетью, но также может охватывать несколько баз данных на одном сервере.
Why do we need distributed transactions?
В отличие от ACID-транзакции в одной базе данных, распределенная транзакция включает изменение данных в нескольких базах данных. Следовательно, обработка распределенных транзакций более сложна, поскольку база данных должна согласовать фиксацию или откат изменений в транзакции как самостоятельной единицы.
Другими словами, все узлы должны фиксировать изменения, либо все должны отменить операции, и вся транзакция откатывается. Вот почему нам нужны распределенные транзакции.
Теперь давайте рассмотрим некоторые популярные решения для распределенных транзакций:
Two-Phase commit
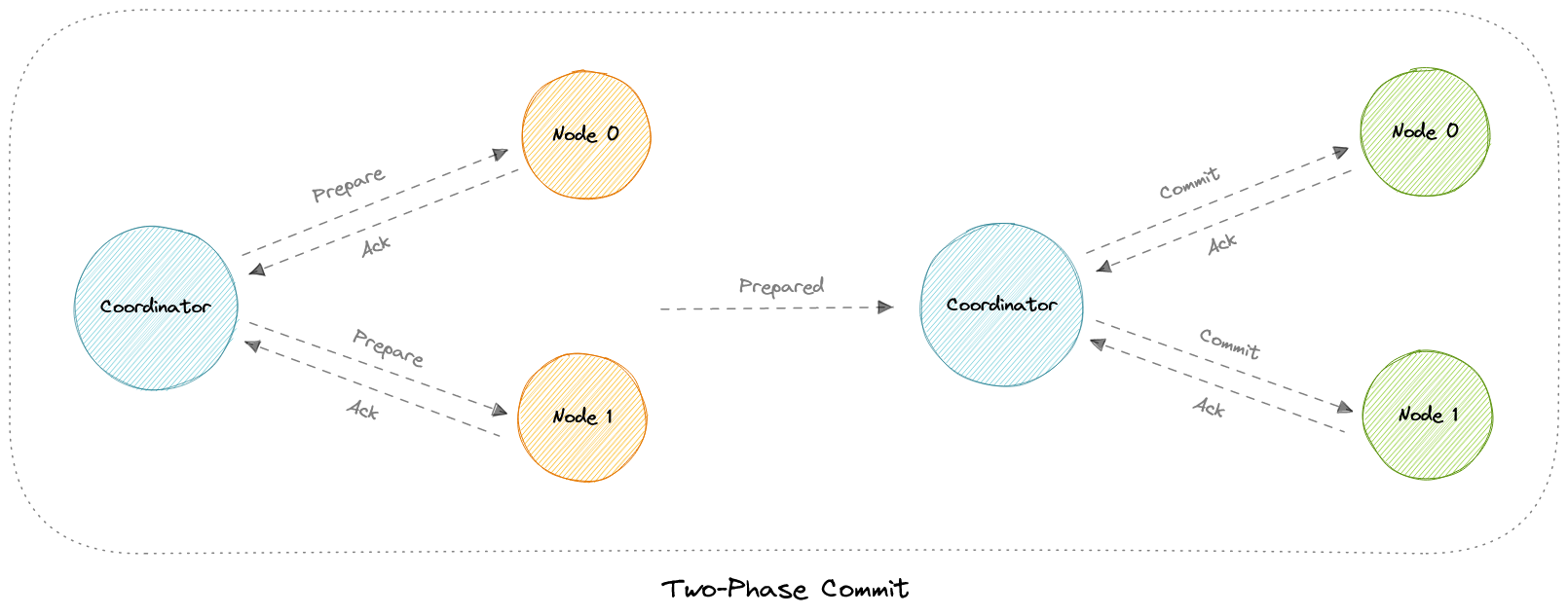
Протокол двухфазного коммита (2PC) - это распределенный алгоритм, который координирует все процессы, участвующие в распределенной транзакции, в определении, следует ли фиксировать или отменить (откатить) транзакцию.
Этот протокол достигает своей цели даже во многих случаях временного сбоя системы и поэтому широко используется. Однако он не является устойчивым ко всем возможным конфигурациям отказа, и в редких случаях может потребоваться ручное вмешательство для исправления исходного результата.
Этот протокол требует наличия узла-координатора, который фактически координирует и наблюдает за транзакцией на различных узлах. Координатор пытается достичь консенсуса среди набора процессов в две фазы, отсюда и название.
Фазы
Двухфазное подтверждение состоит из следующих фаз:
Фаза подготовки
В фазе подготовки координирующий узел собирает согласие от каждого участвующего узла. Транзакция будет отменена, если каждый узел не ответит, что он подготовлен.
Фаза подтверждения
Если все участники ответили координатору, что они подготовлены, то координатор запрашивает у всех узлов подтверждение транзакции. Если произойдет сбой, транзакция будет откатываться.
Проблемы
В двухфазном протоколе подтверждения могут возникнуть следующие проблемы:
- Что, если один из узлов выйдет из строя?
- Что, если сам координатор выйдет из строя?
- Это блокирующий протокол.
Трех-фазовый коммит
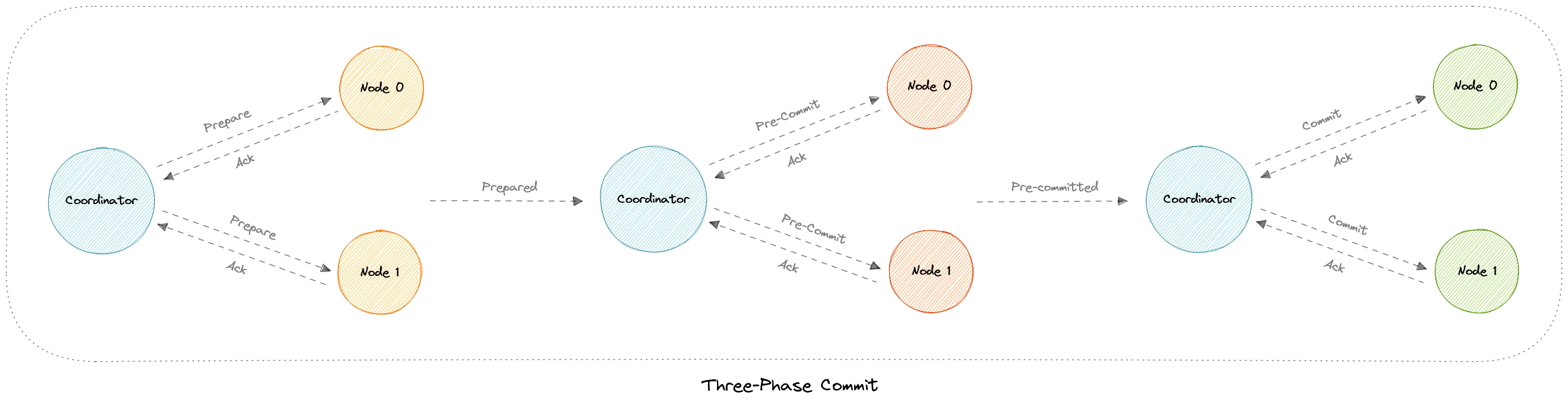
Трехфазный коммит (3PC) является расширением двухфазного коммита, где фаза коммита разбивается на две фазы. Это помогает с проблемой блокировки, которая возникает в протоколе двухфазного коммит. Фазы
Трехфазный коммит состоит из следующих фаз:
Фаза подготовки
Эта фаза такая же, как в двухфазном коммите.
Фаза предварительного коммита
Координатор отправляет сообщение о предварительном коммите, и все участвующие узлы должны его подтвердить. Если участник не успевает получить это сообщение вовремя, тогда транзакция аннулируется.
Фаза подтверждения
Этот шаг также аналогичен протоколу двухфазного коммита. Почему фаза предварительного подтверждения полезна?
Фаза предварительного подтверждения выполняет следующее:
Если узлы-участники найдены на этой фазе, это означает, что каждый участник завершил первую фазу. Завершение фазы подготовки гарантировано.
Теперь каждая фаза может завершиться по тайм-ауту и избежать бесконечных ожиданий.
Sagas
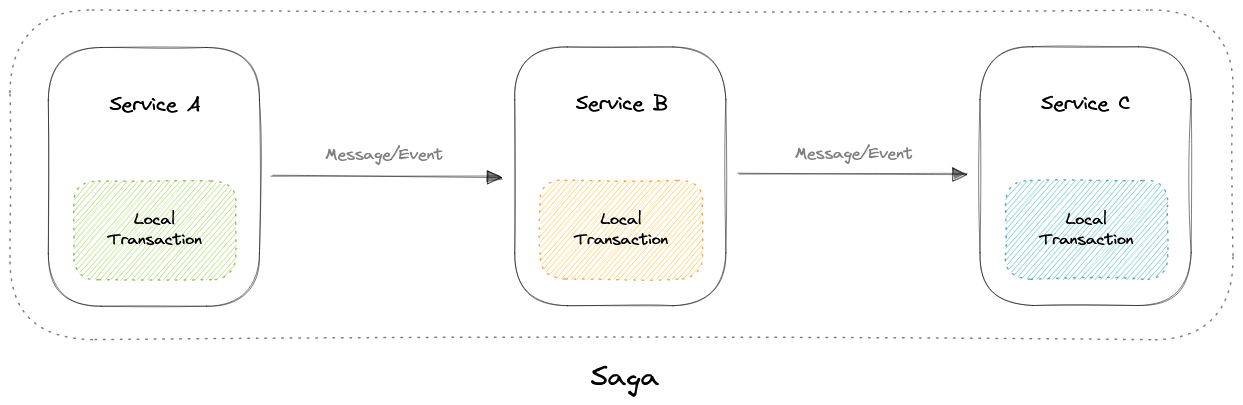
Сага представляет собой последовательность локальных транзакций. Каждая локальная транзакция обновляет базу данных и публикует сообщение или событие, чтобы запустить следующую локальную транзакцию в саге. Если локальная транзакция завершается неудачей из-за нарушения бизнес-правила, то сага выполняет серию компенсирующих транзакций, которые отменяют изменения, внесенные предыдущими локальными транзакциями.
Координация
Существует два распространенных подхода к реализации:
- Хореография: Каждая локальная транзакция публикует события домена, которые запускают локальные транзакции в других сервисах.
- Оркестровка: Оркестратор сообщает участникам, какие локальные транзакции выполнить.
Проблемы
- Шаблон саги особенно сложно отлаживать.
- Существует риск циклической зависимости между участниками саги.
- Отсутствие изоляции данных участников влечет проблемы сохранности.
- Тестирование затруднено, потому что все сервисы должны работать для имитации транзакции.
Шардирование
Прежде чем мы поговорим о шардинге, давайте обсудим разделение данных:
Разделение данных
Разделение данных - это техника, позволяющая разбить базу данных на множество меньших частей. Это процесс разбиения базы данных или таблицы на несколько машин для улучшения управляемости, производительности и доступности базы данных.
Методы
Существует множество различных способов, которые можно использовать для определения того, как разбить базу данных приложения на несколько меньших баз данных. Ниже приведены два наиболее популярных метода, используемых в различных крупномасштабных приложениях:
Горизонтальное разделение (или шардинг)
При этой стратегии мы разбиваем данные таблицы горизонтально на основе диапазона значений, определенного ключом разделения. Это также называется шардингом баз данных.
Вертикальное разделение
При вертикальном разделении мы разбиваем данные вертикально по столбцам. Мы разделяем таблицы на относительно более мелкие таблицы с несколькими элементами, и каждая часть находится в отдельном разделе.
В этом руководстве мы будем сосредотачиваться на шардинге.
Что такое шардинг?
Шардинг - это архитектурный шаблон базы данных, связанный с горизонтальным разделением, практикой разделения строк одной таблицы на несколько различных таблиц, известных как партиции или шарды. Каждая партиция имеет ту же схему и столбцы, но также подмножество общих данных. Точно так же, данные, хранящиеся в каждой партиции, уникальны и независимы от данных, хранящихся в других партициях.
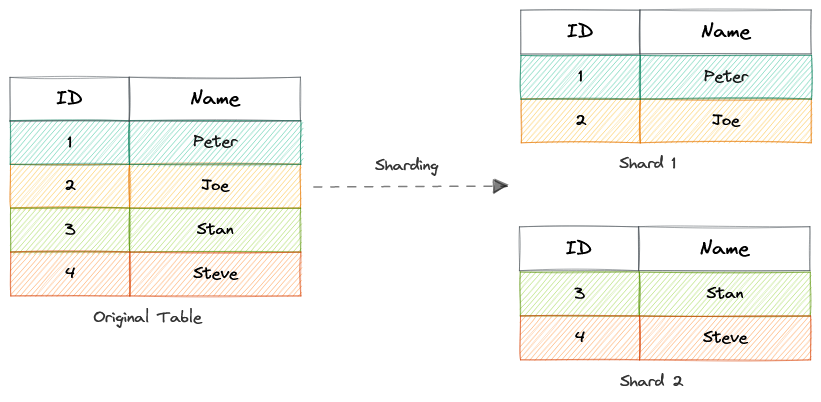
Обоснование для шардинга данных заключается в том, что после определенного момента дешевле и более осуществимо масштабировать горизонтально, добавляя больше машин, чем масштабировать вертикально, добавляя мощные серверы. Шардинг может быть реализован как на уровне приложения, так и на уровне базы данных.
Критерии разделения
Существует большое количество критериев доступных для разделения данных. Некоторые из наиболее часто используемых критериев:
Основанный на хешах
Эта стратегия делит строки на разные разделы на основе алгоритма хеширования, а не группирует строки базы данных на основе непрерывных индексов.
Недостаток этого метода заключается в том, что динамическое добавление/удаление серверов базы данных становится дорогостоящим.
Основанный на списке
При разделении на основе списка каждый раздел определяется и выбирается на основе списка значений в столбце, а не на основе набора непрерывных диапазонов значений.
Основанный на диапазонах
Разделение на основе диапазонов отображает данные в различные разделы на основе диапазонов значений ключа разделения. Другими словами, мы разбиваем таблицу таким образом, чтобы каждый раздел содержал строки в определенном диапазоне, определенном ключом разделения.
Диапазоны должны быть непрерывными, но не перекрывающимися, где каждый диапазон определяет невключительную нижнюю и верхнюю границу для раздела. Любые значения ключа разделения, равные или выше верхней границы диапазона, добавляются в следующий раздел.
Составной
Как следует из названия, составное разделение данных происходит на основе двух или более методов разделения. Здесь мы сначала разделяем данные с использованием одного метода, а затем каждый раздел дополнительно подразделяется на подразделы с использованием того же или какого-то другого метода.
Преимущества
Но зачем нам нужен шардинг? Вот несколько преимуществ:
- Доступность: Обеспечивает логическую независимость разделенной базы данных, обеспечивая высокую доступность нашего приложения. Здесь отдельные разделы могут управляться независимо.
- Масштабируемость: Повышает масштабируемость путем распределения данных по нескольким разделам.
- Безопасность: Помогает повысить безопасность системы, храня чувствительные и нечувствительные данные в разных разделах. Это может обеспечить лучшую управляемость и защиту конфиденциальных данных.
- Производительность запроса: Улучшает производительность системы. Теперь система должна запрашивать только меньший раздел, а не всю базу данных.
- Управляемость данных: Разделяет таблицы и индексы на более мелкие и управляемые единицы.
Недостатки
- Сложность: Шардинг увеличивает сложность системы в целом.
- Объединения между разделами: После того как база данных разделена и распределена по нескольким машинам, часто нецелесообразно выполнять объединения, которые охватывают несколько баз данных. Такие объединения не будут эффективными с точки зрения производительности, поскольку данные придется извлекать из нескольких серверов.
- Перебалансировка: Если распределение данных неравномерно или на одном разделе слишком большая нагрузка, в таких случаях нам придется перебалансировать наши разделы, чтобы запросы были как можно равномерно распределены между ними.
Когда использовать шардинг?
Вот несколько причин, почему шардинг может быть правильным выбором:
- Использование существующего оборудования вместо высокопроизводительных машин.
- Хранение данных в различных географических регионах.
- Быстрое масштабирование путем добавления большего количества шардов.
- Лучшая производительность, поскольку каждая машина нагружена меньше.
- Когда требуются более множественные соединения.
Согласованное хеширование
Давайте сначала поймем проблему, которую мы пытаемся решить.
Зачем это нужно?
В традиционных методах распределения на основе хеширования мы используем хэш-функцию для хеширования наших ключей раздела (например, идентификатор запроса или IP). Затем, если мы используем операцию взятия остатка от деления на общее количество узлов (серверов или баз данных), это даст нам узел, куда мы хотим направить наш запрос.
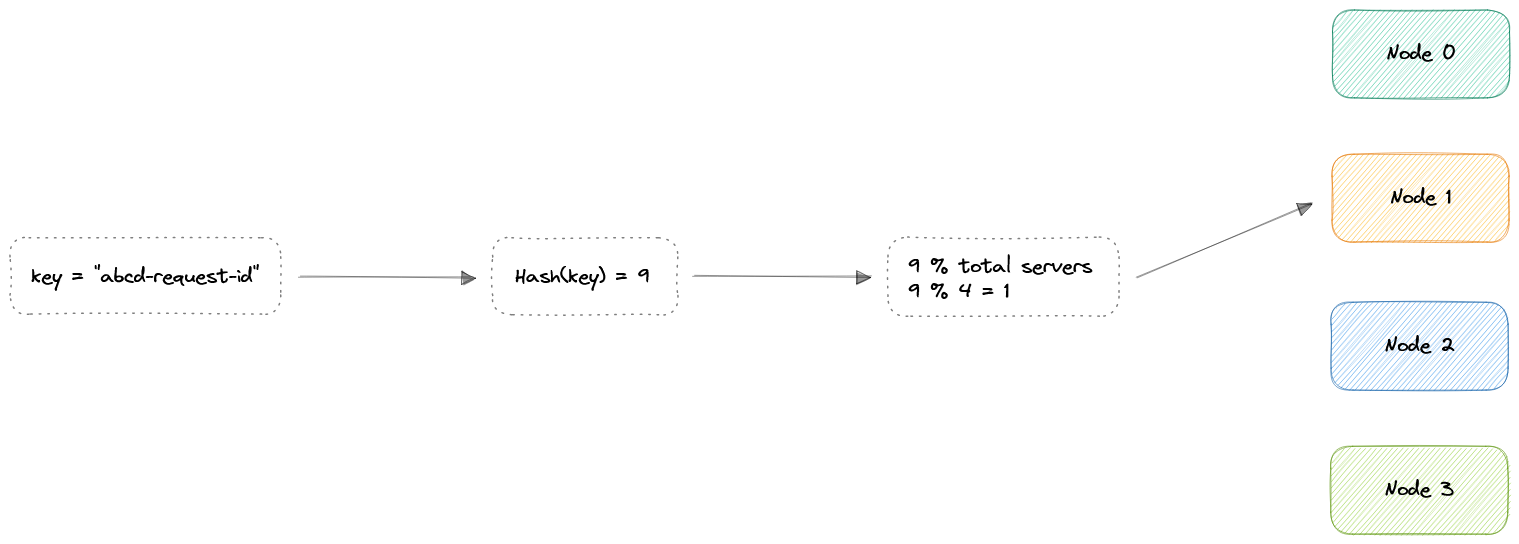
$$ \begin{align*} & Hash(key_1) \to H_1 \bmod N = Node_0 \ & Hash(key_2) \to H_2 \bmod N = Node_1 \ & Hash(key_3) \to H_3 \bmod N = Node_2 \ & ... \ & Hash(key_n) \to H_n \bmod N = Node_{n-1} \end{align*} $$
Где,
key: Идентификатор запроса или IP.
H: Результат хэш-функции.
N: Общее количество узлов (нод).
Node: Нода, где маршрутизуется запрос.
Проблема может возникнуть, если мы добавляем или удаляем ноду. В результате такой операции меняется N, что приведет к неправильной работе нашей стратегии маршрутизации, так как тоже количество запросов будет направлено на другой сервер. Как следствие, большую часть запросов необходимо будет распределять по-новому, что неудобно.
Нам хотелось бы единообразно распределять запросы между разными нодами так, чтобы при добавлении или удалении нод требовались минимальные изменения. Следовательно нам нужна такая схема распределения запросов, которая бы не зависила напрямую от количества нод (или серверов), так что при добавлении или удалении нод число перемещаемых ключей было минимальным.
Consistent hashing решает эту проблему горизонтального масштабирования гарантируя, что при любом масштабировании нам не нужно будет перекомпоновывать все ключи или трогать сервера.
Теперь, когда мы понимаем проблему, давайте рассмотрим подробнее сам механизм consistent hashing.
Как это работает
Consistent Hashing - это распределенная схема хэширования, которая работает вне зависимости от числа нод в распределенной хэш-таблице назначая им место в абстрактном круге (кольце хэшей). Это дает возможность масштабировать сервера и другие объекты без необходимости затрагивать всю систему в целом.
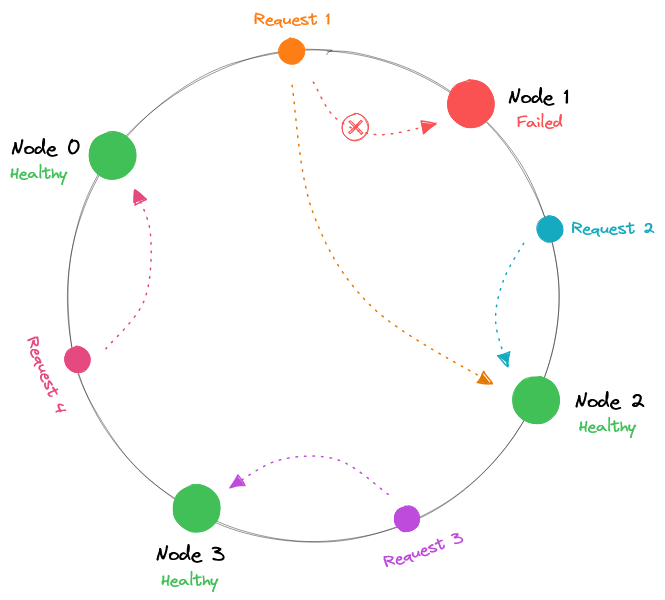
При использовании consistent hashing, только K/N записей надо будет перераспределять.
$$ R = K/N $$
Where,
R: Данные, которые потребуют перераспределения.
K: Число ключей разделения (partition keys).
N: Количество нод.
Допустим вывод функции хэширования в диапазоне 0...m-1, что можно отразить на нашем хэш-кольце.
Мы хэшируем запросы и распределяем их по кольцу в зависимости от результата хэширования.
Аналогично мы хэшируем ноды и также распределяем их по кольцу хэширования.
$$ \begin{align*} & Hash(key_1) = P_1 \ & Hash(key_2) = P_2 \ & Hash(key_3) = P_3 \ & ... \ & Hash(key_n) = P_{m-1} \end{align*} $$
Где,
key: Идентификатор запроса/ноды или IP.
P: Положение в хэш-кольце.
m: Общий диапазон хэш-кольца.
Теперь, когда поступает запрос, мы можем просто направить его к ближайшему узлу по часовой стрелке (или против часовой стрелки). Это означает, что если добавлен или удален новый узел, мы можем использовать ближайший узел, и лишь доля запросов потребует перенаправления.
В теории, консистентное хеширование должно равномерно распределять нагрузку, однако на практике это не всегда происходит. Обычно распределение нагрузки неравномерно, и один сервер может обрабатывать большинство запросов, становясь горячей точкой, фактическим узким местом для системы. Мы можем исправить это, добавив дополнительные узлы, но это может быть дорогостоящим решением.
Давайте посмотрим, как мы можем решить эти проблемы.
Виртуальные узлы
Для обеспечения более равномерной распределенной нагрузки мы можем ввести понятие виртуального узла, иногда также называемого VNode.
Вместо назначения одной позиции узлу, диапазон хеширования делится на несколько меньших диапазонов, и каждому физическому узлу назначаются несколько из этих меньших диапазонов. Каждый из этих поддиапазонов считается виртуальным узлом. Таким образом, виртуальные узлы по сути представляют собой существующие физические узлы, отображенные несколько раз по кольцу хешей, чтобы минимизировать изменения диапазона, назначенного узлу.
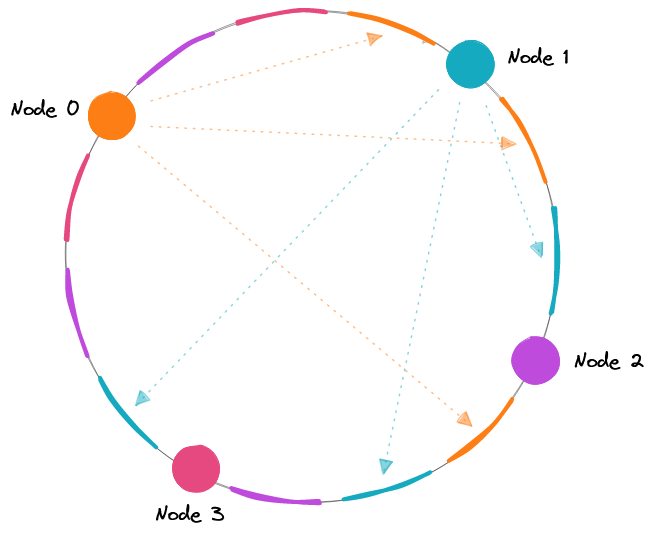
For this, we can use k number of hash functions.
$$ \begin{align*} & Hash_1(key_1) = P_1 \ & Hash_2(key_2) = P_2 \ & Hash_3(key_3) = P_3 \ & . . . \ & Hash_k(key_n) = P_{m-1} \end{align*} $$
Where,
key: Идентификатор запроса/ноды или IP.
k: Число хэш-функций.
P: Положение в хэш-кольце.
m: Общий диапазон хэш-кольца.
Репликация данных
Для обеспечения высокой доступности и надежности консистентное хеширование реплицирует каждый элемент данных на несколько узлов N в системе, где значение N эквивалентно фактору репликации.
Фактор репликации - это количество узлов, которые получат копию тех же данных. В системах с эвентуальной согласованностью это происходит асинхронно.
Преимущества
Давайте рассмотрим некоторые преимущества консистентного хеширования:
- Позволяет более предсказуемо масштабировать систему вверх и вниз.
- Упрощает разделение и репликацию данных между узлами.
- Обеспечивает масштабируемость и доступность.
- Снижает вероятность появления горячих точек.
Недостатки
Ниже приведены некоторые недостатки консистентного хеширования:
- Увеличивает сложность.
- Каскадные сбои.
- Распределение нагрузки все равно может быть неравномерным.
- Управление ключами может быть дорогим в случае временных сбоев узлов.
Примеры
Давайте рассмотрим некоторые примеры использования согласованного хеширования:
- Разделение данных в Apache Cassandra.
- Распределение нагрузки между несколькими хранилищами в Amazon DynamoDB.
Федеративная база данных
Федерация (или функциональное разделение) разбивает базы данных по функциональности. Архитектура федерации делает несколько отдельных физических баз данных видимыми как одну логическую базу данных для конечных пользователей.
Все компоненты в федерации связаны одной или несколькими федеральными схемами, которые выражают общность данных по всей федерации. Эти федеральные схемы используются для указания информации, которая может быть общей для компонентов федерации, и для обеспечения общей основы для взаимодействия между ними.
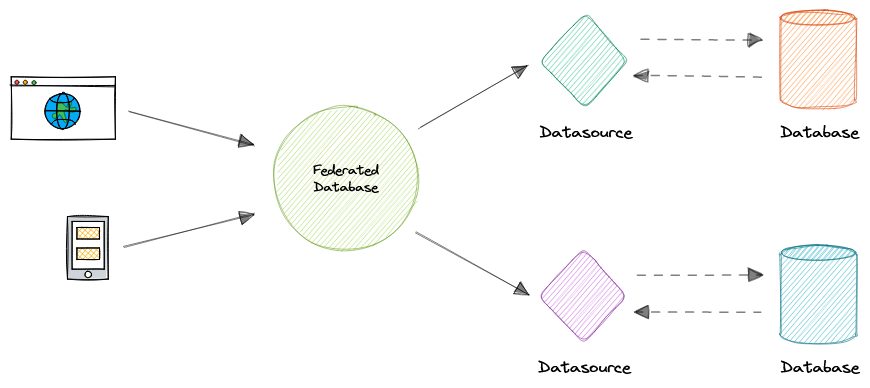
Характеристики
Давайте рассмотрим некоторые ключевые характеристики федеративной базы данных:
- Прозрачность: Федеративная база данных скрывает различия между пользователями и реализациями базовых источников данных. Пользователям не нужно знать, где хранятся данные.
- Гетерогенность: Источники данных могут различаться во многих аспектах. Система федеративной базы данных может работать с различным оборудованием, сетевыми протоколами, моделями данных и т. д.
- Расширяемость: Для удовлетворения изменяющихся потребностей бизнеса могут потребоваться новые источники данных. Хорошая система федеративной базы данных должна упростить добавление новых источников.
- Автономность: Федеративная база данных не изменяет существующие источники данных, интерфейсы должны оставаться прежними.
- Интеграция данных: Федеративная база данных может интегрировать данные из разных протоколов, систем управления базами данных и т. д.
Преимущества
Вот некоторые преимущества федеративных баз данных:
- Гибкое обмен данных.
- Автономия между компонентами базы данных.
- Доступ к гетерогенным данным в унифицированном виде.
- Отсутствие тесной связи приложений с устаревшими базами данных.
Недостатки
Ниже приведены некоторые недостатки федеративных баз данных:
- Увеличение аппаратных ресурсов и дополнительная сложность.
- Сложность объединения данных из двух баз данных.
- Зависимость от автономных источников данных.
- Производительность запросов и масштабируемость.
Многозвенная архитектура
Многозвенная архитектура разделяет приложение на логические слои и физические уровни (tiers). Слои - это способ разделить функции и управлять зависимостями. Каждый уровень отвечает за специфическую задачу. Более высокие слои могут использовать сервисы более низкого слоя, но не наоборот.
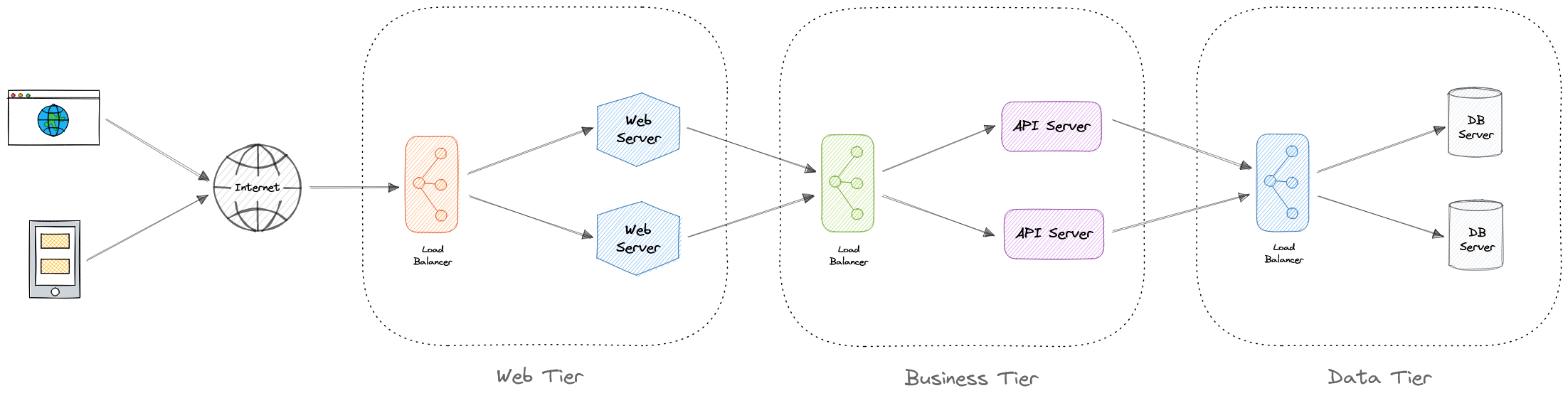
Уровни физически разделены и работают на отдельных машинах. Уровень может обращаться к другому уровню напрямую или использовать асинхронное сообщение. Хотя каждый слой может быть размещен на своем собственном уровне, это не является обязательным. Несколько слоев могут быть размещены на одном уровне. Физическое разделение уровней улучшает масштабируемость и надежность, а также добавляет задержку из-за дополнительного сетевого взаимодействия.
Архитектура N-уровней может быть двух типов:
- В закрытой архитектуре слоя слой может обращаться только к следующему слою ниже.
- В открытой архитектуре слоя слой может вызывать любой из слоев ниже него.
Закрытая архитектура слоев ограничивает зависимости между слоями. Однако это может создавать излишний сетевой трафик, если один слой просто передает запросы следующему слою.
Типы архитектур N-уровней
Давайте рассмотрим некоторые примеры архитектур N-уровней:
Архитектура 3-уровневой
3-уровневая архитектура широко используется и состоит из следующих различных уровней:
- Слой представления: обрабатывает взаимодействие пользователя с приложением.
- Бизнес-логика: принимает данные от уровня приложения, проверяет их в соответствии с бизнес-логикой и передает их на уровень доступа к данным.
- Слой доступа к данным: получает данные от бизнес-уровня и выполняет необходимые операции с базой данных.
Архитектура 2-уровневой
В этой архитектуре слой представления работает на клиенте и взаимодействует с хранилищем данных. Здесь нет слоя бизнес-логики или промежуточного слоя между клиентом и сервером.
Архитектура с одним уровнем или 1-уровневая архитектура
Это самая простая архитектура, так как эквивалентна запуску приложения на персональном компьютере. Все необходимые компоненты для запуска приложения находятся на одном приложении или сервере.
Преимущества
Вот некоторые преимущества использования архитектуры N-уровней:
- Могут повысить доступность.
- Более высокий уровень безопасности, поскольку уровни могут вести себя как брандмауэр.
- Отдельные уровни позволяют масштабировать их по мере необходимости.
- Улучшают обслуживание, так как различные лица могут управлять различными уровнями.
Недостатки
Ниже приведены некоторые недостатки архитектуры N-уровней:
- Увеличивается сложность всей системы.
- Увеличивается сетевая задержка с увеличением количества уровней.
- Дорого в эксплуатации, так как каждый уровень будет иметь свою собственную стоимость оборудования.
- Сложно управлять сетевой безопасностью.
Брокеры сообщений
Брокер сообщений - это программное обеспечение, позволяющее приложениям, системам и службам обмениваться информацией и взаимодействовать друг с другом. Брокер сообщений делает это, переводя сообщения между формальными протоколами передачи сообщений. Это позволяет взаимозависимым службам "общаться" друг с другом напрямую, даже если они написаны на разных языках или реализованы на разных платформах.
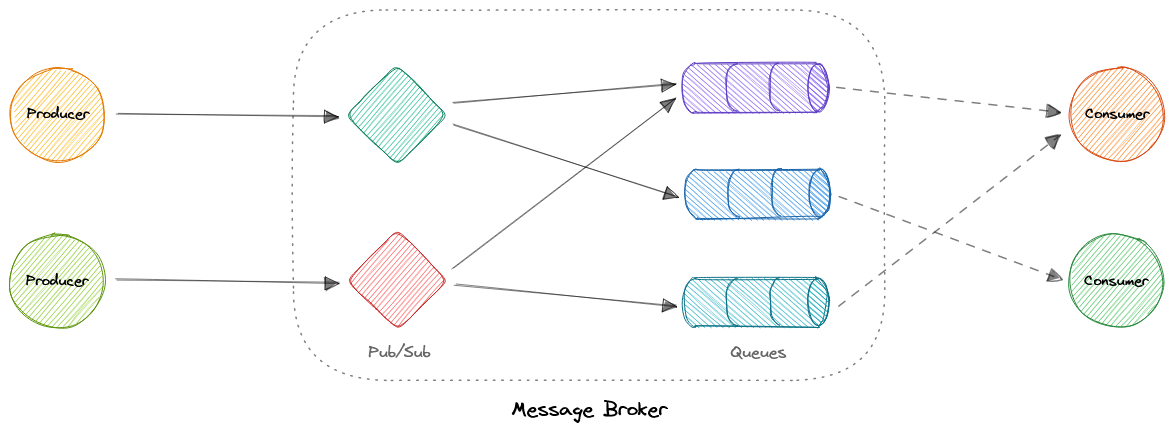
Модели
Брокеры сообщений предлагают две основные модели распределения сообщений или стиля обмена сообщениями:
- Сообщения точка-точка: Это модель распределения, используемая в очередях сообщений с однозначным соответствием между отправителем сообщения и получателем.
- Сообщения издатель-подписчик: В этой модели распределения сообщений, часто называемой "издатель-подписчик", производитель каждого сообщения публикует его в теме, и несколько потребителей сообщений подписываются на темы, из которых они хотят получать сообщения.
Мы подробно обсудим эти модели обмена сообщениями в последующих учебниках.
Брокеры сообщений VS потоки событий
Брокеры сообщений могут поддерживать две или более модели передачи сообщений, включая очереди сообщений и издатель-подписчик, в то время как платформы потоков событий предлагают только модели распространения в стиле издатель-подписчик. Разработанные для использования с большим объемом сообщений, платформы потоков событий легко масштабируются. Они способны упорядочивать потоки записей по категориям, называемым темами, и хранить их в течение определенного времени. Однако, в отличие от брокеров сообщений, платформы потоков событий не могут гарантировать доставку сообщений или отслеживать, какие потребители получили сообщения.
Платформы потоков событий предлагают большую масштабируемость по сравнению с брокерами сообщений, но меньше функций, обеспечивающих отказоустойчивость, таких как повторная отправка сообщений, а также более ограниченные возможности маршрутизации сообщений и управления очередями.
Брокеры сообщений VS Enterprise Service Bus
Инфраструктура Корпоративной Шины Служб (ESB) сложна и может быть сложно интегрирована и дорого поддерживаться. Их трудно устранять, когда возникают проблемы в производственных средах, они не могут легко масштабироваться, а обновление требует много времени и труда.
В то время как брокеры сообщений являются "легковесной" альтернативой ESB, предоставляя аналогичную функциональность, механизм взаимодействия между службами, по более низкой цене. Они хорошо подходят для использования в микросервисных архитектурах, которые стали более распространенными с уходом ESB из моды.
Примеры
Вот пример некоторых широко-используемых брокеров сообщений:
Очереди сообщений
Очереди сообщений - это форма межсервисного взаимодействия с использованием асинхронной модели обмена данными. Она асинхронно принимает сообщения от источников и посылает их потребителям.
Очереди используются для эффективного управления запросами в крупно-масштабных распределенных системах. В маленьких системах с минимальными нагрузками и маленькими базами данных, операции записи могут быть предсказуемо быстрыми. Однако в более сложных и больших системах операции записи могут занимать практически неограниченное время.

Работа
Сообщения хранятся в очереди до их обработки и удаления. Каждое сообщение обрабатывается только один раз одним потребителем. Вот как это работает:
- Производитель публикует задание в очереди, затем уведомляет пользователя о состоянии задания.
- Потребитель выбирает задание из очереди, обрабатывает его, затем сигнализирует о завершении задания.
Преимущества
Давайте обсудим некоторые преимущества использования очереди сообщений:
- Масштабируемость: Очереди сообщений позволяют точно масштабировать то, где нам это нужно. При пиковых нагрузках несколько экземпляров нашего приложения могут добавлять все запросы в очередь без риска коллизий.
- Разделение компонентов: Очереди сообщений удаляют зависимости между компонентами и значительно упрощают реализацию разделенных приложений.
- Производительность: Очереди сообщений обеспечивают асинхронное взаимодействие, что означает, что точки конечные точки, производящие и потребляющие сообщения, взаимодействуют с очередью, а не друг с другом. Производители могут добавлять запросы в очередь без ожидания их обработки.
- Надежность: Очереди делают наши данные устойчивыми и уменьшают ошибки, которые возникают, когда разные части нашей системы выходят из строя.
Характеристики
Теперь давайте обсудим некоторые желаемые характеристики очередей сообщений:
Доставка методом Push или Pull
Большинство очередей сообщений предоставляют как вариант доставки метод Push, так и метод Pull для получения сообщений. Pull означает постоянный запрос очереди на наличие новых сообщений. Push означает, что потребителю сообщается о наличии нового сообщения. Мы также можем использовать длинное ожидание (long-polling), чтобы позволить Pull-запросам ожидать появления новых сообщений в течение указанного времени.
Очереди FIFO (First-In-First-Out)
В таких очередях самая старая (или первая) запись, иногда называемая "головой" очереди, обрабатывается первой.
Планирование или отсроченная доставка
Многие очереди сообщений поддерживают установку определенного времени доставки сообщения. Если нам нужно установить общую задержку для всех сообщений, мы можем настроить очередь с отсроченной доставкой.
Гарантированная доставка как минимум один раз
Очереди сообщений могут хранить несколько копий сообщений для обеспечения избыточности и высокой доступности, а также повторно отправлять сообщения в случае сбоев связи или ошибок, чтобы гарантировать, что они будут доставлены как минимум один раз.
Гарантированная доставка ровно один раз
Когда дубликаты недопустимы, очереди сообщений FIFO (первым вошел - первым вышел) будут гарантировать, что каждое сообщение будет доставлено ровно один раз (и только один раз), автоматически отфильтровывая дубликаты.
Очереди для обработки ошибочных сообщений
Очередь для обработки ошибок (dead-letter queue) - это очередь, в которую другие очереди могут отправлять сообщения, которые не могут быть успешно обработаны. Это позволяет установить их в сторону для дальнейшего исследования без блокировки обработки очереди или затрат ресурсов процессора на сообщение, которое возможно никогда не будет успешно обработано.
Упорядочение
Большинство очередей сообщений обеспечивают доставку по мере возможности, что гарантирует, что сообщения, как правило, доставляются в том же порядке, в котором они отправляются, и что сообщение доставляется как минимум один раз.
Poison-pill messages
Специальные сообщения-яды могут быть получены, но не обработаны. Они являются механизмом, используемым для сигнализации потребителю о прекращении его работы, чтобы он больше не ожидал новых входных данных, и аналогичны закрытию сокета в модели клиент-сервер.
Безопасность
Очереди сообщений аутентифицируют приложения, которые пытаются получить доступ к очереди, что позволяет нам шифровать сообщения по сети, а также в самой очереди.
Очереди задач
Очереди задач принимают задачи и связанные с ними данные, выполняют их, а затем доставляют результаты. Они могут поддерживать планирование и использоваться для выполнения вычислительно-ёмких задач в фоновом режиме.
Обратное давление (Backpressure)
Если очереди начинают значительно увеличиваться, их размер может стать больше памяти, что приведет к промахам кэша, чтению с диска и еще большему снижению производительности. Механизм обратного давления может помочь, ограничивая размер очереди, тем самым поддерживая высокую скорость передачи данных и хорошее время отклика для задач, уже находящихся в очереди. Когда очередь заполняется, клиенты получают код состояния сервера 503 и пытаются повторить запрос позже. Клиенты могут повторно попытаться запросить ресурсы в более позднее время, возможно, используя стратегию экспоненциальной задержки.
Примеры
Ниже некоторые широко используемые очереди сообщений:
Публикация/Подписка
Подобно очередям сообщений, publish-subscribe - это тоже вариант межсервисной коммуникации, который облегчает асинхронное взаимодействией. В этой модели любое опубликованное сообщение в топик немедленно передается всем подписчиками этого топика.
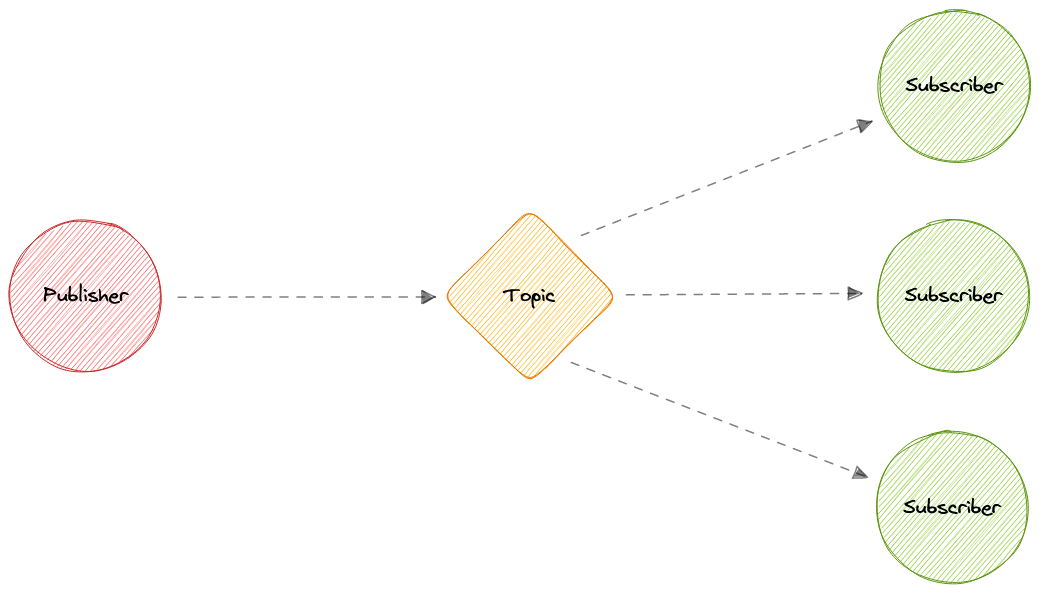
Принцип работы
В отличие от очередей сообщений, которые складывают в очередь сообщения пока они не будут запрошены, топики сообщений передают сообщения с минимальной или вообще без очереди, мгновенно отправляют их всем подписчикам. Вот как это работает:
- Топик предоставляет легкий механизм для передачи асинхронных уведомлений о событиях и эндпоинты, позволяющие программным компонентам подключаться к топику для отправки и получения этих сообщений.
- Чтобы передать сообщение, компонент, называемый издателем, просто отправляет сообщение в тему.
- Все компоненты, которые подписаны на тему (известные как подписчики), получают каждое сообщение, которое было передано.
Преимущества
Давайте обсудим некоторые преимущества использования модели "публикация-подписка":
- Исключение опросов: Темы сообщений позволяют мгновенную доставку на основе push, устраняя необходимость для потребителей сообщений периодически проверять или "опрашивать" новую информацию и обновления. Это способствует более быстрому времени реакции и снижает задержку доставки, что может быть особенно проблематично в системах, где задержки являются критичными.
- Динамическое определение цели: Pub/Sub упрощает обнаружение служб, делая его более естественным и менее ошибочным. Вместо того чтобы поддерживать реестр пиров, куда приложение может отправлять сообщения, издатель просто публикует сообщения в тему. Затем любая заинтересованная сторона подпишет свой эндпоинт на топик и начнет получать от него сообщения. Подписчики могут меняться, обновляться, появляться или исчезать, и система автоматически подстроится.
- Разрыв и независимость масштабирования: Издатели и подписчики разделены и работают независимо друг от друга, что позволяет нам разрабатывать и масштабировать их независимо.
- Упрощение коммуникации: Модель "публикация-подписка" уменьшает сложность, удаляя все point-to-point-соединения с единственным подключением к теме сообщений, которая управляет подписками и решает, какие сообщения должны быть доставлены на какие конечные точки.
Характеристики
Теперь давайте обсудим некоторые желательные характеристики модели "публикация-подписка":
Push-доставка
Система сообщений "публикация-подписка" мгновенно отправляет асинхронные уведомления о событиях при публикации сообщений в топик. Подписчики получают уведомление о доступности сообщения.
Множество протоколов доставки
В модели "публикация-подписка" темы обычно могут подключаться к нескольким типам эндпоинтов, таким как очереди сообщений, серверные функции, HTTP-серверы и т. д.
Fanout
Этот сценарий происходит, когда сообщение отправляется в тему, а затем реплицируется и отправляется на несколько конечных точек. Фанаут обеспечивает асинхронные уведомления о событиях, что в свою очередь позволяет выполнять параллельную обработку.
Фильтрация
Эта функция дает возможность подписчику создавать политику фильтрации сообщений, чтобы получать только те уведомления, которые его интересуют, в отличие от получения каждого отдельного сообщения, опубликованного в топике.
Надежность
Сервисы сообщений "публикация-подписка" часто обеспечивают очень высокую надежность и доставку хотя бы один раз, храня копии того же сообщения на нескольких серверах.
Безопасность
Темы сообщений аутентифицируют приложения, которые пытаются опубликовать контент, что позволяет использовать зашифрованные конечные точки и шифровать сообщения при передаче по сети.
Примеры
Вот примеры некоторых часто используемых publish-subscribe сервисов:
Корпоративная сервиса шина
An Enterprise Service Bus (ESB) - это архитектурный паттерн, при котором централизованный программный компонент осуществляет интеграцию между приложениями. Он выполняет преобразования моделей данных, обрабатывает соединения, выполняет маршрутизацию сообщений, преобразует протоколы связи и потенциально управляет составом нескольких запросов. ESB может сделать эти интеграции и преобразования доступными в качестве сервисного интерфейса для повторного использования новыми приложениями.

Преимущества
В теории централизованный ESB предлагает потенциал для стандартизации и существенного упрощения коммуникации, обмена сообщениями и интеграции между службами в предприятии. Вот некоторые преимущества использования ESB:
- Повышение производительности разработчиков: Позволяет разработчикам внедрять новые технологии в одной части приложения без изменения остальной части приложения.
- Проще, более экономически эффективное масштабирование: Компоненты могут масштабироваться независимо друг от друга.
- Большая надежность: Отказ одного компонента не влияет на другие, и каждый микросервис может придерживаться своих собственных требований к доступности без риска доступности других компонентов в системе.
Недостатки
Хотя ESB успешно внедрялись во многих организациях, во многих других организациях ESB начали восприниматься как узкое место. Вот некоторые недостатки использования ESB:
- Внесение изменений или улучшений в одну интеграцию может нарушить другие, которые используют ту же интеграцию.
- Одна точка отказа может привести к прекращению всех коммуникаций.
- Обновления ESB часто влияют на существующие интеграции, поэтому для выполнения любого обновления требуется значительное тестирование.
- ESB централизованно управляется, что затрудняет совместную работу между командами.
- Высокая сложность конфигурации и обслуживания.
Примеры
Ниже приведен список некоторых широкоиспользуемых Enterprise Service Bus (ESB):
Монолитная и Микросервисная архитектура
Монолит
Монолит - это самодостаточное независимое приложение. Оно собирается в виде одного единственного модуля отвечает не за одну какую-то задачу, а реализует весь функционал бизнес-логики целиком.
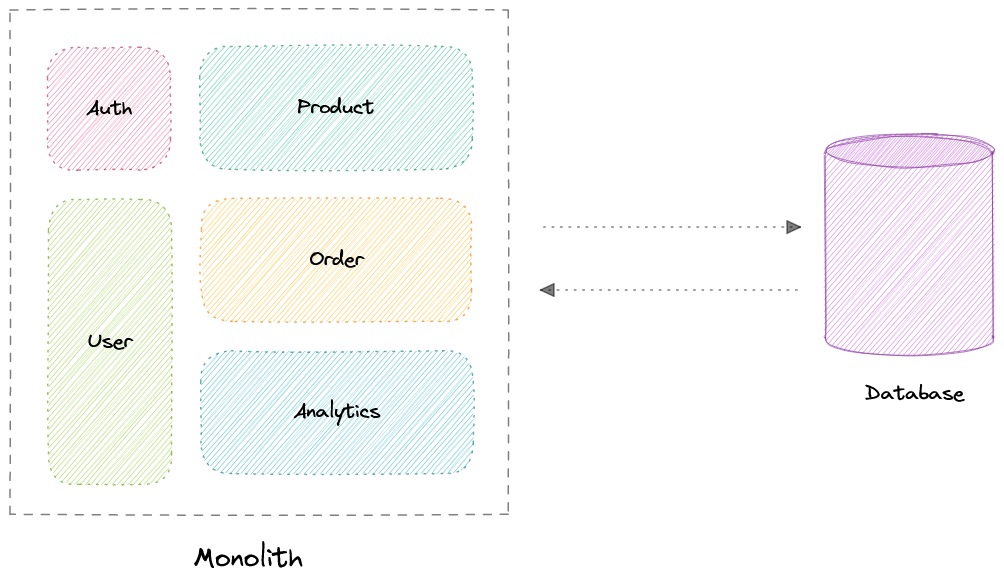
Преимущества
Вот некоторые преимущества монолитов:
- Простота разработки и отладки.
- Быстрая и надежная коммуникация.
- Легкое мониторинг и тестирование.
- Поддержка ACID-транзакций.
Недостатки
Некоторые распространенные недостатки монолитов:
- Усложняется обслуживание по мере роста кодовой базы.
- Плотно связанные приложения, трудно расширяемые.
- Требует приверженности к определенному стеку технологий.
- При каждом обновлении приложения полностью пересобирается.
- Снижается надежность, так как одна ошибка может привести к падению всей системы.
- Трудно масштабируется или принимает новые технологии.
Модульные монолиты
Модульный монолит - это подход, при котором мы строим и развертываем единственное приложение (это часть Монолита), но делаем это таким образом, что разбиваем код на независимые модули для каждой из функций, необходимых в нашем приложении.
Этот подход уменьшает зависимости модуля таким образом, что мы можем улучшить или изменить модуль, не затрагивая другие модули. Правильно выполненный, это может быть действительно полезным в долгосрочной перспективе, так как уменьшает сложность, связанную с поддержкой монолита по мере роста системы.
Микросервисы
Архитектура микросервисов состоит из набора маленьких, автономных служб, где каждая служба является самодостаточной и должна реализовывать одну бизнес-возможность в рамках ограниченного контекста. Ограниченный контекст - это естественное разделение бизнес-логики, которое обеспечивает явную границу, в пределах которой существует доменная модель.
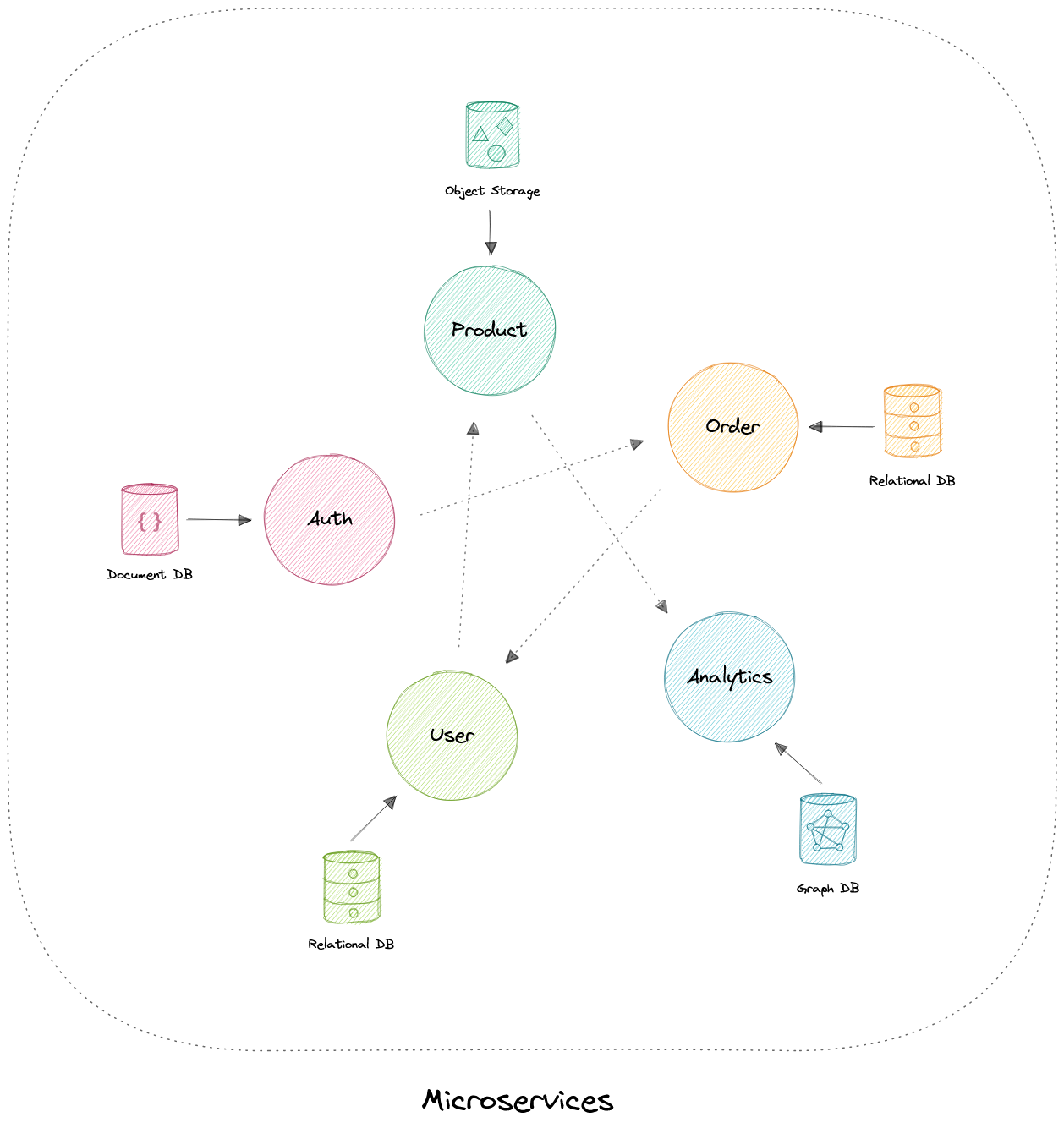
Каждый сервис имеет отдельную кодовую базу, которой может управлять небольшая команда разработчиков. Сервисы могут быть развернуты независимо, и команда может обновлять существующий сервис без пересборки и повторного развертывания всего приложения.
Сервисы отвечают за сохранение своих собственных данных или внешнего состояния (своя база данных для каждого сервиса). Это отличается от традиционной модели, где отдельный слой архитектуры отвечает за хранение данных.
Характеристики
Архитектура микросервисов имеет следующие характеристики:
- Слабая связность: Сервисы должны быть слабо связаны, чтобы их можно было независимо развертывать и масштабировать. Это приведет к децентрализации разработчиков и позволит им разрабатывать и разворачивать приложения быстрее с минимальными ограничениями и операционными зависимостями.
- Маленькие, но сфокусированные: Это не о размере, а о зоне ответственности, сервис должен быть сосредоточен на конкретной проблеме. В основном, "Он делает одну вещь и делает это хорошо". В идеале, они могут быть независимы от базовой архитектуры.
- Созданы для бизнеса: Архитектура микросервисов обычно организована вокруг бизнес возможностей и приоритетов.
- Устойчивость и Толерантность к сбоям: Сервисы должны быть спроектированы таким образом, чтобы они продолжали работать в случае сбоя или ошибок. В средах с независимо развертываемыми сервисами устойчивость к отказам имеет первостепенную важность.
- Высокая поддерживаемость: Сервисы должны быть легкими в обслуживании и тестировании, потому что сервисы, которые невозможно обслуживать, будут переписаны.
Преимущества
Вот несколько преимуществ архитектуры микросервисов:
- Слабая связь между сервисами.
- Сервисы могут быть развернуты независимо друг от друга.
- Высокая гибкость для нескольких команд разработки.
- Повышает устойчивость к сбоям и изоляцию данных.
- Лучшая масштабируемость, так как каждый сервис может масштабироваться независимо.
- Исключает долгосрочные обязательства по определенному стеку технологий.
Недостатки
Архитектура микросервисов несет свой набор проблем:
- Сложность распределенной системы.
- Тестирование более сложно.
- Дорого в обслуживании (отдельные серверы, базы данных и т. д.).
- Взаимосвязь между сервисами имеет свои собственные проблемы.
- Целостность и последовательность данных.
- Повышенная сетевая нагрузка и большие задержки.
Лучшие практики
Давайте обсудим некоторые лучшие практики микросервисов:
- Моделируйте сервисы вокруг бизнес-домена.
- Сервисы должны иметь слабую связь и высокую функциональную согласованность.
- Изолируйте сбои и используйте стратегии устойчивости, чтобы предотвратить распространение сбоев внутри сервиса.
- Сервисы должны общаться только через хорошо спроектированные API. Избегайте утечек деталей реализации.
- Хранение данных должно быть закрытым для сервиса, владеющего данными.
- Избегайте связи между сервисами. Причины связи включают в себя общие схемы баз данных и жесткие протоколы связи.
- Децентрализуйте все. Отдельные команды несут ответственность за проектирование и создание сервисов. Избегайте обмена кодом или схемами данных.
- Быстро откажитесь, используя переключатель для достижения устойчивости к сбоям.
- Обеспечьте обратную совместимость изменений в API.
Типичные ошибки
Ниже приведены некоторые распространенные типичные ошибки микросервисной архитектуры:
- Границы сервисов не основаны на бизнес-домене.
- Недооценка того, насколько сложно построить распределенную систему.
- Общие базы данных или общие зависимости между сервисами.
- Отсутствие выравнивания с бизнесом.
- Отсутствие ясной ответственности.
- Отсутствие идемпотентности.
- Попытка делать все ACID вместо BASE.
- Отсутствие проектирования для обеспечения устойчивости к сбоям может привести к каскадным сбоям.
Остерегайтесь распределенного монолита
Распределенный монолит - это система, которая напоминает архитектуру микросервисов, но тесно связана внутри себя, как монолитное приложение. Принятие архитектуры микросервисов приносит множество преимуществ. Но при ее создании существует большая вероятность того, что мы можем получить распределенный монолит.
Наши микросервисы являются распределенным монолитом, если верно хотя бы что-то из нижеперечисленного:
- Требуется обмен данными с низкой задержкой.
- Сервисы не масштабируются легко.
- Зависимость между сервисами.
- Общие ресурсы, такие как базы данных.
- Тесно связанные системы.
Одной из основных причин построения приложения с использованием архитектуры микросервисов является масштабируемость. Поэтому микросервисы должны иметь слабую связь, что позволяет каждому сервису быть независимым. Архитектура распределенного монолита лишает этого и заставляет большинство компонентов зависеть друг от друга, увеличивая сложность проектирования.
Микросервисы против Service-oriented architecture (SOA)
Вы могли видеть Service-oriented architecture (SOA) упоминаемую в Интернете, иногда даже взаимозаменяемо с микросервисами, но они отличаются друг от друга, и основное различие между двумя подходами сводится к области применения.
Service-oriented architecture (SOA) определяет способ сделать компоненты программного обеспечения повторно используемыми с помощью служебных интерфейсов. Эти интерфейсы используют общие стандарты коммуникации и ориентированы на максимизацию повторного использования служб приложения, тогда как микросервисы создаются как набор различных независимых сервисных блоков, сфокусированных на автономии команд и развязке.
В каких случаях микросервисы не нужны

Возможно, вы задаетесь вопросом: монолит, кажется, изначально плохая идея, почему кто-то может захотеть применять такую архитектуру?
Есть нюансы. Хотя у каждого подхода есть свои преимущества и недостатки, рекомендуется начинать с монолита при создании новой системы. Важно понимать, что микросервисы не являются универсальным средством, они решают организационную проблему. Архитектура микросервисов - это как организационные приоритеты и команда, так и технологии.
Прежде чем принять решение перейти на архитектуру микросервисов, вам следует задать себе вопросы, такие как:
- "Слишком ли большая команда для эффективной работы над общей кодовой базой?"
- "Заблокированы ли одни команды другими командами?"
- "Дают ли микросервисы явную бизнес-ценность для нас?"
- "Моя компания достаточно зрела для использования микросервисов?"
- "Ограничивает ли наша текущая архитектура нас избыточными коммуникациями?"
Если вашему приложению не требуется разделение на микросервисы, то вам это тоже не нужно. Нет абсолютной необходимости разделять все приложения на микросервисы.
Мы часто черпаем вдохновение из компаний, таких как Netflix, и их использование микросервисов, но мы упускаем из виду тот факт, что мы не Netflix. Они прошли через множество итераций и моделей, прежде чем у них появилось готовое к рынку решение, и эта архитектура стала приемлемой для них, когда они выявили и решили проблему, которую пытались решить.
Поэтому важно четко понимать, действительно ли вашему бизнесу нужны микросервисы. Что я пытаюсь сказать, микросервисы - это решения сложных проблем, и если у вашего бизнеса нет сложных проблем, вам это не нужно.
Event-Driven Architecture (EDA)
Event-Driven Architecture (EDA), заключается в использовании событий как способа общения в системе. Обычно для асинхронной публикации и получения событий используется брокер сообщений. Издатель не знает, кто получает событие, и получатели не знают друг о друге. Архитектура, основанная на событиях, просто способ достижения слабой связности между сервисами в системе.
Что такое событие?
Событие - это блок данных, представляющая изменения состояния в системе. Оно не указывает, что должно произойти и как изменение должно модифицировать систему, а только уведомляет систему о конкретном изменении состояния. Когда пользователь совершает действие, он инициирует событие.
Components
Event-driven архитектуры имеют три ключевых компонента:
- Event producers: Публикуют событие для диспетчера.
- Event routers: Фильтруют и отсылают события получателям.
- Event consumers: Используют события для отображения изменений в системе.
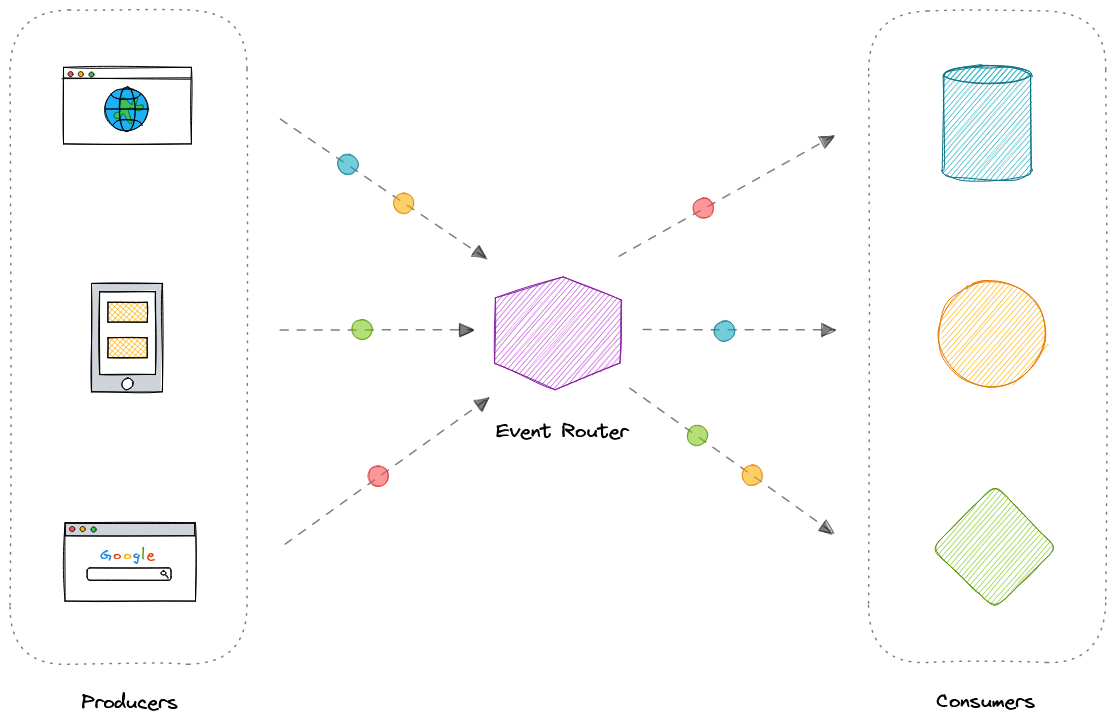
Note: Точки на диаграмме отражают различные события в системе.
Шаблоны
Есть несколько способов реализовать event-driven архитектуру, и то, какой метод стоит выбрать зависит от сценария использования, вот несколько распространенных вариантов:
Note: Каждый из этих методов обсуждается отдельно.
Преимущества
Давайте обсудим некоторые преимущества:
- Отделение производителей и потребителей.
- Высокая масштабируемость и децентрализация.
- Легкость добавления новых потребителей.
- Повышает гибкость.
Проблемы
Вот некоторые проблемы архитектуры, основанной на событиях:
- Гарантированная доставка.
- Обработка ошибок затруднительна.
- Системы, основанные на событиях, в целом сложны.
- Обработка событий с соблюдением порядка и однократного выполнения.
Сценарии использования
Ниже приведены некоторые общие сценарии использования, где архитектуры, основанные на событиях, являются выгодными:
- Метаданные и метрики.
- Логи сервера и безопасности.
- Интеграция разнородных систем.
- Распределенная обработка и параллельная обработка.
Примеры
Вот некоторые широко используемые технологии для реализации архитектур, основанных на событиях:
Генерация событий
Вместо хранения только текущего состояния данных в домене используйте хранилище только для добавления, чтобы записывать полную последовательность действий, выполненных с этими данными. Хранилище действует как система записи и может использоваться для материализации объектов предметной области.
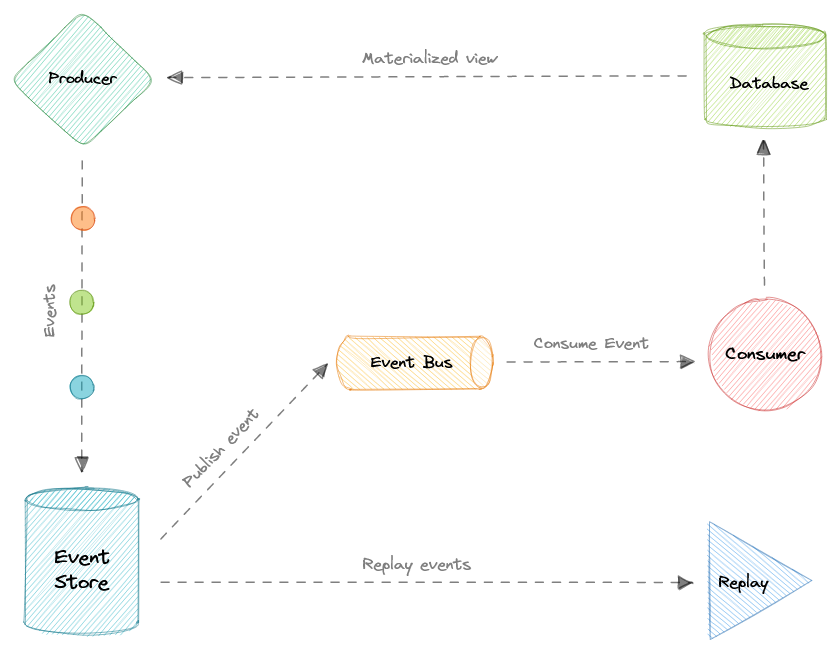
Это может упростить задачи в сложных областях, избегая необходимости синхронизации модели данных и бизнес-домена, при этом улучшая производительность, масштабируемость и отзывчивость. Это также может обеспечить согласованность для транзакционных данных и поддерживать полный журнал аудита и историю, что позволяет выполнять компенсационные действия.
Событийное хранилище против архитектуры, основанной на событиях (EDA)
Похоже, что событийное хранилище постоянно путают с архитектурой, основанной на событиях (EDA). Архитектура, основанная на событиях, заключается в использовании событий для общения между границами сервисов. Обычно используется брокер сообщений для асинхронной публикации и потребления событий в пределах других границ.
В то время как событийное хранилище заключается в использовании событий как состояния, что является другим подходом к хранению данных. Вместо хранения текущего состояния мы будем хранить события. Кроме того, событийное хранилище является одним из нескольких шаблонов для реализации архитектуры, основанной на событиях.
Преимущества
Давайте обсудим некоторые преимущества использования событийного хранилища:
- Отлично подходит для отчетности в реальном времени.
- Прекрасно подходит для обеспечения надежности: данные можно восстановить из хранилища событий.
- Крайне гибкое, можно хранить любой тип сообщений.
- Предпочтительный способ реализации функционала журналов аудита для высокоскоростных систем соблюдения.
Недостатки
Вот недостатки событийного хранилища:
- Требуется крайне эффективная сетевая инфраструктура.
- Требуется надежный способ контроля форматов сообщений, такой как реестр схем.
- Различные события могут содержать разные данные.
CQRS
Командно-запросное разделение обязанностей (CQRS) - это архитектурный шаблон, который разделяет действия системы на команды и запросы. Впервые он был описан Грегом Янгом.
В CQRS команда - это инструкция, директива для выполнения определенной задачи. Это намерение изменить что-то и не возвращает значение, только указание на успех или неудачу. А запрос - это запрос информации, который не изменяет состояние системы и не вызывает побочных эффектов.
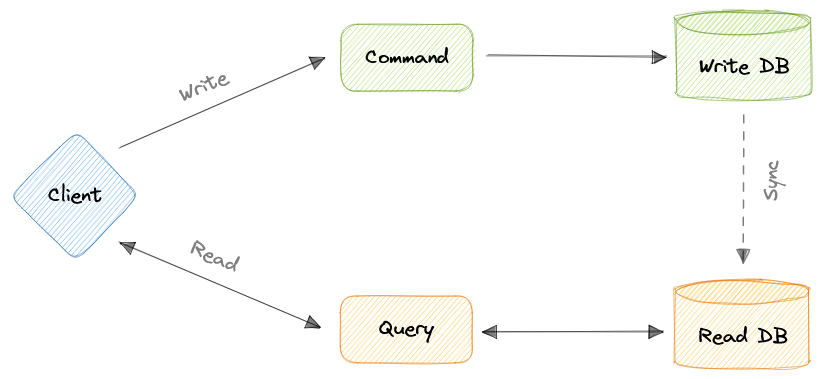
Основной принцип CQRS заключается в разделении команд и запросов. Они выполняют фундаментально разные роли в системе, и их разделение означает, что каждый из них может быть оптимизирован по мере необходимости, что действительно выгодно для распределенных систем.
CQRS с событийным хранилищем
Шаблон CQRS часто используется вместе с шаблоном событийного хранилища. Системы, основанные на CQRS, используют отдельные модели данных для чтения и записи, каждая из которых адаптирована к соответствующим задачам и часто расположены в физически разных хранилищах.
При использовании с шаблоном событийного хранилища хранилище событий является моделью записи и является официальным источником информации. Модель чтения системы, основанной на CQRS, предоставляет материализованные представления данных, обычно в виде сильно денормализованных представлений.
Преимущества
Давайте обсудим некоторые преимущества CQRS:
- Позволяет независимое масштабирование рабочей нагрузки для чтения и записи.
- Упрощает масштабирование, оптимизацию и изменения архитектуры.
- Ближе к бизнес-логике с слабой связью.
- Приложение может избежать сложных объединений при запросах.
- Четкие границы между поведением системы.
Недостатки
Вот некоторые недостатки CQRS:
- Более сложное проектирование приложения.
- Возможны сбои сообщений или дублирующиеся сообщения.
- Работа с потенциальной согласованностью - вызов.
- Увеличение усилий по обслуживанию системы.
Сценарии использования
Вот несколько сценариев, где CQRS будет полезен:
- Производительность чтения данных должна быть настроена отдельно от производительности записи данных.
- Ожидается, что система будет развиваться со временем и может содержать несколько версий модели или где бизнес-правила регулярно меняются.
- Интеграция с другими системами, особенно в сочетании с событийным хранилищем, где временный сбой одной подсистемы не должен влиять на доступность других.
- Улучшенная безопасность, чтобы гарантировать, что только правильные доменные сущности выполняют запись данных.
API шлюзы
API Gateway - это инструмент управления API, который находится между клиентом и коллекцией бэкэнд-сервисов. Это единственная точка входа в систему, которая инкапсулирует внутреннюю архитектуру системы и предоставляет API, настроенное под каждого клиента. Он также выполняет другие функции, такие как аутентификация, мониторинг, балансировка нагрузки, кэширование, ограничение скорости, ведение журнала и т. д.
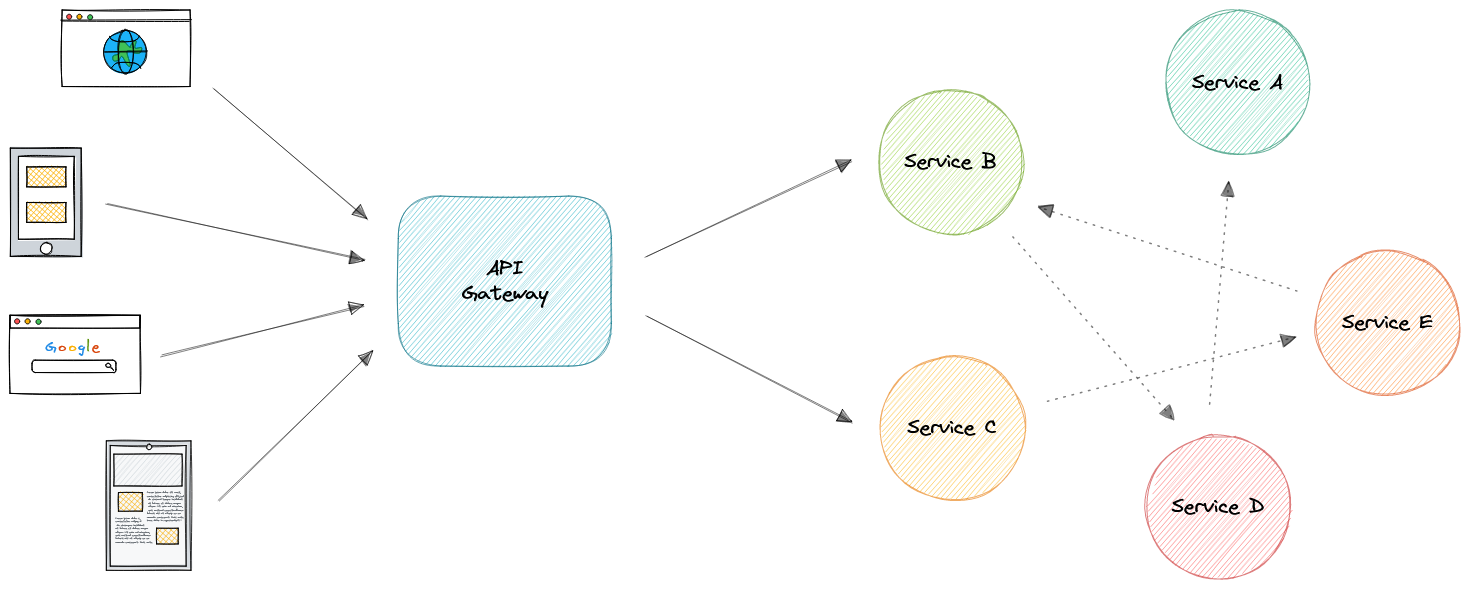
Зачем нам нужен API-шлюз?
Гранулярность API, предоставляемых микросервисами, часто отличается от того, что нужно клиенту. Микросервисы обычно предоставляют мелкозернистые API, что означает, что клиентам необходимо взаимодействовать с несколькими сервисами. Поэтому API-шлюз может обеспечить единый точку входа для всех клиентов с дополнительными функциями и лучшим управлением.
Функции
Ниже приведены некоторые желаемые функции API-шлюза:
- Аутентификация и авторизация
- Обнаружение сервисов
- Обратный прокси
- Кэширование
- Безопасность
- Повторы и контроль цепи
- Балансировка нагрузки
- Логирование, трассировка
- Компоновка API
- Ограничение скорости и управление пропускной способностью
- Версионирование
- Маршрутизация
- Белый или черный список IP-адресов
Преимущества
Давайте рассмотрим некоторые преимущества использования API-шлюза:
- Инкапсулирует внутреннюю структуру API.
- Предоставляет централизованный вид на API.
- Упрощает код клиента.
- Мониторинг, аналитика, трассировка и другие подобные функции.
Недостатки
Вот некоторые возможные недостатки API-шлюза:
- Возможная единственная точка отказа.
- Может повлиять на производительность.
- Может стать узким местом, если не масштабировать правильно.
- Настройка может быть сложной.
Шаблон "Backend For Frontend" (BFF)
В шаблоне "Backend For Frontend" (BFF) мы создаем отдельные бэкэнд-сервисы для использования конкретными интерфейсами или приложениями. Этот шаблон полезен, когда мы хотим избежать настройки одного бэкэнда для нескольких интерфейсов. Этот шаблон был впервые описан Сэмом Ньюманом.
Иногда вывод данных, возвращаемых микросервисами на фронтенд, не соответствует требуемому формату или не фильтруется, как нужно фронтенду. Для решения этой проблемы фронтенд должен иметь некоторую логику для повторной форматировки данных, и поэтому мы можем использовать BFF для перемещения некоторой этой логики на промежуточный уровень.

Основная функция шаблона "Backend For Frontend" (BFF) заключается в получении необходимых данных из соответствующего сервиса, форматировании данных и их отправке на фронтенд.
GraphQL отлично подходит в качестве бэкэнда для фронтенда (BFF).
Когда использовать этот шаблон?
Мы должны рассмотреть использование шаблона "Backend For Frontend" (BFF), когда:
- Необходимо поддерживать общий или универсальный бэкэнд-сервис с значительными накладными расходами на разработку.
- Мы хотим оптимизировать бэкэнд под требования конкретного клиента.
- В общий универсальный бэкэнд вносятся изменения, чтобы адаптировать его под несколько интерфейсов.
Примеры
Вот некоторые широко используемые технологии шлюзов:
REST, GraphQL, gRPC
Хороший дизайн API всегда является ключевой частью любой системы. Но также важно выбрать правильную технологию API. Итак, в этом руководстве мы кратко обсудим различные технологии API, такие как REST, GraphQL и gRPC.
Что такое API?
Прежде чем мы вообще начнем говорить о технологиях API, давайте сначала разберемся, что такое API.
API означает Application Programming Interface. Это набор определений и протоколов для создания и интеграции прикладного программного обеспечения. Иногда его называют контрактом между поставщиком информации и пользователем информации, устанавливающим содержание, необходимое от производителя, и содержание, необходимое потребителю.
Другими словами, если вы хотите взаимодействовать с компьютером или системой для извлечения информации или выполнения функции, API помогает вам передать этому системе то, что вы хотите, чтобы она поняла и выполнела запрос.
REST
REST API (также известный как RESTful API) - это интерфейс прикладного программирования, который соответствует ограничениям архитектурного стиля REST и позволяет взаимодействовать с RESTful веб-сервисами. REST означает Representational State Transfer и был впервые представлен Роем Филдингом в 2000 году.
В REST API фундаментальной единицей является ресурс.
Концепции
Давайте обсудим некоторые концепции RESTful API.
Ограничения
Чтобы API могло считаться RESTful, оно должно соответствовать следующим архитектурным ограничениям:
- Единый интерфейс: Должен существовать единый способ взаимодействия с данным сервером.
- Клиент-Сервер: Архитектура клиент-сервер управляется через HTTP.
- Без состояния: На сервере не должно храниться состояние клиента между запросами.
- Кэшируемость: Каждый ответ должен содержать информацию о том, является ли ответ кэшируемым или нет, и на какой период времени ответы могут быть закэшированы на стороне клиента.
- Слоистая система: Архитектура приложения должна быть составлена из нескольких уровней.
- Код по требованию: Возвращать исполняемый код для поддержки части вашего приложения. (необязательно)
HTTP-глаголы
HTTP определяет набор методов запроса, чтобы указать желаемое действие для заданного ресурса. Хотя они также могут быть существительными, эти методы запроса иногда называют HTTP-глаголами. Каждый из них реализует разную семантику, но некоторые общие функции разделяются группой из них.
Ниже приведены некоторые часто используемые HTTP-глаголы:
- GET: Запрашивает представление указанного ресурса.
- HEAD: Ответ идентичен запросу
GET, но без тела ответа. - POST: Отправляет сущность на указанный ресурс, часто вызывая изменение состояния или побочные эффекты на сервере.
- PUT: Заменяет все текущие представления целевого ресурса данными запроса.
- DELETE: Удаляет указанный ресурс.
- PATCH: Применяет частичные модификации к ресурсу.
Коды ответов HTTP
Коды состояния ответа HTTP указывают, был ли успешно завершен определенный HTTP-запрос.
Стандарт определяет пять классов:
- 1xx - Информационные ответы.
- 2xx - Успешные ответы.
- 3xx - Ответы о перенаправлении.
- 4xx - Ошибки клиента.
- 5xx - Ошибки сервера.
Например, HTTP 200 означает, что запрос был успешным.
Преимущества
Давайте обсудим некоторые преимущества REST API:
- Простой и понятный.
- Гибкий и переносимый.
- Хорошая поддержка кэширования.
- Клиент и сервер разнесены в пространстве.
Недостатки
Давайте обсудим некоторые недостатки REST API:
- Избыточное получение данных.
- Иногда требуются несколько обращений к серверу.
Сценарии использования
REST API используются практически всюду и являются стандартом по умолчанию для проектирования API. В целом REST API достаточно гибки и могут подходить практически ко всем сценариям.
Пример
Вот пример использования REST API, который работает с ресурсом пользователей.
| URI | HTTP-глагол | Описание |
|---|---|---|
| /users | GET | Получить всех пользователей |
| /users/{id} | GET | Получить пользователя по идентификатору |
| /users | POST | Добавить нового пользователя |
| /users/{id} | PATCH | Обновить пользователя по идентификатору |
| /users/{id} | DELETE | Удалить пользователя по идентификатору |
Есть так много, что можно узнать о REST API, я настоятельно рекомендую изучить Hypermedia as the Engine of Application State (HATEOAS).
GraphQL
GraphQL - это язык запросов и серверный рантайм для API, который приоритизирует предоставление клиентам ровно тех данных, которые они запрашивают, и ни больше. Он был разработан Facebook и позже был опубликован как open-source в 2015 году.
GraphQL разработан для создания быстрых, гибких и удобных для разработчиков API. Кроме того, GraphQL дает разработчикам API гибкость добавлять или устаревать поля без влияния на существующие запросы. Разработчики могут создавать API с использованием любых методов, которые им нравятся, и спецификация GraphQL гарантирует, что они будут функционировать в предсказуемых для клиентов способах.
В GraphQL фундаментальной единицей является запрос.
Концепции
Давайте кратко обсудим некоторые ключевые концепции в GraphQL:
Схема
Схема GraphQL описывает функциональность, которую клиенты могут использовать после подключения к серверу GraphQL.
Запросы
Запрос - это запрос, сделанный клиентом. Он может состоять из полей и аргументов для запроса. Тип операции запроса также может быть мутацией, которая предоставляет способ изменять данные на стороне сервера.
Резолверы
Резолвер - это набор функций, которые генерируют ответы на запрос GraphQL. Простыми словами, резолвер действует как обработчик запроса GraphQL.
Преимущества
Давайте обсудим некоторые преимущества GraphQL:
- Исключает избыточное получение данных.
- Сильно определенная схема.
- Поддержка генерации кода.
- Оптимизация нагрузки.
Недостатки
Давайте обсудим некоторые недостатки GraphQL:
- Переносит сложность на сторону сервера.
- Кэширование становится сложным.
- Неоднозначность при версионировании.
- Проблема N+1.
Сценарии использования
GraphQL оказывается важным в следующих сценариях:
- Сокращение использования полосы пропускания приложением, поскольку мы можем запрашивать несколько ресурсов одним запросом.
- Быстрое прототипирование сложных систем.
- Когда мы работаем с моделью данных, похожей на граф.
Пример
Вот схема GraphQL, которая определяет тип User и тип Query.
type Query {
getUser: User
}
type User {
id: ID
name: String
city: String
state: String
}
Используя вышеуказанную схему, клиент может легко запросить необходимые поля, не загружая всего ресурса или не догадываясь о том, что может вернуть API.
{
getUser {
id
name
city
}
}
Это даст следующий ответ клиенту.
{
"getUser": {
"id": 123,
"name": "Karan",
"city": "San Francisco"
}
}
Узнайте больше о GraphQL на graphql.org.
gRPC
gRPC - это современный открытый высокопроизводительный Remote Procedure Call (RPC) фреймворк, который может работать в любой среде. Он эффективно соединяет службы внутри и между центрами обработки данных с поддержкой подключаемых модулей для балансировки нагрузки, трассировки, проверки состояния, аутентификации и многого другого.
Концепции
Давайте обсудим некоторые ключевые концепции gRPC.
Протокольные буферы
Протокольные буферы предоставляют языково- и платформонезависимый механизм для сериализации структурированных данных в обратно и вперед совместимом формате. Это похоже на JSON, за исключением того, что оно меньше по размеру и быстрее, а также генерирует привязки к языкам программирования.
Определение службы
Как и многие другие системы RPC, gRPC основан на идее определения службы и указания методов, которые могут быть вызваны удаленно с их параметрами и типами возвращаемых значений. gRPC использует протокольные буферы в качестве языка описания интерфейса (IDL) для описания как интерфейса службы, так и структуры сообщений данных.
Преимущества
Давайте обсудим некоторые преимущества gRPC:
- Легковесность и эффективность.
- Высокая производительность.
- Встроенная поддержка генерации кода.
- Двунаправленный поток данных.
Недостатки
Давайте обсудим некоторые недостатки gRPC:
- Относительно новый по сравнению с REST и GraphQL.
- Ограниченная поддержка браузера.
- Более крутой кривой обучения.
- Не читаем для человека.
Сценарии использования
Ниже приведены некоторые хорошие сценарии использования gRPC:
- Реальное время общение через двунаправленный поток.
- Эффективное межсервисное взаимодействие в микросервисах.
- Низкая задержка и высокая пропускная способность общения.
- Полиглотные среды.
Пример
Вот базовый пример службы gRPC, определенной в файле *.proto. Используя эту определение, мы легко можем сгенерировать код службы HelloService на языке программирования нашего выбора.
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string greeting = 1;
}
message HelloResponse {
string reply = 1;
}
REST vs GraphQL vs gRPC
Теперь, когда мы знаем, как работают эти техники проектирования API, давайте сравним их на основе следующих параметров:
- Будет ли это вызывать тесную связь?
- Насколько многообещающими (различные вызовы API, чтобы получить нужную информацию) являются API?
- Какова производительность?
- Насколько сложно интегрировать?
- Насколько хорошо работает кэширование?
- Есть ли встроенные инструменты и генерация кода?
- Каково обнаружение API?
- Насколько легко версионировать API?
| Тип | Связь | Многообещание | Производительность | Сложность | Кэширование | Генерация кода | Обнаружение | Версионность |
|---|---|---|---|---|---|---|---|---|
| REST | Низкая | Высокое | Хорошая | Средняя | Отличное | Плохая | Хорошее | Легко |
| GraphQL | Средняя | Низкое | Хорошая | Высокая | Пользовательское | Хорошая | Хорошее | Пользовательское |
| gRPC | Высокая | Среднее | Отличная | Низкая | Пользовательское | Отличная | Плохое | Трудно |
Какая технология API лучше?
Честно говоря, ни одна из них. Нет универсального решения, поскольку каждая из этих технологий имеет свои преимущества и недостатки. Пользователи заботятся только о том, чтобы использовать наши API согласованным образом, поэтому обязательно сосредотачивайтесь на вашем домене и требованиях при проектировании вашего API.
Long polling, WebSockets, Server-Sent Events (SSE)
Веб-приложения изначально были разработаны вокруг модели клиент-сервер, где веб-клиент всегда является инициатором транзакций, таких как запрос данных с сервера. Таким образом, не было механизма для того, чтобы сервер самостоятельно отправлял или передавал данные клиенту без того, чтобы клиент сначала отправил запрос. Давайте обсудим некоторые подходы для преодоления этой проблемы.
Длинные запросы
HTTP длинные запросы - это техника, используемая для отправки информации клиенту как можно скорее от сервера. В результате серверу не нужно ждать, пока клиент отправит запрос.
При длинных запросах сервер не закрывает соединение, как только он получает запрос от клиента. Вместо этого сервер отвечает только в случае наличия нового сообщения или достижения порога тайм-аута.
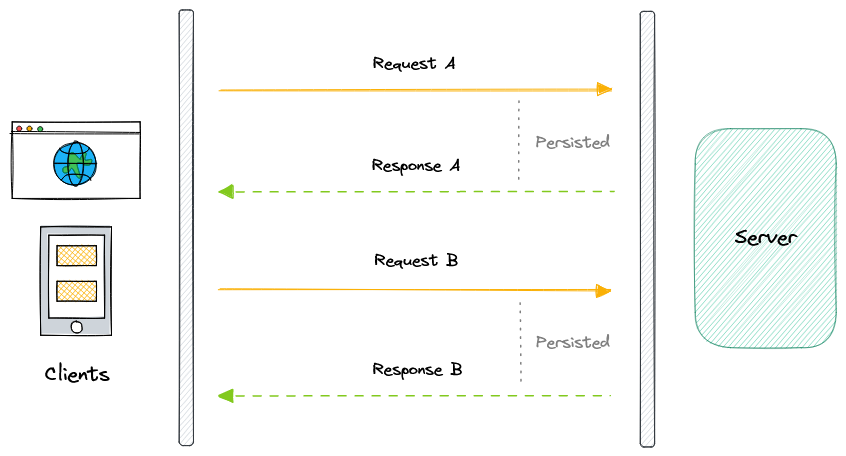
Как только клиент получает ответ, он сразу отправляет новый запрос серверу, чтобы иметь новое ожидающее соединение для отправки данных клиенту, и операция повторяется. При таком подходе сервер эмулирует функцию реального времени.
Работа
Давайте разберем, как работает длинный запрос:
- Клиент отправляет начальный запрос и ожидает ответа.
- Сервер получает запрос и задерживает отправку чего-либо, пока обновление не будет доступно.
- Как только обновление становится доступным, ответ отправляется клиенту.
- Клиент получает ответ и сразу отправляет новый запрос или после определенного интервала, чтобы установить соединение снова.
Преимущества
Вот некоторые преимущества длинных запросов:
- Легко реализуемы, хороши для небольших проектов.
- Практически универсально поддерживаемы.
Недостатки
Основным недостатком длинных запросов является то, что они обычно не масштабируются. Вот еще несколько причин:
- Создает новое соединение каждый раз, что может быть нагрузочным для сервера.
- Надежная упорядоченность сообщений может быть проблемой при множественных запросах.
- Увеличенная задержка, так как сервер должен ждать нового запроса.
WebSockets
WebSocket предоставляет двусторонние коммуникационные каналы через одно соединение TCP. Это постоянное соединение между клиентом и сервером, которое обе стороны могут использовать для начала отправки данных в любое время.
Клиент устанавливает соединение WebSocket через процесс, известный как рукопожатие WebSocket. Если процесс завершается успешно, то сервер и клиент могут обмениваться данными в обе стороны в любое время. Протокол WebSocket обеспечивает коммуникацию между клиентом и сервером с более низкими накладными расходами, облегчая передачу данных в реальном времени от и к серверу.
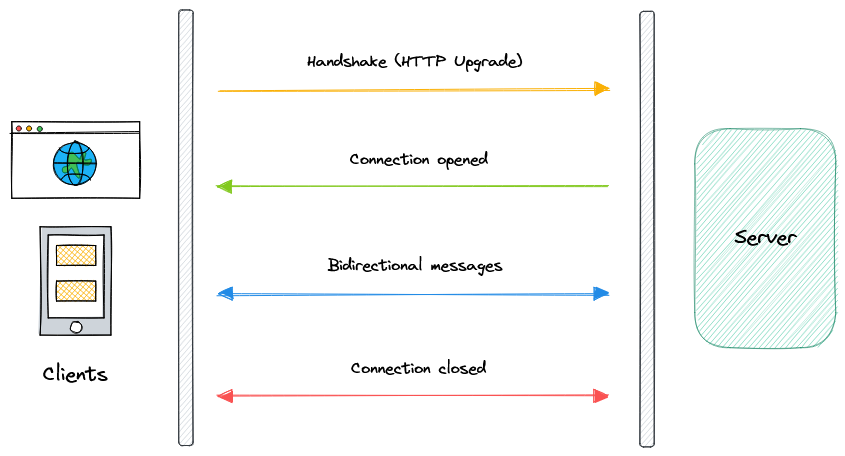
Принцип работы
Давайте поймем, как работают веб-сокеты:
- Клиент инициирует процесс рукопожатия WebSocket, отправляя запрос.
- Запрос также содержит заголовок HTTP Upgrade, который позволяет переключить запрос на протокол WebSocket (
ws://). - Сервер отправляет ответ клиенту, подтверждая запрос рукопожатия WebSocket.
- WebSocket-соединение будет открыто, как только клиент получит успешный ответ на рукопожатие.
- Теперь клиент и сервер могут начать отправлять данные в обоих направлениях, позволяя реальному времени общения.
- Соединение закрывается, как только сервер или клиент решают закрыть его.
Преимущества
Ниже приведены некоторые преимущества веб-сокетов:
- Полудуплексная асинхронная передача сообщений.
- Лучшая модель безопасности на основе происхождения.
- Легкий для клиента и сервера.
Недостатки
Давайте обсудим некоторые недостатки веб-сокетов:
- Прерванные соединения не восстанавливаются автоматически.
- Старые браузеры не поддерживают веб-сокеты (становятся менее актуальными).
Server-Sent Events (SSE)
Server-Sent Events (SSE) - это способ установления долгосрочного общения между клиентом и сервером, который позволяет серверу активно отправлять данные клиенту.
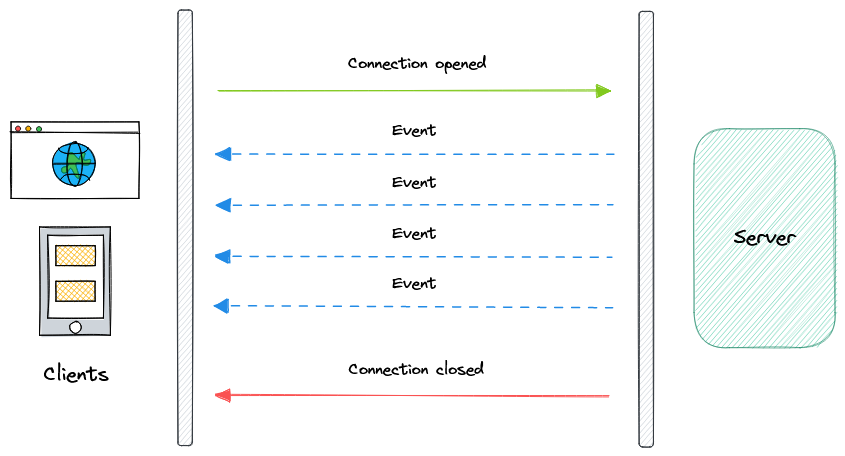
Это однонаправленное соединение, что означает, что после того, как клиент отправил запрос, он может только получать ответы без возможности отправлять новые запросы через то же самое соединение.
Принцип работы
Давайте поймем, как работают события, отправляемые сервером:
- Клиент делает запрос на сервер.
- Устанавливается соединение между клиентом и сервером, и оно остается открытым.
- Сервер отправляет ответы или события клиенту, когда новые данные доступны.
Преимущества
- Простота в реализации и использовании как для клиента, так и для сервера.
- Поддерживается большинством браузеров.
- Нет проблем с брандмауэрами.
Недостатки
- Однонаправленная природа может быть ограничивающей.
- Ограничение на максимальное количество открытых соединений.
- Не поддерживает двоичные данные.
Геохеширование и Деревья квадрантов
Геохеширование
Геохеширование - это метод геокодирования, используемый для кодирования географических координат, таких как широта и долгота, в короткие алфанумерические строки. Он был создан Густаво Ниемеером в 2008 году.
Например, Сан-Франциско с координатами 37.7564, -122.4016 может быть представлен в виде геохеша как 9q8yy9mf.
Как работает геохеширование?
Геохеш - это иерархический пространственный индекс, который использует кодирование алфавитом Base-32, первый символ в геохеше идентифицирует начальное местоположение как одну из 32 ячеек. Эта ячейка также будет содержать 32 ячейки. Это означает, что для представления точки мир рекурсивно делится на все более мелкие ячейки с каждым дополнительным битом, пока не будет достигнута желаемая точность. Фактор точности также определяет размер ячейки.

Геохеширование гарантирует, что точки пространственно ближе, если их геохеши имеют общий более длинный префикс, что означает, что чем больше символов в строке, тем более точное местоположение. Например, геохеши 9q8yy9mf и 9q8yy9vx пространственно ближе, так как они имеют общий префикс 9q8yy9.
Геохеширование также может использоваться для обеспечения степени анонимности, поскольку нам не нужно раскрывать точное местоположение пользователя, потому что в зависимости от длины геохеша мы просто знаем, что они находятся где-то в области.
Размеры ячеек геохешей различной длины следующие:
| Длина геохеша | Ширина ячейки | Высота ячейки |
|---|---|---|
| 1 | 5000 км | 5000 км |
| 2 | 1250 км | 1250 км |
| 3 | 156 км | 156 км |
| 4 | 39.1 км | 19.5 км |
| 5 | 4.89 км | 4.89 км |
| 6 | 1.22 км | 0.61 км |
| 7 | 153 м | 153 м |
| 8 | 38.2 м | 19.1 м |
| 9 | 4.77 м | 4.77 м |
| 10 | 1.19 м | 0.596 м |
| 11 | 149 мм | 149 мм |
| 12 | 37.2 мм | 18.6 мм |
Применение
Вот некоторые распространенные применения геохеширования:
- Это простой способ представления и сохранения местоположения в базе данных.
- Его также можно делить в социальных сетях как URL, так как это проще делиться и запоминать, чем широта и долгота.
- Мы можем быстро найти ближайших соседей точки через простое сравнение строк и быстрый поиск в индексах.
Примеры
Геохеширование широко используется и поддерживается популярными базами данных.
Кваддеревья
Кваддерево - это древовидная структура данных, в которой каждый внутренний узел имеет ровно четыре дочерних узла. Они часто используются для разделения двумерного пространства путем рекурсивного его подразделения на четыре квадранта или региона. Каждый дочерний или листовой узел хранит пространственную информацию. Кваддеревья являются двумерным аналогом октодеревьев, которые используются для разделения трехмерного пространства.
Типы кваддеревьев
Кваддеревья могут быть классифицированы в зависимости от типа данных, которые они представляют, включая области, точки, линии и кривые. Ниже приведены распространенные типы кваддеревьев:
- Кваддеревья точек
- Кваддеревья точка-регион (PR)
- Полигональные карты (PM) кваддеревьев
- Сжатые кваддеревья
- Кваддеревья ребер
Зачем нам нужны кваддеревья?
Разве широты и долготы недостаточны? Зачем нам кваддеревья? Хотя в теории, используя широту и долготу, мы можем определить такие вещи, как близость точек друг к другу, используя евклидово расстояние, для практических случаев использование этого просто не масштабируется из-за его вычислительно интенсивного характера с большими объемами данных.

Кваддеревья позволяют нам эффективно искать точки в двумерном диапазоне, где эти точки определяются координатами широты/долготы или как декартовы (x, y) координаты. Кроме того, мы можем сэкономить дальнейшие вычисления, разделив узел только после определенного порога. И с применением алгоритмов сопоставления, таких как кривая Хилберта, мы легко можем улучшить производительность запроса диапазона.
Примеры использования
Ниже приведены некоторые распространенные случаи использования кваддеревьев:
- Представление изображений, их обработка и сжатие.
- Пространственный индексирование и запросы диапазонов.
- Сервисы на основе местоположения, такие как Google Maps, Uber и т. д.
- Генерация сеток и компьютерная графика.
- Хранение разреженных данных.
Автопредохранитель
Отключение цепи - это шаблон проектирования, используемый для обнаружения сбоев и инкапсуляции логики предотвращения повторяющихся сбоев во время обслуживания, временных сбоев во внешней системе или непредвиденных трудностей системы.
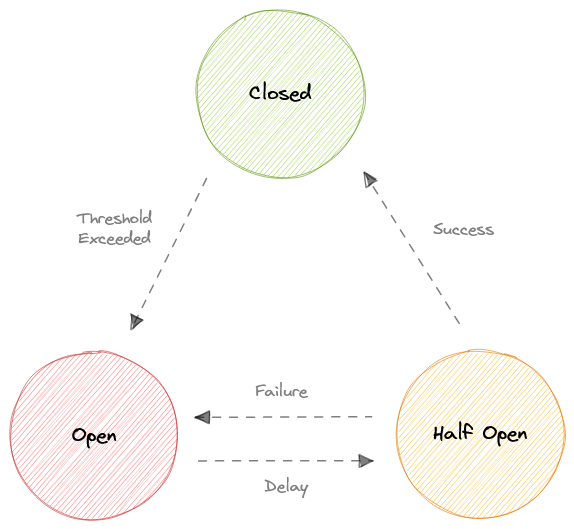
Основная идея, лежащая в основе отключения цепи, очень проста. Мы оборачиваем защищенный вызов функции в объект отключения цепи, который отслеживает сбои. Как только количество сбоев достигает определенного порога, отключение цепи срабатывает, и все последующие вызовы отключения цепи возвращаются с ошибкой, даже без выполнения защищенного вызова. Обычно мы также хотим получать какие-то уведомления в случае срабатывания отключения цепи.
Зачем нам нужно отключение цепи?
Часто программные системы выполняют удаленные вызовы к программному обеспечению, работающему в разных процессах, вероятно, на разных машинах по сети. Одна из больших разниц между вызовами в памяти и удаленными вызовами заключается в том, что удаленные вызовы могут завершаться неудачей или повисать без ответа до достижения какого-либо временного предела ожидания. Еще хуже, если у нас много вызывающих на нереагирующем поставщике, то мы можем исчерпать критические ресурсы, что приведет к каскадным сбоям по всей системе.
Состояния
Давайте обсудим состояния отключения цепи:
Закрыт
Когда все нормально, отключения цепи остаются закрытыми, и все запросы проходят к сервисам как обычно. Если количество сбоев превышает порог, отключение цепи срабатывает и переходит в открытое состояние.
Открыт
В этом состоянии отключение цепи немедленно возвращает ошибку, даже не вызывая сервисы. Отключения цепи переходят в состояние полуоткрытого после истечения определенного периода времени ожидания. Обычно будет настроена система мониторинга, где будет указано время ожидания.
Полуоткрытый
В этом состоянии отключение цепи позволяет ограниченному количеству запросов от сервиса пройти и выполнить операцию. Если запросы успешны, то отключение цепи перейдет в закрытое состояние. Однако, если запросы продолжают неудачными, то оно возвращается в открытое состояние.
Rate Limiting
Ограничение скорости относится к предотвращению частоты выполнения операции сверх заданного предела. В крупных системах ограничение скорости часто используется для защиты базовых сервисов и ресурсов. Ограничение скорости обычно используется в качестве защитного механизма в распределенных системах, чтобы общие ресурсы могли поддерживать доступность. Оно также защищает наши API от непреднамеренного или злонамеренного чрезмерного использования, ограничивая количество запросов, которые могут достигнуть нашего API за определенный период времени.
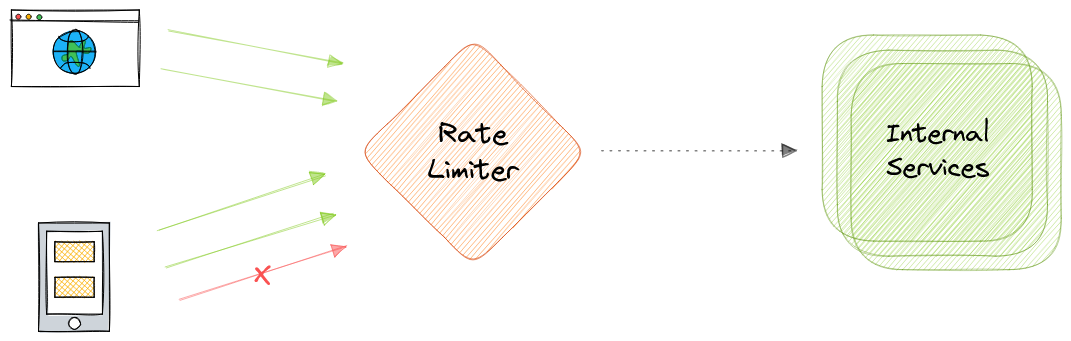
Зачем нам нужно ограничение скорости?
Ограничение скорости является очень важной частью любой крупномасштабной системы и может использоваться для достижения следующих целей:
- Избегание истощения ресурсов в результате атаки отказа в обслуживании (DoS).
- Ограничение скорости помогает контролировать операционные затраты, устанавливая виртуальный предел на масштабирование ресурсов, что, если не контролировать, может привести к экспоненциальным счетам.
- Ограничение скорости может использоваться в качестве защиты или смягчения некоторых общих атак.
- Для API, обрабатывающих огромные объемы данных, ограничение скорости может использоваться для контроля потока этих данных.
Алгоритмы
Существуют различные алгоритмы ограничения скорости API, у каждого из которых есть свои преимущества и недостатки. Давайте кратко обсудим некоторые из этих алгоритмов:
"Течущий" ведро (Leaky Bucket)
"Течущий" ведро - это алгоритм, который обеспечивает простой, интуитивно понятный подход к ограничению скорости с помощью очереди. При регистрации запроса система добавляет его в конец очереди. Обработка первого элемента в очереди происходит через определенный интервал времени или по принципу "первым пришел - первым обслужен" (FIFO). Если очередь заполнена, то дополнительные запросы отбрасываются (или "утекают").
"Мешок" токенов (Token Bucket)
Здесь мы используем концепцию ведра. Когда поступает запрос, из ведра должен быть взят токен и обработан. Если в ведре нет доступных токенов, то запрос будет отклонен, и отправитель должен будет повторить попытку позже. После определенного временного периода ведро токенов обновляется.
Фиксированное окно (Fixed Window)
Система использует размер окна в n секунд для отслеживания скорости алгоритма фиксированного окна. Каждый входящий запрос увеличивает счетчик для окна. Запрос отклоняется, если счетчик превышает пороговое значение.
Скользящий журнал (Sliding Log)
Ограничение скорости на основе скользящего журнала включает отслеживание временно отмеченного журнала для каждого запроса. Система хранит эти журналы в сортированном по времени хэш-наборе или таблице. Она также отбрасывает журналы с отметками времени, выходящими за пределы порога. Когда поступает новый запрос, мы вычисляем сумму журналов, чтобы определить скорость запроса. Если запрос превысил бы пороговую скорость, то он задерживается.
Скользящее окно (Sliding Window)
Скользящее окно - это гибридный подход, который объединяет низкую стоимость обработки алгоритма фиксированного окна и улучшенные граничные условия скользящего журнала. Как и в алгоритме фиксированного окна, мы отслеживаем счетчик для каждого фиксированного окна. Затем мы учитываем взвешенное значение скорости запроса предыдущего окна на основе текущей отметки времени, чтобы сгладить всплески трафика.
Ограничение скорости в распределенных системах
Ограничение скорости становится сложным, когда в процессе участвуют распределенные системы. Два основных проблемных аспекта ограничения скорости в распределенных системах:
Несогласованность
При использовании кластера из нескольких узлов может потребоваться применение глобальной политики ограничения скорости. Поскольку, если каждый узел отслеживает свое ограничение скорости, потребитель может превысить глобальное ограничение скорости при отправке запросов к разным узлам. Чем больше узлов, тем выше вероятность того, что пользователь превысит глобальный предел.
Простейший способ решения этой проблемы - использовать "приклеенные" сессии в наших балансировщиках нагрузки, чтобы каждому потребителю был отправлен ровно один узел, но это вызывает недостаток устойчивости к сбоям и проблемы масштабирования. Другой подход может заключаться в использовании централизованного хранилища данных, такого как Redis, но это увеличит задержку и вызовет состязательные ситуации.
Состязательные ситуации
Эта проблема возникает, когда мы используем наивный подход "получить-затем-установить", при котором мы извлекаем текущий счетчик ограничения скорости, увеличиваем его, а затем возвращаем его обратно в хранилище данных. Проблема этой модели заключается в том, что дополнительные запросы могут поступить во время выполнения полного цикла чтения-увеличения-сохранения, каждый из которых пытается сохранить увеличенное значение счетчика с недействительным (меньшим) значением счетчика. Это позволяет потребителю отправить очень большое количество запросов, обходя контроль ограничения скорости.
Один из способов избежать этой проблемы - использовать некоторый механизм распределенной блокировки вокруг ключа, предотвращая доступ или запись к счетчику другим процессам. Хотя блокировка станет значительным узким местом и плохо масштабируется. Более хороший подход может заключаться в использовании подхода "установить-затем-получить", позволяющего нам быстро увеличивать и проверять значения счетчика без препятствий атомарных операций.
Service Discovery
Обнаружение сервисов - это выявление сервисов в компьютерной сети. Протокол обнаружения сервисов (Service Discovery Protocol, SDP) является сетевым стандартом, который обеспечивает обнаружение сетей путем идентификации ресурсов.
Зачем нам нужно обнаружение сервисов?
В монолитном приложении сервисы вызывают друг друга через методы на уровне языка или вызовы процедур. Однако современные приложения, основанные на микросервисах, обычно запускаются в виртуализированных или контейнеризованных средах, где количество экземпляров сервиса и их местоположение динамически изменяются. Следовательно, нам нужен механизм, который позволяет клиентам сервиса делать запросы к динамически изменяющемуся набору временных экземпляров сервиса.
Реализации
Существуют две основные модели обнаружения сервисов:
Обнаружение на стороне клиента
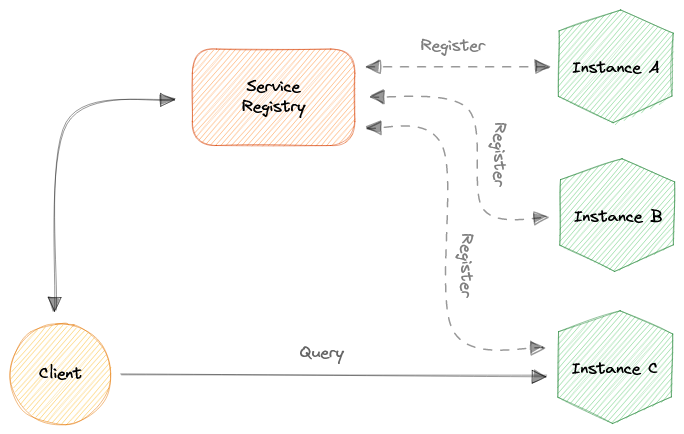
В этом подходе клиент получает местоположение другого сервиса, обратившись к реестру сервисов, который отвечает за управление и хранение сетевых местоположений всех сервисов.
Обнаружение на стороне сервера
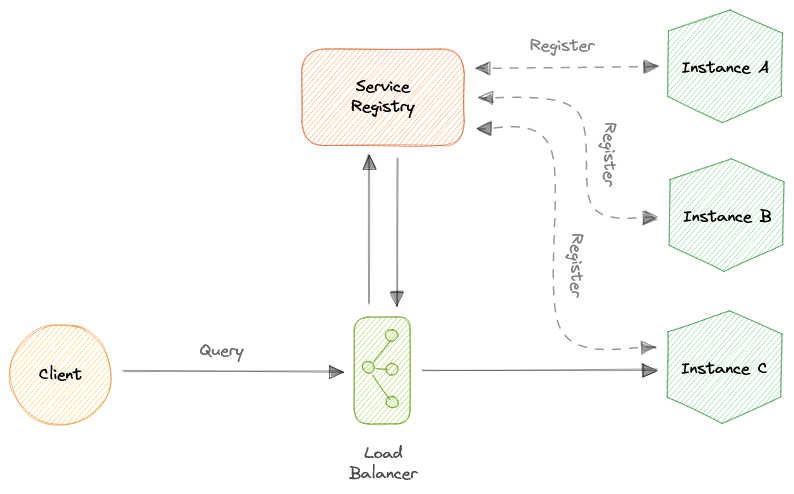
В этом подходе мы используем промежуточный компонент, такой как балансировщик нагрузки. Клиент отправляет запрос на сервис через балансировщик нагрузки, который затем перенаправляет запрос доступному экземпляру сервиса.
Реестр сервисов
Реестр сервисов представляет собой базу данных, содержащую сетевые местоположения экземпляров сервисов, к которым могут обращаться клиенты. Реестр сервисов должен быть высокодоступным и актуальным.
Регистрация сервиса
Нам также нужен способ получения информации о сервисе, часто называемый регистрацией сервиса. Рассмотрим два возможных подхода к регистрации сервиса:
Саморегистрация
При использовании модели саморегистрации экземпляр сервиса отвечает за регистрацию и удаление своего собственного сервиса в реестре сервисов. Кроме того, если необходимо, экземпляр сервиса отправляет запросы к сердцебиению, чтобы поддерживать свою регистрацию в активном состоянии.
Регистрация через стороннего поставщика
Реестр отслеживает изменения запущенных экземпляров, опрашивая среду развертывания или подписываясь на события. Когда он обнаруживает новый доступный экземпляр сервиса, он записывает его в свою базу данных. Реестр сервисов также удаляет из регистрации завершенные экземпляры сервис
ов.
Сетка сервисов
Взаимодействие между сервисами является неотъемлемым элементом распределенного приложения, но маршрутизация этого взаимодействия как внутри, так и между кластерами приложений, становится все сложнее с увеличением числа сервисов. Сетка сервисов обеспечивает управляемое, наблюдаемое и безопасное взаимодействие между отдельными сервисами. Она работает с протоколом обнаружения сервисов. Istio и envoy - это некоторые из наиболее часто используемых технологий сетки сервисов.
Примеры
Вот несколько часто используемых инструментов инфраструктуры обнаружения сервисов:
SLA, SLO, SLI
Давайте кратко обсудим SLA, SLO и SLI. Они в основном связаны с бизнесом и надежностью работы сайта, но, тем не менее, полезно знать.
Почему они важны?
SLA, SLO и SLI позволяют компаниям определять, отслеживать и контролировать обещания, даннные в отношении сервиса его пользователям. Вместе SLA, SLO и SLI должны помогать командам создавать больше доверия пользователей к своим сервисам, с акцентом на непрерывное совершенствование процессов управления инцидентами и реагирования.
SLA
SLA, или Соглашение об Уровне Сервиса, - это соглашение между компанией и ее пользователями для определенного сервиса. SLA определяет различные обещания, которые компания делает пользователям относительно конкретных метрик, таких как доступность сервиса.
SLA часто разрабатывается бизнес- или юридической службой компании.
SLO
SLO, или Цель Уровня Сервиса, - это обещание, которое компания делает пользователям относительно конкретной метрики, такой как реакция на инциденты или время работы. SLO существует в рамках SLA как отдельные обещания, содержащиеся в полном пользовательском соглашении. SLO - это конкретная цель, которую сервис должен достичь, чтобы соответствовать SLA. SLO всегда должны быть простыми, четко определенными и легко измеряемыми, чтобы определить, достигается ли цель или нет.
SLI
SLI, или Индикатор Уровня Сервиса, - это ключевая метрика, используемая для определения того, достигается ли SLO. Это измеренное значение метрики, описанной в SLO. Для соблюдения SLA значение SLI всегда должно соответствовать или превышать значение, определенное в SLO.
Аварийное восстановление
Восстановление после катастрофы (DR) - это процесс восстановления доступа и функциональности инфраструктуры после событий, таких как природные катастрофы, кибератаки или даже бизнес-прерывания.
Восстановление после катастрофы основано на репликации данных и обработке компьютера в месте, не затронутом катастрофой. Когда серверы выходят из строя из-за катастрофы, бизнесу необходимо восстановить потерянные данные из второго места, где данные резервируются. Идеально, организация также может перенести свою обработку данных в это удаленное место, чтобы продолжить операции.
Восстановление после катастрофы часто не обсуждается активно во время интервью по проектированию системы, но важно иметь базовое понимание этой темы. Вы можете узнать больше о восстановлении после катастрофы из AWS Well-Architected Framework.
Почему важно восстановление после катастрофы?
Восстановление после катастрофы может иметь следующие преимущества:
- Минимизация прерываний и простоев
- Ограничение ущерба
- Быстрое восстановление
- Лучшее удержание клиентов
Термины
Давайте обсудим некоторые важные термины, относящиеся к восстановлению после катастрофы:

RTO
Recovery Time Objective (RTO) - это максимально приемлемая задержка между прерыванием обслуживания и его восстановлением. Это определяет, что считается приемлемым временным окном, когда обслуживание недоступно.
RPO
Recovery Point Objective (RPO) - это максимально приемлемое количество времени с момента последней точки восстановления данных. Это определяет, что считается приемлемой потерей данных между последней точкой восстановления и прерыванием обслуживания.
Стратегии
Различные стратегии восстановления после катастрофы (DR) могут быть частью плана восстановления после катастрофы.
Резервное копирование
Это самый простой тип восстановления после катастрофы и включает в себя сохранение данных на удаленном сервере или на съемном носителе.
Холодный сайт
В этом типе восстановления после катастрофы организация создает базовую инфраструктуру на втором сайте.
Горячий сайт
Горячий сайт поддерживает актуальные копии данных во все время. Горячие сайты требуют много времени для настройки и дороже, чем холодные сайты, но они значительно сокращают простои.
Виртуальные машины и Контейнеры
Прежде чем мы обсудим виртуализацию против контейнеризации, давайте узнаем, что такое виртуальные машины (ВМ) и контейнеры.
Виртуальные машины (ВМ)
Виртуальная машина (ВМ) - это виртуальная среда, которая функционирует как виртуальная компьютерная система со своим собственным процессором, памятью, сетевым интерфейсом и хранилищем, созданная на физической аппаратной системе. Программное обеспечение, называемое гипервизором, отделяет ресурсы машины от аппаратного обеспечения и назначает их соответствующим образом, чтобы они могли быть использованы ВМ.
ВМ изолированы от остальной системы, и на одном куске оборудования, таком как сервер, может существовать несколько ВМ. Их можно перемещать между серверами-хостами в зависимости от спроса или для более эффективного использования ресурсов.
Что такое гипервизор?
Гипервизор, иногда называемый монитором виртуальных машин (VMM), изолирует операционную систему и ресурсы от виртуальных машин и обеспечивает создание и управление этими ВМ. Гипервизор рассматривает ресурсы, такие как ЦП, память и хранилище, как пул ресурсов, который можно легко перераспределять между существующими гостями или новыми виртуальными машинами.
Зачем использовать виртуальную машину?
Одной из основных причин использования ВМ является консолидация серверов. Большинство операционных систем и развертываний приложений используют только небольшое количество физических ресурсов, доступных. Виртуализируя наши серверы, мы можем разместить много виртуальных серверов на каждом физическом сервере, чтобы улучшить использование аппаратного обеспечения. Это позволяет избежать необходимости приобретения дополнительных физических ресурсов.
ВМ предоставляет среду, которая изолирована от остальной системы, поэтому то, что запущено внутри ВМ, не будет мешать работе других приложений на хост-аппарате. Поскольку ВМ изолированы, они являются хорошим вариантом для тестирования новых приложений или создания производственной среды. Мы также можем запускать ВМ с единственной целью для поддержки конкретного случая использования.
Контейнеры
Контейнер - это стандартная единица программного обеспечения, которая упаковывает код и все его зависимости, такие как конкретные версии сред выполнения и библиотеки, чтобы приложение работало быстро и надежно в любой вычислительной среде. Контейнеры предлагают логический механизм упаковки, в котором приложения могут быть абстрагированы от среды, в которой они фактически выполняются. Это отделение позволяет легко и последовательно развертывать приложения на основе контейнеров, независимо от целевой среды.
Зачем нам нужны контейнеры?
Давайте обсудим некоторые преимущества использования контейнеров:
Разделение обязанностей
Контейнеризация обеспечивает четкое разделение обязанностей, поскольку разработчики сосредотачиваются на логике приложения и его зависимостях, в то время как операционные команды могут сосредотачиваться на развертывании и управлении.
Портативность рабочей нагрузки
Контейнеры могут запускаться практически везде, что значительно облегчает разработку и развертывание.
Изоляция приложений
Контейнеры виртуализируют ресурсы ЦП, памяти, хранилища и сети на уровне операционной системы, предоставляя разработчикам вид на ОС, логически изолированный от других приложений.
Гибкая разработка
Контейнеры позволяют разработчикам двигаться намного быстрее, избегая проблем с зависимостями и средами.
Эффективные операции
Контейнеры являются легковесными и позволяют использовать только необходимые вычислительные ресурсы.
Виртуализация против контейнеризации

В традиционной виртуализации гипервизор виртуализирует физическое оборудование. В результате каждая виртуальная машина содержит гостевую ОС, виртуальную копию аппаратного обеспечения, необходимого для работы ОС, а также приложение и его ассоциированные библиотеки и зависимости.
Вместо виртуализации базового оборудования контейнеры виртуализируют операционную систему, так что каждый контейнер содержит только приложение и его зависимости, что делает их намного более легкими по сравнению с ВМ. Контейнеры также используют общее ядро ОС и требуют лишь долю памяти, которую требуют ВМ.
OAuth 2.0 and OpenID Connect (OIDC)
OAuth 2.0
OAuth 2.0, что означает Open Authorization, - это стандарт, предназначенный для предоставления согласованного доступа к ресурсам от имени пользователя, без передачи учетных данных пользователя. OAuth 2.0 является протоколом авторизации, а не аутентификации, он прежде всего разработан как средство предоставления доступа к набору ресурсов, например, удаленным API или данным пользователя.
Концепции
Протокол OAuth 2.0 определяет следующие сущности:
- Владелец ресурсов: Пользователь или система, владеющая защищенными ресурсами и может предоставить к ним доступ.
- Клиент: Клиент - это система, которой требуется доступ к защищенным ресурсам.
- Сервер авторизации: Этот сервер получает запросы от Клиента на получение токенов доступа и выдает их при успешной аутентификации и согласии Владельца ресурсов.
- Сервер ресурсов: Сервер, который защищает ресурсы пользователя и получает запросы на доступ от Клиента. Он принимает и проверяет токен доступа от Клиента и возвращает соответствующие ресурсы.
- Области видимости: Они используются для указания точной причины, по которой может быть предоставлен доступ к ресурсам. Допустимые значения областей видимости и их связанные ресурсы зависят от Сервера ресурсов.
- Токен доступа: Это кусочек данных, представляющий авторизацию на доступ к ресурсам от имени конечного пользователя.
Как работает OAuth 2.0?
Давайте узнаем, как работает OAuth 2.0:
- Клиент запрашивает авторизацию у Сервера авторизации, предоставляя идентификационные данные клиента и секрет. Он также указывает области видимости и URI конечной точки для отправки токена доступа или кода авторизации.
- Сервер авторизации аутентифицирует клиента и проверяет, разрешены ли запрошенные области видимости.
- Владелец ресурсов взаимодействует с сервером авторизации для предоставления доступа.
- Сервер авторизации перенаправляет клиента обратно с либо кодом авторизации, либо токеном доступа, в зависимости от типа предоставления. Может также быть возвращен Токен обновления.
- С помощью Токена доступа клиент может запросить доступ к ресурсу у Сервера ресурсов.
Недостатки
Вот наиболее распространенные недостатки OAuth 2.0:
- Отсутствие встроенных функций безопасности.
- Отсутствие стандартной реализации.
- Отсутствие общего набора областей видимости.
OpenID Connect
OAuth 2.0 разработан только для авторизации, для предоставления доступа к данным и функциям из одного приложения в другое. OpenID Connect (OIDC) - это тонкий слой, расположенный поверх OAuth 2.0, который добавляет информацию о входе и профиле пользователя, который вошел в систему.
Когда Сервер Авторизации поддерживает OIDC, его иногда называют Провайдером Идентичности (IdP), поскольку он предоставляет информацию о Владельце ресурсов обратно Клиенту. OpenID Connect относительно нов, что приводит к более низкой адоптации и реализации лучших практик в индустрии по сравнению с OAuth.
Концепции
Протокол OpenID Connect (OIDC) определяет следующие сущности:
- Доверяющая сторона (Relying Party): Текущее приложение.
- Провайдер OpenID: Это, по сути, промежуточный сервис, который предоставляет одноразовый код Доверяющей стороне.
- Токеновая конечная точка (Token Endpoint): Веб-сервер, который принимает одноразовый код (OTC) и предоставляет доступный в течение часа код доступа. Основное отличие между OIDC и OAuth 2.0 заключается в том, что токен предоставляется с использованием JSON Web Token (JWT).
- Конечная точка информации о пользователе (UserInfo Endpoint): Доверяющая сторона общается с этой конечной точкой, предоставляя защищенный токен и получая информацию о конечном пользователе.
И OAuth 2.0, и OIDC легко реализуются и основаны на JSON, что поддерживается большинством веб- и мобильных приложений. Однако спецификация OpenID Connect (OIDC) более строгая, чем базовый OAuth.
Технология единого входа
Единый Вход (SSO) - это процесс аутентификации, при котором пользователю предоставляется доступ к нескольким приложениям или веб-сайтам, используя только один набор учетных данных для входа. Это позволяет избежать необходимости входа пользователя отдельно в различные приложения.
Учетные данные пользователя и другая идентифицирующая информация хранятся и управляются централизованной системой, называемой Провайдером Идентичности (IdP). Провайдер Идентичности - это доверенная система, предоставляющая доступ к другим веб-сайтам и приложениям.
Системы аутентификации на основе Единого Входа (SSO) часто используются в корпоративных средах, где сотрудники требуют доступа к нескольким приложениям своих организаций.
Компоненты
Давайте обсудим некоторые ключевые компоненты Единого Входа (SSO).
Провайдер Идентичности (IdP)
Информация об идентичности пользователя хранится и управляется централизованной системой, называемой Провайдером Идентичности (IdP). Провайдер Идентичности аутентифицирует пользователя и предоставляет доступ к Провайдеру Услуг.
Провайдер идентичности может прямо аутентифицировать пользователя, проверяя имя пользователя и пароль, или путем проверки утверждения об идентичности пользователя, представленного отдельным провайдером идентичности. Провайдер идентичности занимается управлением пользовательских идентификаторов, чтобы освободить провайдера услуг от этой ответственности.
Провайдер Услуг
Провайдер услуг предоставляет услуги конечному пользователю. Они полагаются на провайдеров идентичности для утверждения идентичности пользователя, и обычно определенные атрибуты о пользователе управляются провайдером идентичности. Провайдеры услуг также могут поддерживать локальную учетную запись для пользователя вместе с атрибутами, уникальными для их сервиса.
Посредник Идентичности (Identity Broker)
Посредник Идентичности действует как посредник, который соединяет несколько провайдеров услуг с различными провайдерами идентичности. Используя Посредника Идентичности, мы можем выполнять единый вход в любое приложение без хлопот протокола, который он следует.
SAML
Security Assertion Markup Language - это открытый стандарт, который позволяет клиентам обмениваться информацией о безопасности в области идентификации, аутентификации и разрешений между различными системами. SAML реализуется с использованием стандарта Extensible Markup Language (XML) для обмена данными.
SAML специально обеспечивает федерацию идентичности, что позволяет поставщикам идентичности (IdP) без проблем и безопасно передавать аутентифицированные идентичности и их атрибуты поставщикам услуг.
Как работает Единый Вход (SSO)?
Теперь давайте обсудим, как работает Единый Вход:
- Пользователь запрашивает ресурс из своего желаемого приложения.
- Приложение перенаправляет пользователя на Провайдера Идентичности (IdP) для аутентификации.
- Пользователь входит под своими учетными данными (обычно, именем пользователя и паролем).
- Провайдер Идентичности (IdP) отправляет ответ Единого Входа обратно в клиентское приложение.
- Приложение предоставляет доступ пользователю.
SAML против OAuth 2.0 и OpenID Connect (OIDC)
Существует много различий между SAML, OAuth и OIDC. SAML использует XML для передачи сообщений, в то время как OAuth и OIDC используют JSON. OAuth предоставляет более простой опыт использования, в то время как SAML ориентирован на корпоративную безопасность.
OAuth и OIDC широко используют RESTful-коммуникацию, поэтому мобильные и современные веб-приложения находят опыт использования OAuth и OIDC лучше для пользователя. SAML, с другой стороны, устанавливает файл cookie сессии в браузере, который позволяет пользователю получить доступ к определенным веб-страницам. Это отлично подходит для краткосрочных рабочих нагрузок.
OpenID Connect дружелюбен для разработчиков и проще в реализации, что расширяет область применения, для которой его можно реализовать. Он может быть реализован с нуля довольно быстро с помощью свободно доступных библиотек на всех основных языках программирования. SAML может быть сложен в установке и обслуживании, справляться с этим могут только компании крупного размера.
OpenID Connect по сути является слоем поверх основы OAuth. Поэтому он может предложить встроенный уровень разрешения, который запрашивает у пользователя согласие на то, что провайдер услуг может получить доступ. Хотя SAML также способен обеспечить поток согласия, он достигает этого путем жесткого кодирования, выполняемого разработчиком, а не как часть своего протокола.
Оба этих протокола аутентификации хорошо справляются со своими задачами. Как всегда, многое зависит от наших конкретных случаев использования и целевой аудитории.
Преимущества
Вот некоторые преимущества использования Единого Входа:
- Простота использования, поскольку пользователям нужно запомнить только один н
абор учетных данных.
- Легкость доступа без необходимости прохождения длительного процесса авторизации.
- Обеспечение безопасности и соответствия для защиты чувствительных данных.
- Упрощение управления с сокращением затрат на поддержку ИТ и время администратора.
Недостатки
Вот некоторые недостатки Единого Входа:
- Уязвимость единого пароля: если основной пароль Единого Входа будет скомпрометирован, все поддерживаемые приложения также будут скомпрометированы.
- Процесс аутентификации с использованием Единого Входа медленнее, чем традиционная аутентификация, поскольку каждому приложению приходится запрашивать у поставщика Единого Входа подтверждение.
Examples
These are some commonly used Identity Providers (IdP):
SSL, TLS, mTLS
Давайте кратко обсудим некоторые важные протоколы безопасности коммуникации, такие как SSL, TLS и mTLS. Я бы сказал, что с точки зрения общей архитектуры системы эта тема не очень важна, но все равно полезно знать о ней.
SSL
SSL расшифровывается как Secure Sockets Layer, и это протокол для шифрования и обеспечения безопасности коммуникаций, которые происходят в интернете. Он был разработан в 1995 году, но с тех пор был устаревшим в пользу TLS (Transport Layer Security).
Почему он называется сертификатом SSL, если он устарел?
Большинство крупных поставщиков сертификатов по-прежнему называют их сертификатами SSL, поэтому сохраняется данное соглашение об именовании.
Почему SSL был так важен?
Изначально данные в сети передавались в открытом виде, который мог прочитать кто угодно, перехватив сообщение. SSL был создан для исправления этой проблемы и защиты конфиденциальности пользователей. Путем шифрования любых данных, которые передаются между пользователем и веб-сервером, SSL также предотвращает определенные виды кибератак, не позволяя злоумышленникам вмешиваться в передачу данных.
TLS
Transport Layer Security, или TLS, - это широко принятый протокол безопасности, разработанный для обеспечения конфиденциальности и защиты данных в сети Интернет. TLS возник из предыдущего протокола шифрования под названием Secure Sockets Layer (SSL). Основное применение TLS - шифрование связи между веб-приложениями и серверами.
Основные компоненты протокола TLS:
- Шифрование: скрывает передаваемые данные от третьих лиц.
- Аутентификация: гарантирует, что стороны, обменивающиеся информацией, действительно те, за кого они себя выдают.
- Целостность: проверяет, что данные не были подделаны или изменены.
mTLS
Взаимная аутентификация TLS, или mTLS, - это метод взаимной аутентификации. mTLS обеспечивает уверенность в том, что стороны на каждом конце сетевого соединения действительно те, за кого они себя выдают, проверяя, что у них есть правильный закрытый ключ. Информация в их соответствующих сертификатах TLS предоставляет дополнительную проверку.
Зачем использовать mTLS?
mTLS помогает обеспечить безопасность и доверие в обе стороны между клиентом и сервером. Это обеспечивает дополнительный уровень безопасности для пользователей, которые входят в сеть организации или используют приложения. Также он проверяет соединения с клиентскими устройствами, которые не проходят процесс входа в систему, например, устройства Интернета вещей (IoT).
В настоящее время mTLS широко используется микросервисами или распределенными системами в модели безопасности "нулевого доверия", чтобы проверять друг друга.
Собеседования по проектированию
Системное проектирование - очень обширная тема, и системные собеседования разработаны для оценки вашей способности разрабатывать технические решения для абстрактных проблем, поэтому они не предназначены для получения конкретного ответа. Уникальной чертой системных собеседований является двусторонняя связь между кандидатом и интервьюером.
Ожидания также сильно различаются на разных уровнях инженерных навыков. Это потому, что человек с большим практическим опытом подходит к этому вопросу совершенно иначе, чем новичок в отрасли. В результате сложно выработать единую стратегию, которая поможет нам оставаться организованными во время собеседования.
Давайте рассмотрим некоторые общие стратегии для собеседований по системному проектированию:
Уточнение требований
Вопросы на собеседовании по системному проектированию, по своей природе, могут быть неопределенными или абстрактными. Задавать вопросы о точной постановке проблемы и уточнение функциональных требований на ранних этапах собеседования очень важно. Обычно требования делятся на три части:
Функциональные требования
Это требования, которые конечный пользователь явно требует в качестве основных функций, которые должна предложить система. Все эти функциональности необходимо обязательно внедрить в систему как часть контракта.
Например:
- "Какие функции мы должны разработать для этой системы?"
- "Какие крайние случаи мы должны учесть в нашем дизайне?"
Нефункциональные требования
Это ограничения качества, которые система должна удовлетворять в соответствии с контрактом проекта. Приоритет или степень реализации этих факторов варьируется от одного проекта к другому. Они также называются нефункциональными требованиями. Например, переносимость, поддерживаемость, надежность, масштабируемость, безопасность и т. д.
Например:
- "Каждый запрос должен обрабатываться с минимальной задержкой"
- "Система должна быть высокодоступной"
Расширенные требования
Это в основном "хорошо бы иметь" требования, которые могут выходить за рамки системы.
Например:
- "Наша система должна записывать метрики и аналитику"
- "Мониторинг состояния и производительности сервиса?"
Оценка и ограничения
Оцените масштаб системы, которую мы собираемся разработать. Важно задать вопросы, такие как:
- "Какой желаемый масштаб должна обрабатывать эта система?"
- "Какое соотношение чтения/записи у нашей системы?"
- "Сколько запросов в секунду?"
- "Сколько хранилища будет нужно?"
Эти вопросы помогут нам масштабировать наш дизайн позже.
Проектирование модели данных
Как только мы установили оценки, мы можем начать с определения схемы базы данных. Это поможет нам понять поток данных, который является основой каждой системы. На этом этапе мы в основном определяем все сущности и отношения между ними.
- "Какие различные сущности есть в системе?"
- "Какие отношения между этими сущностями?"
- "Сколько таблиц нам понадобится?"
- "Не является ли NoSQL лучшим выбором здесь?"
Проектирование API
Затем мы можем начать проектирование API для системы. Эти API помогут нам явно определить ожидания от системы. Нам не нужно писать код, просто простой интерфейс, определяющий требования API, такие как параметры, функции, классы, типы, сущности и т. д.
Например:
createUser(name: string, email: string): User
Советуется держать интерфейс как можно проще и вернуться к нему позже при рассмотрении расширенных требований.
Проектирование компонентов высокого уровня
Теперь, когда мы установили нашу модель данных и проектирование API, пришло время определить компоненты системы (такие как балансировщики нагрузки, шлюз API и т. д.), необходимые для решения нашей проблемы, и составить первый дизайн нашей системы.
- "Строить монолит или микросервисную архитектуру?"
- "Какой тип базы данных следует использовать?"
Как только у нас будет базовая схема, мы можем начать обсуждение с интервьюером о том, как система будет работать с точки зрения клиента.
Подробное проектирование
Теперь пришло время подробно обсудить основные компоненты системы, которую мы разработали. Всегда обсуждайте с интервьюером, какой компонент может потребовать дальнейших улучшений.
Это хорошая возможность продемонстрировать ваш опыт в областях вашей экспертизы. Представьте разные подходы, их преимущества и недостатки. Объясните свои дизайнерские решения и подкрепите их примерами. Это также хорошее время для обсуждения любых дополнительных функций, которые система может поддерживать, хотя это необязательно.
- "Как нам следует разделить наши данные?"
- "Как насчет распределения нагрузки?"
- "Следует ли нам использовать кэш?"
- "Как мы справимся с внезапным всплеском трафика?"
Также старайтесь не быть слишком категоричными относительно определенных технологий, заявления типа "Я считаю, что NoSQL-базы данных просто лучше, SQL-базы данных не масштабируются" выглядят не очень хорошо. Как кто-то, кто много лет проводил интервьюирование, могу сказать, что лучше проявлять скромность в том, что вы знаете и что не знаете. Используйте свои существующие знания с примерами, чтобы успешно пройти эту часть собеседования.
Идентификация и устранение узких мест
Наконец, пришло время обсудить узкие места и подходы к их устранению. Вот несколько важных вопросов, которые следует задать:
- "У нас достаточно реплик базы данных?"
- "Есть ли какие-либо единичные точки отказа?"
- "Нужно ли расщепление базы данных?"
- "Как сделать нашу систему более надежной?"
- "Как улучшить доступность нашего кэша?"
Обязательно прочитайте инженерный блог компании, с которой вы проходите собеседование. Это поможет вам понять, какой технологический стек они используют и какие проблемы для них важны.
URL Shortener
Давайте разработаем укорачиватель URL-адресов, аналогичный сервисам Bitly, TinyURL.
Что такое укорачиватель URL-адресов?
Сервис укорачивания URL-адресов создает псевдоним или короткий URL-адрес для длинного URL-адреса. Пользователи перенаправляются на исходный URL-адрес, когда они посещают эти короткие ссылки.
Например, следующий длинный URL-адрес может быть изменен на более короткий URL-адрес.
Длинный URL-адрес: https://karanpratapsingh.com/courses/system-design/url-shortener
Короткий URL-адрес: https://bit.ly/3I71d3o
Зачем нам нужен укорачиватель URL-адресов?
Укорачиватель URL-адресов экономит пространство в общем случае при обмене URL-адресами. Пользователи также менее вероятно наберут неправильно короткие URL-адреса. Кроме того, мы также можем оптимизировать ссылки для различных устройств, что позволяет отслеживать отдельные ссылки.
Требования
Наша система укорачивания URL-адресов должна соответствовать следующим требованиям:
Функциональные требования
- По заданному URL-адресу наш сервис должен генерировать более короткий и уникальный псевдоним для него.
- Пользователи должны быть перенаправлены на исходный URL-адрес при посещении короткой ссылки.
- Ссылки должны истекать после определенного времени по умолчанию.
Нефункциональные требования
- Высокая доступность с минимальной задержкой.
- Система должна быть масштабируемой и эффективной.
Расширенные требования
- Предотвращение злоупотребления услугами.
- Запись аналитики и метрик для перенаправлений.
Оценка и ограничения
Давайте начнем с оценки и ограничений.
Примечание: Обязательно уточните все предположения о масштабе или трафике у вашего интервьюера.
Трафик
Это будет система с высокой нагрузкой на чтение, поэтому давайте предположим соотношение чтения/записи 100:1 с генерацией 100 миллионов ссылок в месяц.
Чтения/Записи в месяц
Для чтений в месяц:
$$ 100 \times 100 \space миллионов = 10 \space миллиардов/месяц $$
Аналогично для записей:
$$ 1 \times 100 \space миллионов = 100 \space миллионов/месяц $$
Каково количество запросов в секунду (RPS) для нашей системы?
100 миллионов запросов в месяц превращаются в 40 запросов в секунду.
$$ \frac{100 \space миллионов}{(30 \space дней \times 24 \space часа \times 3600 \space секунд)} = \sim 40 \space URL/в секунду $$
И с соотношением чтения/записи 100:1, количество перенаправлений будет:
$$ 100 \times 40 \space URL/в секунду = 4000 \space запросов/в секунду $$
Пропускная способность
Поскольку мы ожидаем примерно 40 URL каждую секунду, и если мы предположим, что каждый запрос имеет размер 500 байт, то общий объем входных данных для запросов на запись составит:
$$ 40 \times 500 \space байт = 20 \space КБ/в секунду $$
Аналогично для запросов на чтение, поскольку мы ожидаем около 4 тысяч перенаправлений, общий объем исходящих данных будет:
$$ 4000 \space URL/в секунду \times 500 \space байт = \sim 2 \space МБ/в секунду $$
Хранилище
Для хранения мы предположим, что каждую запись или URL-адрес мы будем хранить в нашей базе данных на протяжении 10 лет. Поскольку мы ожидаем около 100 миллионов новых запросов каждый месяц, общее количество записей, которые нам нужно будет хранить, составит:
$$ 100 \space миллионов \times 10\space лет \times 12 \space месяцев = 12 \space миллиардов $$
Как и ранее, если мы предположим, что каждая хранимая запись будет примерно 500 байт, нам понадобится около 6 ТБ хранилища:
$$ 12 \space миллиардов \times 500 \space байт = 6 \space ТБ $$
Кэш
Для кэширования мы будем следовать классическому принципу Парето, также известному как правило 80/20. Это означает, что 80% запросов приходится на 20% данных, поэтому мы можем кэшировать около 20% наших запросов.
Поскольку мы получаем около 4 тысяч чтений или перенаправлений каждую секунду, это переводится в 350 миллионов запросов в день.
$$ 4000 \space URL/в секунду \times 24 \space часа \times 3600 \space секунд = \sim 350 \space миллионов \space запросов/в день $$
Следовательно, нам понадобится около 35 ГБ памяти в день.
$$ 20 \space процентов \times 350 \space миллионов \times 500 \space байт = 35 \space ГБ/в день $$
Высокоуровневая оценка
Вот наша высокоуровневая оценка:
| Тип | Оценка |
|---|---|
| Записи (Новые URL) | 40/с |
| Чтения (Перенаправление) | 4K/с |
| Пропускная способность (Входящая) | 20 КБ/с |
| Пропускная способность (Исходящая) | 2 МБ/с |
| Хранилище (10 лет) | 6 ТБ |
| Память (Кэширование) |
Проектирование модели данных
Далее мы сосредоточимся на проектировании модели данных. Вот наша схема базы данных:
Изначально мы можем начать с двух таблиц:
users
Хранит данные пользователей, такие как name, email, createdAt и т. д.
urls
Содержит свойства новых коротких URL, такие как expiration, hash, originalURL и userID пользователя, который создал короткий URL. Мы также можем использовать столбец hash в качестве индекса, чтобы улучшить производительность запросов.
Какой вид базы данных следует использовать?
Поскольку данные не являются сильно связанными, базы данных NoSQL, такие как Amazon DynamoDB, Apache Cassandra или MongoDB, будут лучшим выбором здесь. Если мы всё же решим использовать SQL-базу данных, то мы можем воспользоваться такими сервисами, как Azure SQL Database или Amazon RDS.
Для получения дополнительной информации обратитесь к разделу SQL vs NoSQL.
Проектирование API
Давайте создадим базовый дизайн API для наших сервисов:
Создать URL
Это API должно создавать новый короткий URL в нашей системе для указанного исходного URL.
createURL(apiKey: string, originalURL: string, expiration?: Date): string
Параметры
API Key (string): Ключ API, предоставленный пользователем.
Original URL (string): Исходный URL, который требуется сократить.
Expiration (Date): Дата истечения срока действия нового URL (необязательно).
Возвращает
Короткий URL (string): Новый короткий URL.
Получить URL
Это API должно извлекать исходный URL по заданному короткому URL.
getURL(apiKey: string, shortURL: string): string
Параметры
API Key (string): Ключ API, предоставленный пользователем.
Short URL (string): Короткий URL, сопоставленный с исходным URL.
Возвращает
Исходный URL (string): Исходный URL, который требуется получить.
Удалить URL
Это API должно удалять указанный короткий URL из нашей системы.
deleteURL(apiKey: string, shortURL: string): boolean
Параметры
API Key (string): Ключ API, предоставленный пользователем.
Short URL (string): Короткий URL, который требуется удалить.
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Зачем нам нужен ключ API?
Как вы могли заметить, мы используем ключ API для предотвращения злоупотребления нашими сервисами. Используя этот ключ API, мы можем ограничить пользователей по числу запросов в секунду или минуту. Это довольно стандартная практика для API разработчиков и должно удовлетворить наши расширенные требования.
Высокоуровневый дизайн
Теперь давайте проведем высокоуровневый дизайн нашей системы.
Кодирование URL
Основная цель нашей системы - сокращение заданного URL, давайте рассмотрим различные подходы:
Подход Base62
В этом подходе мы можем закодировать исходный URL с использованием Base62, который состоит из заглавных букв A-Z, строчных букв a-z и цифр 0-9.
$$ Количество \space URL = 62^N $$
Где,
N: Количество символов в сгенерированном URL.
Таким образом, если мы хотим создать URL, который состоит из 7 символов, мы получим около 3,5 трлн различных URL.
$$ \begin{gather*} 62^5 = \sim 916 \space млн \space URL \ 62^6 = \sim 56,8 \space млрд \space URL \ 62^7 = \sim 3,5 \space трлн \space URL \end{gather*} $$
Это самое простое решение, но оно не гарантирует уникальные или устойчивые к коллизиям ключи.
Подход MD5
Алгоритм хэширования MD5 - это широко используемая хэш-функция, производящая 128-битное значение хэша (или 32 шестнадцатеричных цифры). Мы можем использовать эти 32 шестнадцатеричных цифры для генерации URL длиной в 7 символов.
$$ MD5(original_url) \rightarrow base62encode \rightarrow hash $$
Однако это создает новую проблему для нас, а именно дублирование и коллизии. Мы можем попробовать повторно вычислить хэш, пока мы не найдем уникальный, но это увеличит нагрузку на наши системы. Более лучшим решением будет поиск более масштабируемых подходов.
Подход счетчика
В этом подходе мы начнем с одного сервера, который будет поддерживать счетчик сгенерированных ключей. Когда наш сервис получает запрос, он может обратиться к счетчику, который возвращает уникальный номер и инкрементирует счетчик. Когда приходит следующий запрос, счетчик снова возвращает уникальный номер, и так далее.
$$ Counter(0-3.5 \space trillion) \rightarrow base62encode \rightarrow hash $$
Проблема этого подхода заключается в том, что он быстро может стать единственной точкой отказа. И если мы запустим несколько экземпляров счетчика, у нас может произойти коллизия, поскольку это, по сути, распределенная система.
Чтобы решить эту проблему, мы можем использовать менеджер распределенной системы, такой как Zookeeper, который может обеспечить распределенную синхронизацию. Zookeeper может поддерживать несколько диапазонов для наших серверов.
$$ \begin{align*} & Range \space 1: \space 1 \rightarrow 1,000,000 \ & Range \space 2: \space 1,000,001 \rightarrow 2,000,000 \ & Range \space 3: \space 2,000,001 \rightarrow 3,000,000 \ & ... \end{align*} $$
Как только сервер достигает своего максимального диапазона, Zookeeper назначает новому серверу неиспользуемый диапазон счетчика. Этот подход может гарантировать уникальные и уст
ойчивые к коллизиям URL. Кроме того, мы можем запускать несколько экземпляров Zookeeper, чтобы избежать единой точки отказа.
Сервис генерации ключей (KGS)
Как мы обсуждали, генерация уникального ключа на масштабе без дублирования и коллизий может быть немного сложной задачей. Чтобы решить эту проблему, мы можем создать отдельный Сервис генерации ключей (KGS), который заранее генерирует уникальный ключ и сохраняет его в отдельной базе данных для последующего использования. Этот подход может упростить нам задачу.
Как обрабатывать параллельный доступ?
Как только ключ используется, мы помечаем его в базе данных, чтобы убедиться, что не используем его снова, однако, если несколько экземпляров серверов одновременно считывают данные, два или более серверов могут попытаться использовать один и тот же ключ.
Самый простой способ решить эту проблему - хранить ключи в двух таблицах. Как только ключ используется, мы перемещаем его в отдельную таблицу с соответствующей блокировкой. Кроме того, чтобы улучшить считывание, мы можем хранить некоторые ключи в памяти.
Оценки базы данных KGS
Как мы обсуждали, мы можем сгенерировать до ~56,8 млрд уникальных ключей длиной в 6 символов, что приведет к необходимости хранения 300 ГБ ключей.
$$ 6 \space символов \times 56,8 \space млрд = \sim 390 \space ГБ $$
Хотя 390 ГБ кажется много для этого простого случая использования, важно помнить, что это для всего срока службы нашего сервиса, и размер базы данных ключей не будет увеличиваться, как наша основная база данных.
Кэширование
Теперь давайте поговорим о кэшировании. Как по нашим оценкам, нам потребуется около ~35 ГБ памяти в день, чтобы кэшировать 20% входящих запросов в наши сервисы. Для этого случая использования мы можем использовать серверы Redis или Memcached вместе с нашими серверами API.
Для получения дополнительной информации обратитесь к кэшированию.
Дизайн
Теперь, когда мы определили некоторые основные компоненты, давайте сделаем первый черновой вариант дизайна нашей системы.
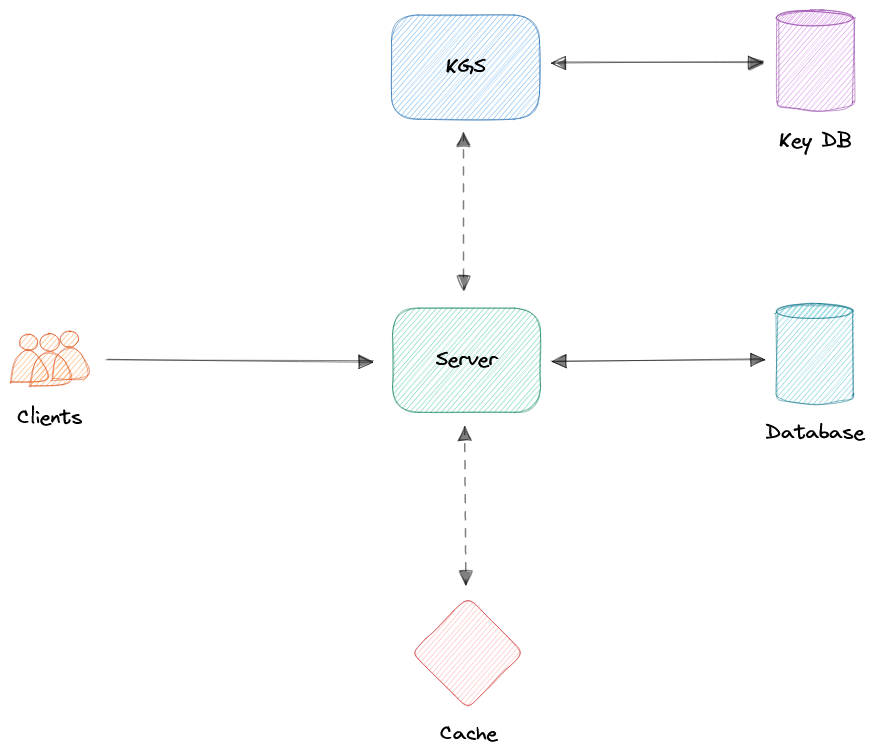
Вот как это работает:
Создание нового URL
- Когда пользователь создает новый URL, наш сервер API запрашивает новый уникальный ключ у Сервиса генерации ключей (KGS).
- Сервис генерации ключей предоставляет уникальный ключ серверу API и помечает ключ как использованный.
- Сервер API записывает новую запись URL в базу данных и кэш.
- Наш сервис возвращает пользователю ответ HTTP 201 (Создан).
Доступ к URL
- Когда клиент переходит по определенному короткому URL, запрос отправляется на серверы API.
- Запрос сначала попадает в кэш, и если запись не найдена там, то она извлекается из базы данных, и отправляется HTTP 301 (Перенаправление) на исходный URL.
- Если ключ все еще не найден в базе данных, пользователю отправляется HTTP 404 (Не найдено).
Детальный дизайн
Пришло время обсудить более тонкие детали нашего дизайна.
Разделение данных
Для масштабирования наших баз данных нам потребуется разделить наши данные. Горизонтальное разделение (также известное как Sharding) может быть хорошим первым шагом. Мы можем использовать такие схемы разделения, как:
- Хешированное разделение
- Списочное разделение
- Разделение на основе диапазона
- Составное разделение
Упомянутые выше подходы все еще могут привести к неравномерному распределению данных и нагрузке. Мы можем решить эту проблему с помощью консистентного хеширования.
Для получения дополнительной информации обратитесь к Sharding и Консистентное Хеширование.
Очистка базы данных
Это скорее процесс поддержки для наших сервисов и зависит от того, храним ли мы устаревшие записи или удаляем их. Если мы решим удалять устаревшие записи, мы можем подойти к этому двумя разными способами:
Активная очистка
При активной очистке мы запустим отдельный сервис очистки, который периодически удаляет устаревшие ссылки из нашего хранилища и кэша. Это будет очень легкий сервис, похожий на cron job.
Пассивная очистка
Для пассивной очистки мы можем удалять запись, когда пользователь пытается получить доступ к устаревшей ссылке. Это позволяет лениво очищать нашу базу данных и кэш.
Кэш
Теперь давайте поговорим о кэшировании.
Какую политику вытеснения из кэша использовать?
Как мы обсуждали ранее, мы можем использовать решения вроде Redis или Memcached и кэшировать 20% ежедневного трафика, но какая политика вытеснения из кэша лучше всего подходит для наших нужд?
Наименее используемый (LRU) может быть хорошей политикой для нашей системы. В этой политике мы сначала удаляем ключ, который использовался наименее недавно.
Как обрабатывать промахи кэша?
В случае промаха кэша наши серверы могут обратиться к базе данных напрямую и обновить кэш новыми записями.
Метрики и аналитика
Запись аналитики и метрик является одним из расширенных требований. Мы можем хранить и обновлять метаданные, такие как страна посетителя, платформа и количество просмотров, вместе с записью URL в нашей базе данных.
Безопасность
Для обеспечения безопасности мы можем ввести приватные URL и авторизацию. Отдельная таблица может использоваться для хранения идентификаторов пользователей, которые имеют разрешение на доступ к определенному URL. Если у пользователя нет соответствующих разрешений, мы можем вернуть HTTP 401 (Unauthorized) ошибку.
Мы также можем использовать API Gateway, так как они могут поддерживать функции, такие как авторизация, ограничение скорости и балансировка нагрузки из коробки.
Выявление и устранение узких мест
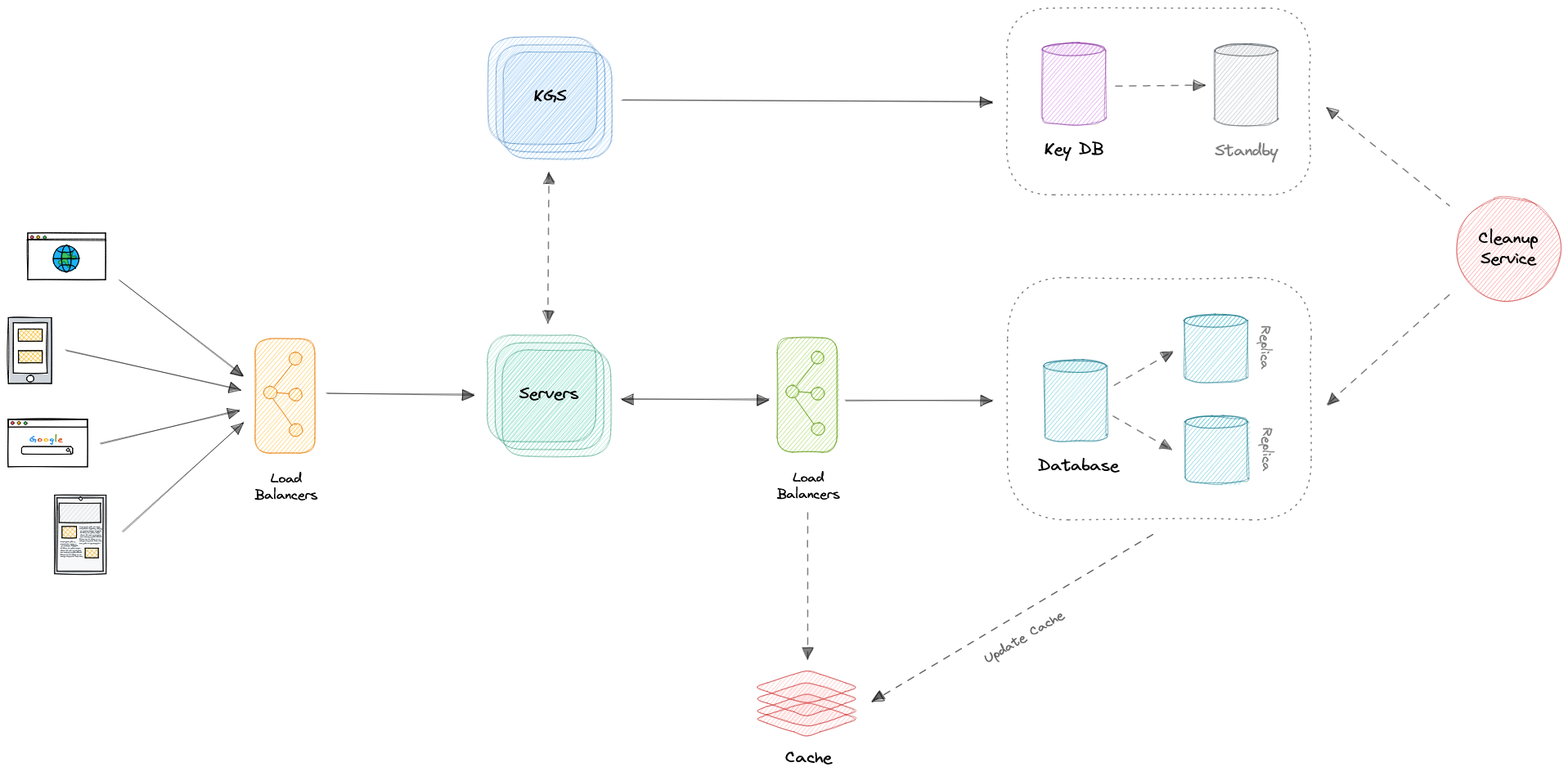
Давайте выявим и устраним узкие места, такие как единичные точки отказа в нашем дизайне:
- "Что если служба API или служба генерации ключей выйдет из строя?"
- "Как мы распределим наш трафик
между компонентами?"
- "Как мы можем снизить нагрузку на нашу базу данных?"
- "Что если база данных ключей, используемая KGS, выйдет из строя?"
- "Как улучшить доступность нашего кэша?"
Чтобы сделать нашу систему более надежной, мы можем:
- Запускать несколько экземпляров наших серверов и службы генерации ключей.
- Ввести балансировщики нагрузки между клиентами, серверами, базами данных и серверами кэша.
- Использовать несколько реплик для нашей базы данных, учитывая ее направленность на чтение.
- Иметь резервные реплики для базы данных ключей в случае сбоя.
- Поддерживать несколько экземпляров и реплик для нашего распределенного кэша.
Давайте спроектируем сервис мгновенного обмена сообщениями, подобный WhatsApp, похожий на такие сервисы, как Facebook Messenger и WeChat.
Что такое WhatsApp?
WhatsApp - это приложение для обмена сообщениями, которое предоставляет услуги мгновенного обмена сообщениями своим пользователям. Это одно из самых используемых мобильных приложений на планете, объединяющее более 2 миллиардов пользователей в 180+ странах. WhatsApp также доступен в Интернете.
Требования
Наша система должна соответствовать следующим требованиям:
Функциональные требования
- Должна поддерживать чат один на один.
- Групповые чаты (максимум 100 человек).
- Должна поддерживать обмен файлами (изображения, видео и т. д.).
Нефункциональные требования
- Высокая доступность с минимальной задержкой.
- Система должна быть масштабируемой и эффективной.
Расширенные требования
- Статусы "Отправлено", "Доставлено" и "Прочитано" сообщений.
- Показывать время последнего посещения пользователей.
- Уведомления о новых сообщениях.
Оценка и ограничения
Давайте начнем с оценки и определения ограничений.
Примечание: Обязательно проверьте все предположения о масштабе или трафике с вашим собеседником.
Трафик
Допустим, у нас есть 50 миллионов ежедневно активных пользователей (DAU), и в среднем каждый пользователь отправляет по крайней мере 10 сообщений 4 разным людям каждый день. Это дает нам 2 миллиарда сообщений в день.
$$ 50 \space миллионов \times 40 \space сообщений = 2 \space миллиарда/день $$
Сообщения также могут содержать медиафайлы, такие как изображения, видео или другие файлы. Мы можем предположить, что 5 процентов сообщений - это медиафайлы, переданные пользователями, что дает нам дополнительно 100 миллионов файлов, которые нам нужно будет хранить.
$$ 5 \space процентов \times 2 \space миллиарда = 100 \space миллионов/день $$
Какова будет загрузка запросов в секунду (RPS) для нашей системы?
2 миллиарда запросов в день превращаются в 24K запросов в секунду.
$$ \frac{2 \space миллиарда}{(24 \space часа \times 3600 \space секунд)} = \sim 24K \space запросов/секунду $$
Хранение
Если мы предположим, что каждое сообщение в среднем составляет 100 байт, нам понадобится около 200 ГБ базового хранилища данных каждый день.
$$ 2 \space миллиарда \times 100 \space байт = \sim 200 \space ГБ/день $$
Согласно нашим требованиям, мы также знаем, что примерно 5 процентов наших ежедневных сообщений (100 миллионов) - это медиафайлы. Если мы предположим, что каждый файл в среднем занимает 100 КБ, нам понадобится 10 ТБ хранилища данных каждый день.
$$ 100 \space миллионов \times 100 \space КБ = 10 \space ТБ/день $$
И на протяжении 10 лет нам потребуется около 38 ПБ хранилища.
$$ (10 \space ТБ + 0.2 \space ТБ) \times 10 \space лет \times 365 \space дней = \sim 38 \space ПБ $$
Пропускная способность
Поскольку наша система обрабатывает 10,2 ТБ входящих данных каждый день, нам пон
адобится минимальная пропускная способность около 120 МБ в секунду.
$$ \frac{10.2 \space ТБ}{(24 \space часа \times 3600 \space секунд)} = \sim 120 \space МБ/секунду $$
Предварительная оценка
Вот наша предварительная оценка:
| Тип | Оценка |
|---|---|
| Ежедневно активных пользователей (DAU) | 50 миллионов |
| Запросов в секунду (RPS) | 24K/s |
| Хранилище (в день) | ~10.2 ТБ |
| Хранилище (10 лет) | ~38 ПБ |
| Пропускная способность | ~120 МБ/с |
Дизайн модели данных
Это общая модель данных, отражающая наши требования.
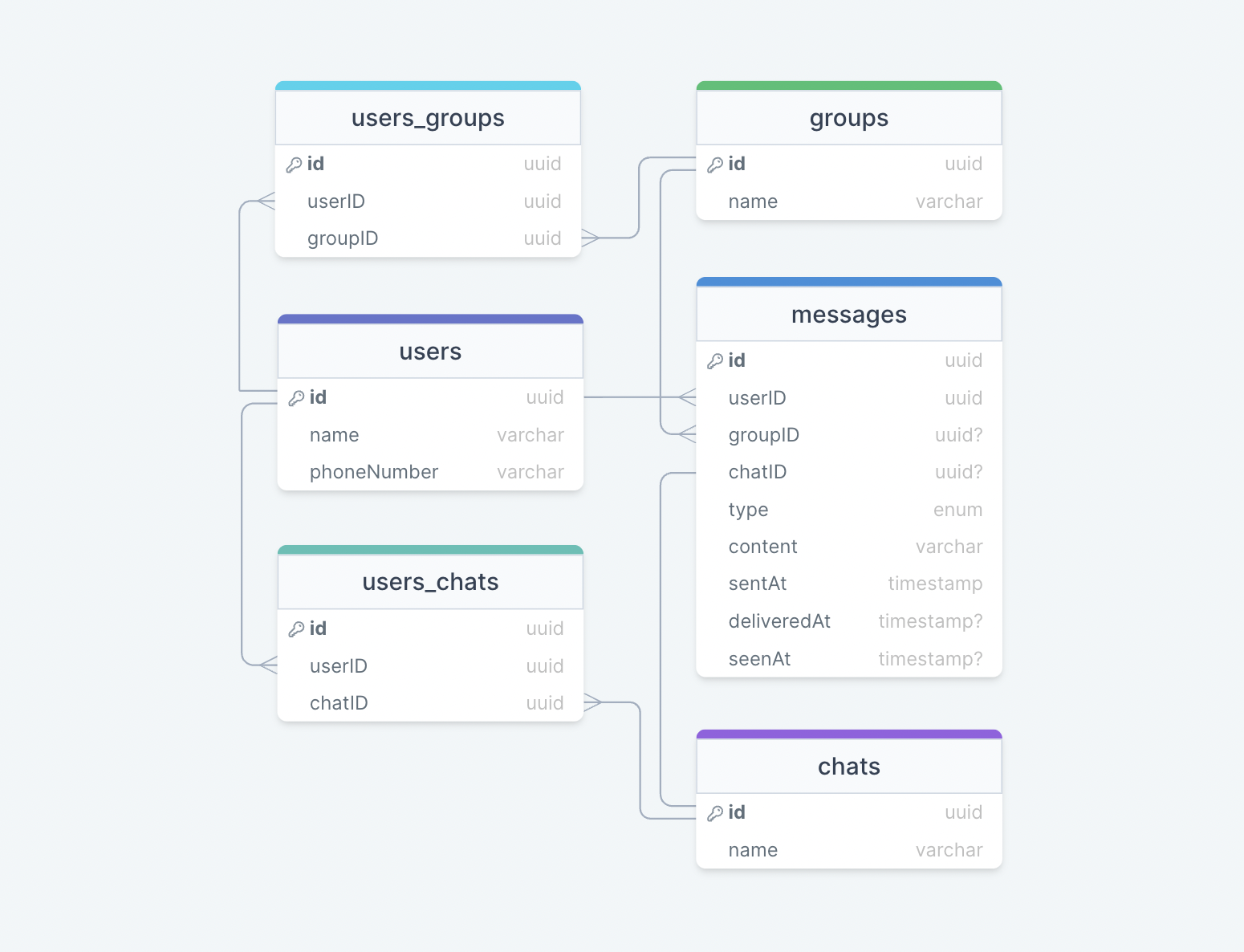
У нас есть следующие таблицы:
users
Эта таблица будет содержать информацию о пользователе, такую как name, phoneNumber и другие данные.
messages
Как следует из названия, эта таблица будет хранить сообщения с такими свойствами, как type (текст, изображение, видео и т. д.), content и метки времени доставки сообщения. Сообщение также будет иметь соответствующий chatID или groupID.
chats
Эта таблица в основном представляет собой приватный чат между двумя пользователями и может содержать несколько сообщений.
users_chats
Эта таблица отображает связь пользователей и чатов, так как у нескольких пользователей может быть несколько чатов (отношение N:M) и наоборот.
groups
Эта таблица представляет собой группу, состоящую из нескольких пользователей.
users_groups
Эта таблица отображает связь пользователей и групп, так как у нескольких пользователей может быть несколько групп (отношение N:M) и наоборот.
Какую базу данных стоит использовать?
Хотя наша модель данных выглядит достаточно реляционной, нам не обязательно нужно хранить все в одной базе данных, так как это может ограничить нашу масштабируемость и быстро стать узким местом.
Мы разделим данные между разными сервисами, каждый из которых будет владеть определенной таблицей. Затем мы можем использовать реляционную базу данных, такую как PostgreSQL или распределенную NoSQL-базу данных, такую как Apache Cassandra для нашего случая использования.
Дизайн API
Давайте сделаем базовый дизайн API для наших сервисов:
Получить все чаты или группы
Этот API получает все чаты или группы для данного userID.
getAll(userID: UUID): Chat[] | Group[]
Параметры
User ID (UUID): Идентификатор текущего пользователя.
Возвращает
Результат (Chat[] | Group[]): Все чаты и группы, в которых участвует пользователь.
Получить сообщения
Получить все сообщения для пользователя по channelID (идентификатор чата или группы).
getMessages(userID: UUID, channelID: UUID): Message[]
Параметры
User ID (UUID): Идентификатор текущего пользователя.
Channel ID (UUID): Идентификатор канала (чата или группы), из которого нужно получить сообщения.
Возвращает
Сообщения (Message[]): Все сообщения в указанном чате или группе.
Отправить сообщение
Отправить сообщение от пользователя к каналу (чату или группе).
sendMessage(userID: UUID, channelID: UUID, message: Message): boolean
Параметры
User ID (UUID): Идентификатор текущего пользователя.
Channel ID (UUID): Идентификатор канала (чата или группы), к которому пользователь хочет отправить сообщение.
Message (Message): Сообщение (текст, изображение, видео и т. д.), которое пользователь хочет отправить.
Возвращает
Результат (boolean): Показывает, успешна ли операция или нет.
Присоединиться к или покинуть канал
Позволяет пользователю присоединиться к или покинуть канал (чат или группу).
joinGroup(userID: UUID, channelID: UUID): boolean
leaveGroup(userID: UUID, channelID: UUID): boolean
Параметры
User ID (UUID): Идентификатор текущего пользователя.
Channel ID (UUID): Идентификатор канала (чата или группы), который пользователь хочет присоединиться или покинуть.
Возвращает
Результат (boolean): Показывает, успешна ли операция или нет.
High-level design
Давайте разработаем высокоуровневый дизайн нашей системы.
Архитектура
Мы будем использовать архитектуру микросервисов, так как она облегчит горизонтальное масштабирование и разделение наших сервисов. Каждый сервис будет иметь владение своей собственной моделью данных. Давайте попробуем разделить нашу систему на несколько основных сервисов.
Сервис пользователей
Это HTTP-сервис, который обрабатывает задачи, связанные с пользователями, такие как аутентификация и информация о пользователе.
Сервис чата
Сервис чата будет использовать WebSockets для установления соединений с клиентом и обработки функционала чата и групповых сообщений. Мы также можем использовать кэш для отслеживания всех активных соединений, похоже на сеансы, что поможет нам определить, находится ли пользователь в сети или нет.
Сервис уведомлений
Этот сервис просто отправляет уведомления push пользователям. О нем будет подробно рассказано отдельно.
Сервис присутствия
Сервис присутствия будет отслеживать статус последнего посещения всех пользователей. О нем будет подробно рассказано отдельно.
Сервис медиафайлов
Этот сервис будет обрабатывать загрузку медиафайлов (изображений, видео, файлов и т. д.). О нем будет подробно рассказано отдельно.
Как насчет взаимосвязи между сервисами и обнаружения сервисов?
Поскольку наша архитектура основана на микросервисах, сервисы будут взаимодействовать друг с другом. Обычно REST или HTTP работают хорошо, но мы можем дополнительно улучшить производительность, используя gRPC, который более легковесен и эффективен.
Обнаружение сервисов - это еще одна вещь, которую мы должны учитывать. Мы также можем использовать сервисную сеть, которая обеспечивает управляемое, наблюдаемое и безопасное взаимодействие между отдельными сервисами.
Примечание: Узнайте больше о REST, GraphQL, gRPC и как они сравниваются между собой.
Реальномременная передача сообщений
Как эффективно отправлять и получать сообщения? У нас есть два разных варианта:
Модель опроса
Клиент может периодически отправлять HTTP-запросы на серверы, чтобы проверить, есть ли новые сообщения. Это можно достичь, используя, например, Долгое опрос.
Модель отправки
Клиент открывает долговременное соединение с сервером, и после появления новых данных они будут отправлены клиенту. Мы можем использовать WebSockets или События, отправляемые сервером (SSE) для этого.
Модель опроса не масштабируется, так как она создает ненужную нагрузку на запросы на наши серверы, и большую часть времени ответ будет пустым, тем самым тратя наши ресурсы. Чтобы минимизировать задержку, использование модели отправки с WebSockets - более хороший выбор, потому что тогда мы можем отправлять данные клиенту, как только они станут доступны, без задержек, при условии, что соединение открыто с клиентом. Кроме того, WebSockets обеспечивают двустороннюю связь, в отличие от Событий, отправляемых сервером (SSE), которые работают только в одном направлении.
Примечание: Узнайте больше о Долгом опросе, WebSockets, Событиях, отправляемых сервером (SSE).
Последнее посещение
Чтобы реализовать функцию "последнего посещения", мы можем использовать механизм
пульсации, где клиент периодически отправляет запросы на серверы, указывая свою живучесть. Поскольку это должно быть как можно менее затратно, мы можем хранить последнее активное время в кэше следующим образом:
| Ключ | Значение |
|---|---|
| Пользователь A | 2022-07-01T14:32:50 |
| Пользователь B | 2022-07-05T05:10:35 |
| Пользователь C | 2022-07-10T04:33:25 |
Это даст нам время последнего активного пользователя. Эта функциональность будет обрабатываться службой присутствия в сочетании с Redis или Memcached как наш кэш.
Другой способ реализации - отслеживать последнее действие пользователя. Как только последняя активность пользователя превысит определенный порог, например "пользователь не выполнял никаких действий в течение последних 30 секунд", мы можем показать пользователя как оффлайн и последний раз видели с последним записанным временем. Это будет скорее ленивый подход к обновлению и может приносить пользу по сравнению с механизмом пульсации в некоторых случаях.
Уведомления
После отправки сообщения в чате или группе мы сначала проверим, активен ли получатель или нет, мы можем получить эту информацию, учитывая активное соединение пользователя и последний раз видели его.
Если получатель не активен, сервис чата добавит событие в очередь сообщений с дополнительной метаданными, такими как платформа устройства клиента, которая будет использоваться позже для маршрутизации уведомлений на правильную платформу.
Затем сервис уведомлений будет потреблять событие из очереди сообщений и пересылать запрос в Firebase Cloud Messaging (FCM) или Apple Push Notification Service (APNS) в зависимости от платформы устройства клиента (Android, iOS, веб и т. д.). Мы также можем добавить поддержку электронной почты и SMS.
Почему мы используем очередь сообщений?
Поскольку большинство очередей сообщений обеспечивают доставку сообщений в том же порядке, в котором они отправляются, и что сообщение доставляется как минимум один раз, что является важной частью функциональности нашего сервиса.
Хотя это кажется классическим случаем использования подписки-публикации, на самом деле это не так, поскольку мобильные устройства и браузеры имеют свой собственный способ обработки уведомлений push. Обычно уведомления обрабатываются внешне через Firebase Cloud Messaging (FCM) или Apple Push Notification Service (APNS), в отличие от распределенной передачи сообщений, которую мы обычно видим в бэкенд-сервисах. Мы можем использовать что-то вроде Amazon SQS или RabbitMQ для поддержки этой функциональности.
Read receipts
Обработка уведомлений о прочтении может быть сложной, для этого случая использования мы можем дождаться некоторого вида Подтверждения (ACK) от клиента, чтобы определить, было ли сообщение доставлено, и обновить соответствующее поле deliveredAt. Аналогично, мы отметим сообщение как прочитанное, как только пользователь откроет чат, и обновим соответствующее поле временной метки seenAt.
Дизайн
Теперь, когда мы определили некоторые основные компоненты, давайте сделаем первый черновик нашего дизайна системы.
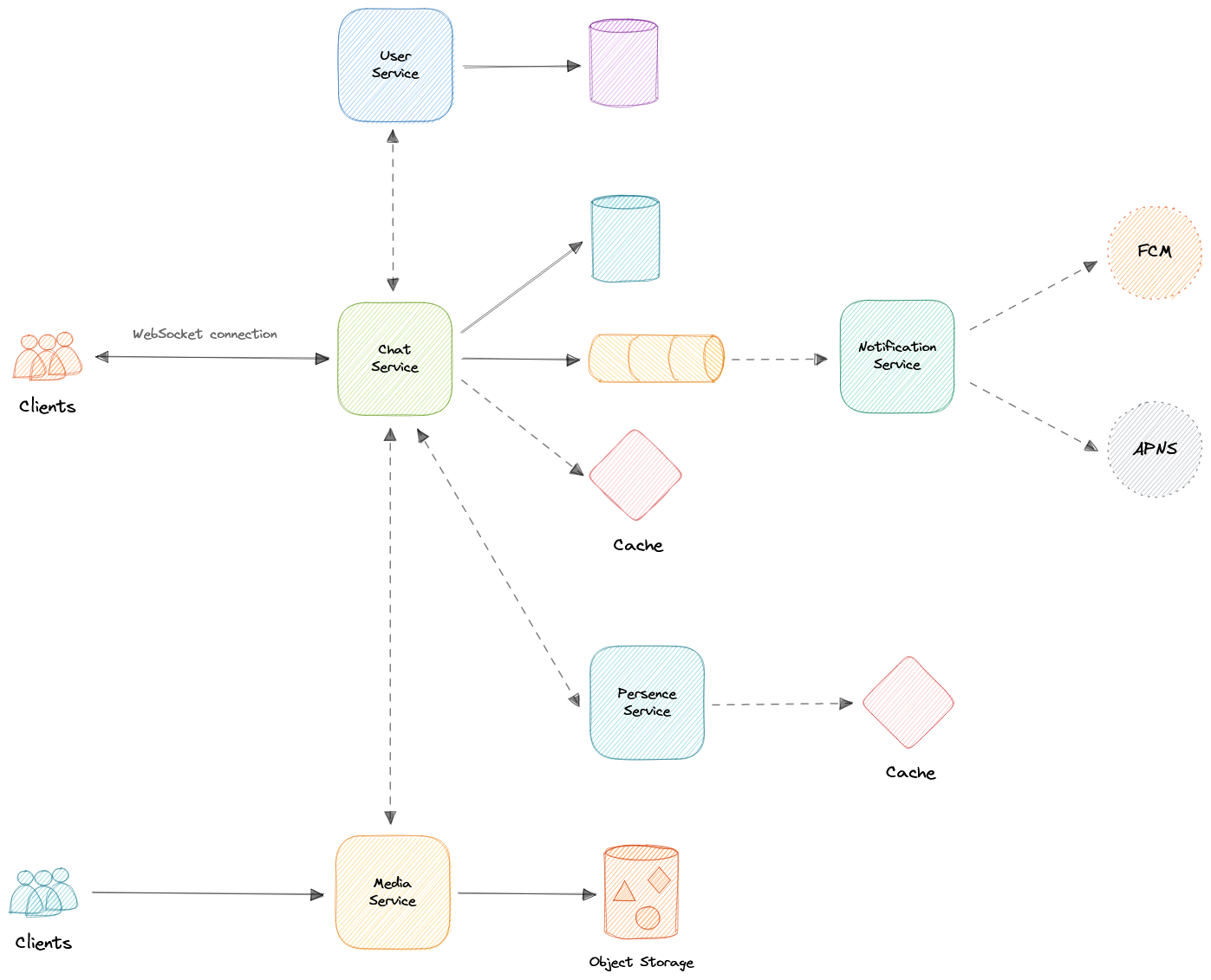
Подробный дизайн
Пришло время обсудить наши решения по дизайну подробно.
Разделение данных
Для масштабирования наших баз данных нам нужно разделить наши данные. Горизонтальное разделение (также известное как Шардинг) может быть хорошим первым шагом. Мы можем использовать схемы разделения, такие как:
- Хэш-ориентированное разделение
- Списково-ориентированное разделение
- Диапазонное разделение
- Композитное разделение
Указанные выше подходы могут все еще вызывать неравномерное распределение данных и нагрузки, и мы можем решить это, используя Консистентное хеширование.
Для получения дополнительной информации обратитесь к Шардинг и Консистентное хеширование.
Кэширование
В приложении обмена сообщениями мы должны быть осторожны при использовании кэша, поскольку наши пользователи ожидают последних данных, но многие пользователи будут запрашивать одни и те же сообщения, особенно в групповом чате. Поэтому, чтобы предотвратить скачки использования наших ресурсов, мы можем кэшировать более старые сообщения.
Некоторые групповые чаты могут содержать тысячи сообщений, и отправка их по сети будет действительно неэффективной, чтобы повысить эффективность, мы можем добавить пагинацию в наши системные API. Это решение будет полезным для пользователей с ограниченной пропускной способностью сети, так как они не будут загружать старые сообщения, если их не запросят.
Какую политику вытеснения кэша использовать?
Мы можем использовать решения, такие как Redis или Memcached и кэшировать 20% ежедневного трафика, но какую политику вытеснения кэша лучше всего использовать для наших нужд?
Наименее недавно используемое (LRU) может быть хорошей политикой для нашей системы. В этой политике мы сначала отбрасываем ключ, который использовался наименее недавно.
Как обрабатывать промахи кэша?
В случае промаха кэша наши серверы могут обратиться к базе данных напрямую и обновить кэш новыми записями.
Для получения дополнительной информации обратитесь к Кэшированию.
Доступ к медиафайлам и хранение
Как мы знаем, большая часть нашего пространства для хранения будет использоваться для хранения медиафайлов, таких как изображения, видео или другие файлы. Наш сервис медиафайлов будет обрабатывать как доступ, так и хранение медиафайлов пользователей.
Но где мы можем хранить файлы в масштабе? Что ж, объектное хранилище - это то, что нам нужно. Объектные хранилища разбивают файлы данных на куски, называемые объектами. Затем они хранят эти объекты в едином репозитории, который может быть рас
пределен по нескольким сетевым системам. Мы также можем использовать распределенное файловое хранилище, такое как HDFS или GlusterFS.
Интересный факт: WhatsApp удаляет медиафайлы с серверов после их загрузки пользователем.
Мы можем использовать объектные хранилища, такие как Amazon S3, Azure Blob Storage или Google Cloud Storage для этого использования.
Сеть доставки контента (CDN)
Сеть доставки контента (CDN) увеличивает доступность и избыточность контента, снижая при этом затраты на пропускную способность. Обычно статические файлы, такие как изображения и видео, предоставляются из CDN. Мы можем использовать службы, такие как Amazon CloudFront или Cloudflare CDN для этого использования.
Шлюз API
Поскольку мы будем использовать несколько протоколов, таких как HTTP, WebSocket, TCP/IP, развертывание нескольких балансировщиков нагрузки типа L4 (транспортного уровня) или L7 (уровня приложения) отдельно для каждого протокола будет дорогим. Вместо этого мы можем использовать API Gateway, который поддерживает несколько протоколов без проблем.
API Gateway также может предложить другие функции, такие как аутентификация, авторизация, ограничение скорости, регулирование, и версионирование API, что улучшит качество наших услуг.
Мы можем использовать службы, такие как Amazon API Gateway или Azure API Gateway для этого использования.
Выявление и устранение узких мест
Давайте выявим и устраним узкие места, такие как одиночные точки отказа, в нашем дизайне:
- "Что, если один из наших сервисов выйдет из строя?"
- "Как мы распределим наш трафик между нашими компонентами?"
- "Как мы можем снизить нагрузку на нашу базу данных?"
- "Как улучшить доступность нашего кэша?"
- "Не станет ли API Gateway одной точкой отказа?"
- "Как сделать нашу систему уведомлений более надежной?"
- "Как мы можем снизить затраты на хранение медиафайлов"?
- "Неслишком ли много ответственности у сервиса чата?"
Чтобы сделать нашу систему более устойчивой, мы можем сделать следующее:
- Запускать несколько экземпляров каждого из наших сервисов.
- Введение балансировщиков нагрузки между клиентами, серверами, базами данных и серверами кэша.
- Использование нескольких реплик для наших баз данных.
- Несколько экземпляров и реплик для нашего распределенного кэша.
- Мы можем иметь резервную реплику нашего API Gateway.
- Однократная доставка и упорядочивание сообщений представляют сложности в распределенной системе, мы можем использовать специализированный брокер сообщений такой как Apache Kafka или NATS, чтобы сделать нашу систему уведомлений более надежной.
- Мы можем добавить возможности обработки и сжатия медиафайлов в сервис медиафайлов, чтобы сжимать большие файлы, аналогично WhatsApp, что сэкономит много места для хранения и снизит затраты.
- Мы можем создать групповой сервис отдельно от сервиса чата, чтобы дополнительно разделить наши сервисы.
Давайте разработаем сервис социальных медиа, похожий на Twitter, подобный сервисам, таким как Facebook, Instagram, и т.д.
Что такое Twitter?
Twitter - это сервис социальных медиа, где пользователи могут читать или публиковать короткие сообщения (до 280 символов), называемые твитами. Он доступен в вебе и на мобильных платформах, таких как Android и iOS.
Требования
Наша система должна соответствовать следующим требованиям:
Функциональные требования
- Должна быть возможность публиковать новые твиты (могут быть текст, изображение, видео и т.д.).
- Должна быть возможность подписываться на других пользователей.
- Должна быть функция новостной ленты, состоящая из твитов от пользователей, на которых подписан пользователь.
- Должна быть возможность поиска твитов.
Нефункциональные требования
- Высокая доступность с минимальной задержкой.
- Система должна быть масштабируемой и эффективной.
Расширенные требования
- Метрики и аналитика.
- Функционал ретвитов.
- Избранные твиты.
Оценка и ограничения
Давайте начнем с оценки и ограничений.
Примечание: Убедитесь, что ваши предположения о масштабе или трафике проверены с вашим интервьюером.
Трафик
Это будет система с высоким чтением, давайте предположим, что у нас есть 1 миллиард пользователей всего, из которых 200 миллионов ежедневно активных пользователей (DAU), и в среднем каждый пользователь делает 5 твитов в день. Это дает нам 1 миллиард твитов в день.
$$ 200 \space миллионов \times 5 \space твитов = 1 \space миллиард/день $$
Твиты могут также содержать медиафайлы, такие как изображения или видео. Мы можем предположить, что 10 процентов твитов - это медиафайлы, размещенные пользователями, что дает нам дополнительные 100 миллионов файлов, которые нам нужно будет хранить.
$$ 10 \space процентов \times 1 \space миллиард = 100 \space миллионов/день $$
Какова будет частота запросов (RPS) для нашей системы?
1 миллиард запросов в день превращается в 12 тысяч запросов в секунду.
$$ \frac{1 \space миллиард}{(24 \
space часа \times 3600 \space секунд)} = \sim 12K \space запросов/секунду $$
Хранилище
Если мы предположим, что каждое сообщение в среднем составляет 100 байт, нам потребуется около 100 ГБ хранилища базы данных ежедневно.
$$ 1 \space миллиард \times 100 \space байт = \sim 100 \space ГБ/день $$
Мы также знаем, что примерно 10 процентов наших ежедневных сообщений (100 миллионов) - это медиафайлы согласно нашим требованиям. Если мы предположим, что каждый файл в среднем составляет 50 КБ, нам потребуется 5 ТБ хранилища ежедневно.
$$ 100 \space миллионов \times 50 \space КБ = 5 \space ТБ/день $$
И за 10 лет нам понадобится около 19 ПБ хранилища.
$$ (5 \space ТБ + 0.1 \space ТБ) \times 365 \space дней \times 10 \space лет = \sim 19 \space ПБ $$
Пропускная способность
Поскольку наша система обрабатывает 5.1 ТБ входящего трафика каждый день, нам потребуется минимальная пропускная способность около 60 МБ в секунду.
$$ \frac{5.1 \space ТБ}{(24 \space часа \times 3600 \space секунд)} = \sim 60 \space МБ/сек $$
Оценка на высоком уровне
Вот наша оценка на высоком уровне:
| Тип | Оценка |
|---|---|
| Ежедневно активные пользователи (DAU) | 100 миллионов |
| Запросов в секунду (RPS) | 12K/сек |
| Хранилище (ежедневно) | ~5.1 ТБ |
| Хранилище (10 лет) | ~19 ПБ |
| Пропускная способность | ~60 МБ/сек |
Дизайн модели данных
Это общая модель данных, которая отражает наши требования.
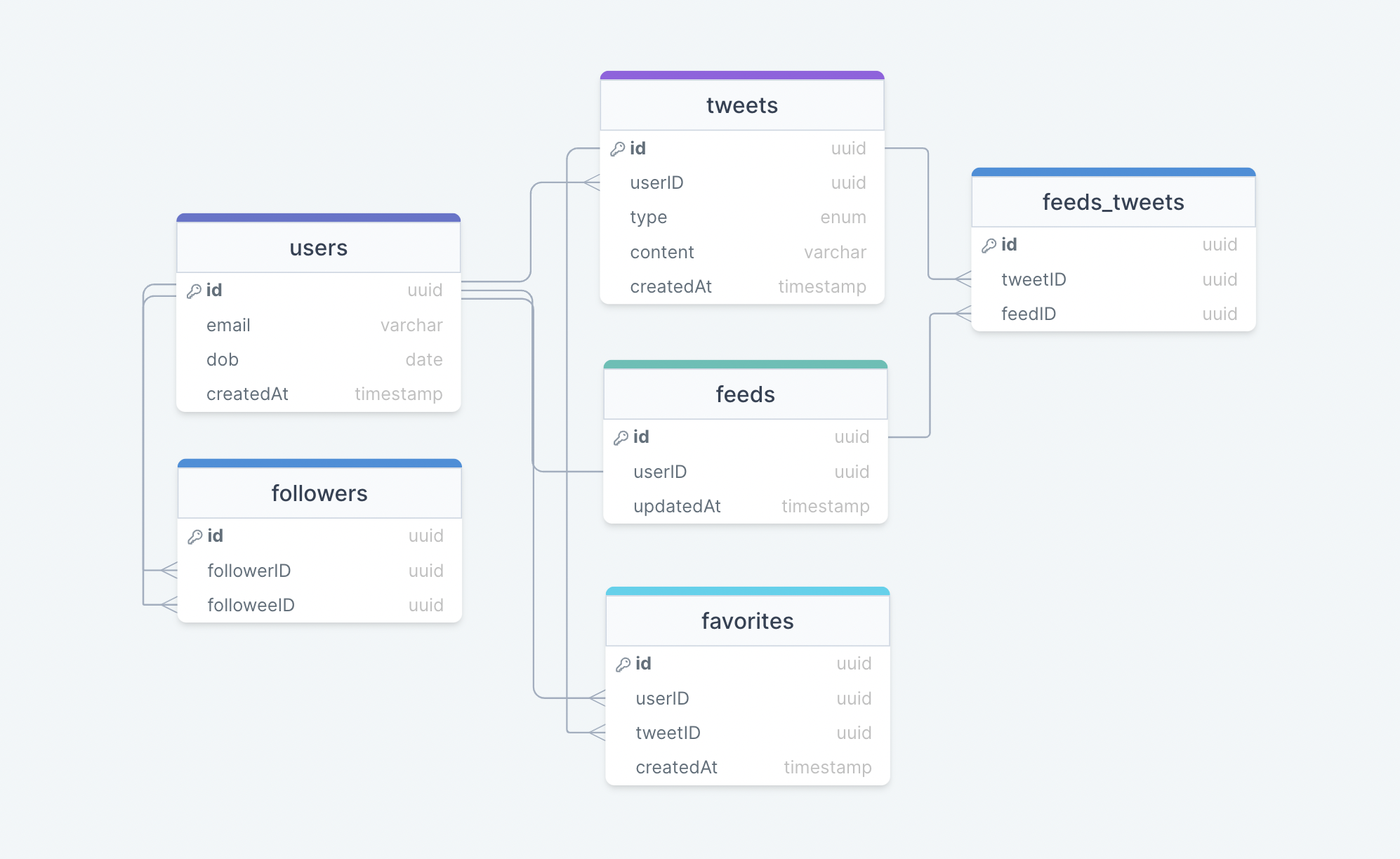
У нас есть следующие таблицы:
users
Эта таблица будет содержать информацию о пользователе, такую как имя, электронная почта, дата рождения и другие данные.
tweets
Как следует из названия, эта таблица будет хранить твиты и их свойства, такие как тип (текст, изображение, видео и т.д.), содержимое и т.д. Мы также будем хранить соответствующий userID.
favorites
Эта таблица сопоставляет твиты с пользователями для функционала избранных твитов в нашем приложении.
followers
Эта таблица сопоставляет подписчиков и подписанных, так как пользователи могут подписываться друг на друга (отношение N:M).
feeds
Эта таблица хранит свойства новостной ленты с соответствующим userID.
feeds_tweets
Эта таблица сопоставляет твиты и ленту (отношение N:M).
Какую базу данных мы должны использовать?
Хотя наша модель данных кажется довольно реляционной, нам не обязательно нужно хранить все в одной базе данных, так как это может ограничить нашу масштабируемость и быстро стать узким местом. Мы разделим данные между различными сервисами, каждый из которых будет владеть определенной таблицей. Затем мы можем использовать реляционную базу данных, такую как PostgreSQL или распределенную NoSQL базу данных, такую как Apache Cassandra для нашего случая использования.
Проектирование API
Давайте сделаем базовое проектирование API для наших сервисов:
Опубликовать твит
Это API позволит пользователю опубликовать твит на платформе.
postTweet(userID: UUID, content: string, mediaURL?: string): boolean
Параметры
ID пользователя (UUID): Идентификатор пользователя.
Содержание (string): Содержание твита.
URL медиафайла (string): URL прикрепленных медиафайлов (необязательно).
Возвращает
Результат (boolean): Отображает, успешно ли выполнена операция или нет.
Подписаться или отписаться от пользователя
Это API позволит пользователю подписаться или отписаться от другого пользователя.
follow(followerID: UUID, followeeID: UUID): boolean
unfollow(followerID: UUID, followeeID: UUID): boolean
Параметры
ID подписчика (UUID): ID текущего пользователя.
ID подписываемого (UUID): ID пользователя, которого мы хотим подписаться или отписаться.
Возвращает
Результат (boolean): Отображает, успешно ли выполнена операция или нет.
Получить новостную ленту
Это API вернет все твиты, которые должны быть отображены в данной новостной ленте.
getNewsfeed(userID: UUID): Tweet[]
Параметры
ID пользователя (UUID): ID пользователя.
Возвращает
Твиты (Tweet[]): Все твиты, которые должны быть отображены в данной новостной ленте.
Высокоуровневый дизайн
Теперь давайте сделаем высокоуровневый дизайн нашей системы.
Архитектура
Мы будем использовать микросервисную архитектуру, поскольку она позволит нам горизонтально масштабировать и разделить наши сервисы. Каждый сервис будет владеть своей собственной моделью данных. Давайте попробуем разделить нашу систему на некоторые основные сервисы.
Сервис пользователей
Этот сервис обрабатывает вопросы, связанные с пользователями, такие как аутентификация и информация о пользователе.
Сервис новостной ленты
Этот сервис будет обрабатывать создание и публикацию новостных лент пользователей. Об этом мы обсудим отдельно.
Сервис твитов
Сервис твитов будет обрабатывать связанные с твитами случаи использования, такие как публикация твита, избранные и т.д.
Сервис поиска
Этот сервис отвечает за функциональность поиска. Об этом мы обсудим отдельно.
Сервис медиафайлов
Этот сервис будет обрабатывать загрузку медиафайлов (изображений, видео, файлов и т. д.). Об этом мы обсудим отдельно.
Сервис уведомлений
Этот сервис просто будет отправлять уведомления пользователям.
Сервис аналитики
Этот сервис будет использоваться для метрик и аналитики.
Как насчет взаимосвязи между сервисами и обнаружения сервисов?
Поскольку наша архитектура основана на микросервисах, сервисы также будут взаимодействовать друг с другом. Обычно REST или HTTP работают хорошо, но мы можем дополнительно улучшить производительность, используя gRPC, который более легковесный и эффективный.
Обнаружение сервисов - это еще одна вещь, которую мы должны учесть. Мы также можем использовать сеть сервисов, которая обеспечивает управляемое, наблюдаемое и безопасное взаимодействие между отдельными сервисами.
Примечание: Узнайте больше о REST, GraphQL, gRPC и их сравнении между собой.
Лента новостей
Когда речь идет о ленте новостей, кажется, что ее достаточно легко реализовать, но существует много вещей, которые могут сделать эту функцию удачной или неудачной. Итак, давайте разделим нашу проблему на две части:
Генерация
Предположим, мы хотим сгенерировать ленту для пользователя A, мы выполним следующие шаги:
- Получить идентификаторы всех пользователей и сущностей (хэштегов, тем и т. д.), которых пользователь A следит.
- Получить соответствующие твиты для каждого из полученных идентификаторов.
- Использовать алгоритм ранжирования для ранжировки твитов на основе параметров, таких как релевантность, время, вовлеченность и т. д.
- Вернуть данные о ранжированных твитах клиенту в пагинированном виде.
Генерация ленты требует интенсивных вычислений и может занимать довольно много времени, особенно для пользователей, следящих за большим количеством людей. Для улучшения производительности ленту можно предварительно сгенерировать и хранить в кэше, а затем у нас может быть механизм периодического обновления ленты и применения нашего алгоритма ранжирования к новым твитам.
Публикация
Публикация - это этап, на котором данные ленты передаются в соответствии с каждым конкретным пользователем. Это может быть довольно тяжелая операция, поскольку у пользователя может быть миллионы друзей или подписчиков. Для решения этой проблемы у нас есть три разных подхода:
- Модель "Тянуть" (или Распространение нагрузки при загрузке)
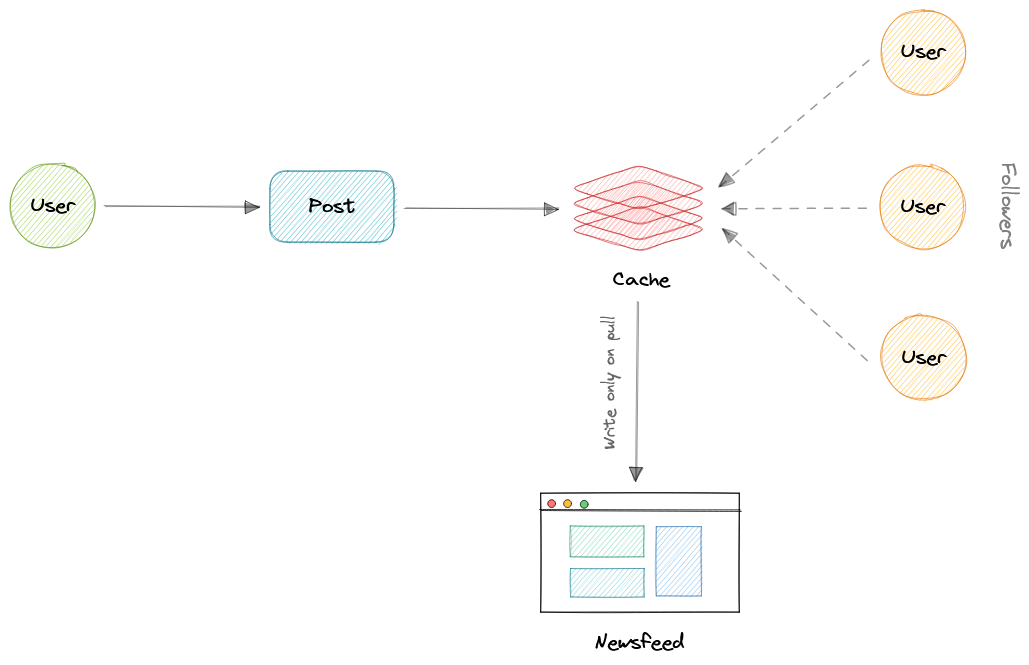
Когда пользователь создает твит, а подписчик обновляет свою ленту новостей, лента создается и хранится в памяти. Самая последняя лента загружается только тогда, когда пользователь запрашивает ее. Этот подход сокращает количество операций записи в нашей базе данных.
Недостатком этого подхода является то, что пользователи не смогут просматривать недавние ленты, пока они не "вытянут" данные с сервера, что увеличит количество операций чтения на сервере.
- Модель "Толкать" (или Распространение нагрузки при записи)
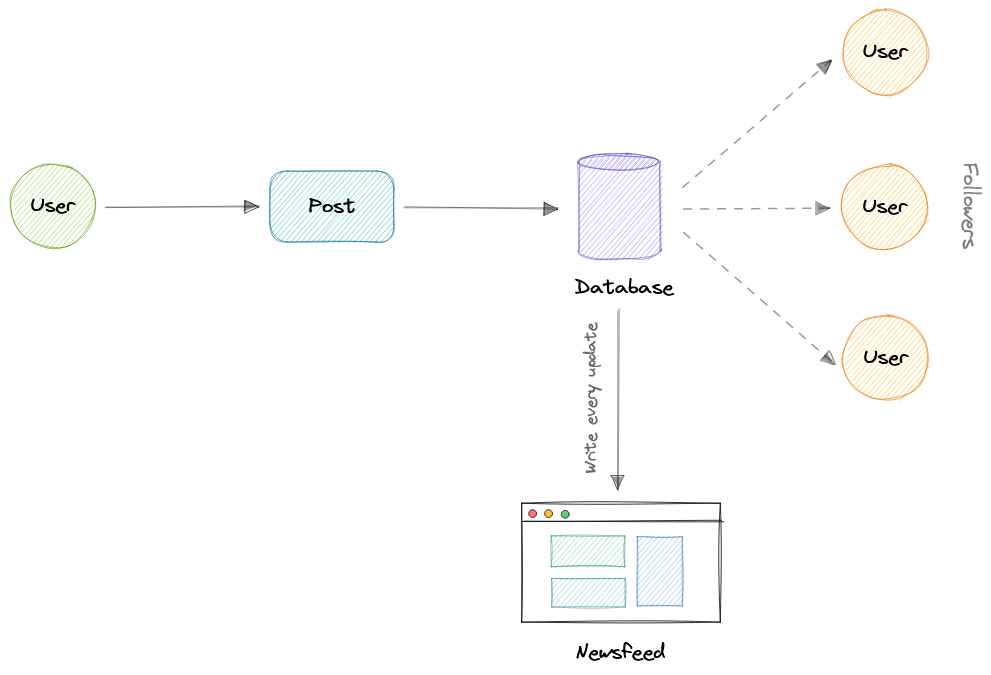
В этой модели, после того как пользователь создает твит, он "толкается" во все ленты подписчиков немедленно. Это предотвращает систему от необходимости просматривать список подписчиков пользователя для проверки обновлений.
Однако недостатком этого подхода является увеличение количества операций записи в базу данных.
- Гибридная модель
Третий подход - это гибридная модель между моделью "тянуть" и "толкать". Она объединяет положительные черты вышеперечисленных двух моделей и стремится обеспечить сбалансированный подход между ними.
Гибридная модель позволяет использовать модель "толкать" только для пользователей с меньшим количеством подписчиков. Для пользователей с большим количеством подписчиков, таких как знаменитости, используется модель "тянуть".
Алгоритм ранжирования
Как мы обсуждали ранее, нам потребуется алгоритм ранжирования, чтобы ранжировать каждый твит в соответствии с его релевантностью для каждого конкретного пользователя.
Например, Facebook раньше использовал алгоритм EdgeRank. Здесь ранг каждого элемента ленты описывается следующим образом:
$$ Ранг = Связь \times Вес \times Распад $$
Где,
Связь: это "близость" пользователя к создателю ребра. Если пользователь часто нажимает "Нравится", комментирует или отправляет сообщения создателю ребра, то значение связи будет выше, что приведет к более высокому рангу для сообщения.
Вес: это значение, присваиваемое каждому ребру. Комментарий может иметь более высокий вес, чем "Нравится", и поэтому сообщение с большим количеством комментариев более вероятно получит более высокий ранг.
Распад: это мера создания ребра. Чем старше ребро, тем меньше будет значение
распада и, следовательно, ранг.
В наши дни алгоритмы намного сложнее, и ранжирование выполняется с использованием моделей машинного обучения, которые учитывают тысячи факторов.
Перепосты
Перепосты являются одним из наших дополнительных требований. Чтобы реализовать эту функцию, мы можем просто создать новый твит с идентификатором пользователя, который делает репост оригинального твита, а затем изменить перечисление type и свойство content нового твита, чтобы связать его с оригинальным твитом.
Например, перечисление type может быть типа tweet, аналогично тексту, видео и т. д., а content может быть идентификатором оригинального твита. Здесь первая строка указывает на оригинальный твит, а вторая строка показывает, как мы можем представить перепост.
| id | userID | type | content | createdAt |
|---|---|---|---|---|
| ad34-291a-45f6-b36c | 7a2c-62c4-4dc8-b1bb | text | Привет, это мой первый твит… | 1658905644054 |
| f064-49ad-9aa2-84a6 | 6aa2-2bc9-4331-879f | tweet | ad34-291a-45f6-b36c | 1658906165427 |
Это очень простая реализация. Чтобы улучшить это, мы можем создать отдельную таблицу для хранения перепостов.
Поиск
Иногда традиционные СУБД недостаточно производительны, нам нужно что-то, что позволит нам хранить, искать и анализировать огромные объемы данных быстро и практически в реальном времени и давать результаты за миллисекунды. Elasticsearch может помочь нам в этом случае.
Elasticsearch - это распределенный, бесплатный и открытый поиск и аналитический движок для всех типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные данные. Он построен поверх Apache Lucene.
Как мы определяем трендовые темы?
Функциональность трендовых тем будет базироваться на основе функциональности поиска. Мы можем кэшировать наиболее часто запрашиваемые запросы, хэштеги и темы за последние N секунд и обновлять их каждые M секунд с помощью механизма пакетной обработки. Наш алгоритм ранжирования также может быть применен к трендовым темам, чтобы придать им больший вес и персонализировать их для пользователя.
Уведомления
Уведомления Push - это неотъемлемая часть любой социальной сети. Мы можем использовать очередь сообщений или брокер сообщений, такие как Apache Kafka с службой уведомлений для отправки запросов в Firebase Cloud Messaging (FCM) или Apple Push Notification Service (APNS), который будет обрабатывать доставку уведомлений push на устройства пользователей.
Для получения более подробной информации обратитесь к системе WhatsApp, где мы подробно обсуждаем уведомления push.
Подробный дизайн
Пришло время обсудить наши решения в подробностях.
Разделение данных
Для масштабирования наших баз данных нам потребуется разделить наши данные. Горизонтальное
разделение (также известное как Sharding) может быть хорошим первым шагом. Мы можем использовать схемы разделения, такие как:
- Хэш-основанное разделение
- Списочное разделение
- Разделение на основе диапазона
- Композитное разделение
Упомянутые выше подходы могут все же вызывать неравномерное распределение данных и нагрузки, мы можем решить эту проблему, используя Consistent hashing.
Для получения более подробной информации обратитесь к Sharding и Consistent Hashing.
Взаимные друзья
Для поиска взаимных друзей мы можем создать социальный граф для каждого пользователя. Каждый узел в графе будет представлять собой пользователя, а направленное ребро будет представлять подписчиков и подписки. Затем мы можем просматривать подписчиков пользователя, чтобы найти и предложить взаимного друга. Для этого потребуется графовая база данных, такая как Neo4j или ArangoDB.
Это довольно простой алгоритм, но для улучшения точности наших рекомендаций нам нужно будет включить модель рекомендаций, которая использует машинное обучение как часть нашего алгоритма.
Метрики и аналитика
Запись аналитики и метрик - одно из наших расширенных требований. Поскольку мы будем использовать Apache Kafka для публикации всех видов событий, мы можем обрабатывать эти события и проводить анализ данных с помощью Apache Spark, который является открытым универсальным движком аналитики для обработки данных в масштабе.
Кэширование
В приложении социальных сетей нам нужно быть осторожными с использованием кэша, так как наши пользователи ожидают последние данные. Поэтому, чтобы предотвратить пики использования ресурсов, мы можем кэшировать топ 20% твитов.
Чтобы дополнительно повысить эффективность, мы можем добавить пагинацию к нашим API системы. Это решение будет полезным для пользователей с ограниченной пропускной способностью сети, так как им не придется извлекать старые сообщения, если это не требуется.
Какую политику вытеснения кэша использовать?
Мы можем использовать решения вроде Redis или Memcached и кэшировать 20% ежедневного трафика, но какая политика вытеснения кэша лучше всего подходит для наших нужд?
Наименее используемый в последнее время (LRU) может быть хорошей политикой для нашей системы. В этой политике мы сначала удаляем ключи, которые использовались наименее недавно.
Как обрабатывать промахи кэша?
Когда происходит промах кэша, наши серверы могут обратиться к базе данных напрямую и обновить кэш новыми записями.
Для получения более подробной информации обратитесь к разделу Caching.
Доступ и хранение медиа-файлов
Как мы знаем, большую часть нашего пространства хранения будет использоваться для хранения медиа-файлов, таких как изображения, видео или другие файлы. Наша служба медиа-файлов будет обрабатывать как доступ, так и хранение медиа-файлов пользователей.
Но где мы можем хранить файлы в масштабе? Что касается этого, объектное хранилище идеально подходит. Объектные хранилища разбивают файлы данных на куски, называемые объектами. Затем эти объекты хранятся в едином хранилище, которое может быть распределено по нескольким сетям. Мы также можем использовать распределенное файловое хранилище, такое как HDFS или GlusterFS.
Сеть доставки контента (CDN)
Сеть доставки контента (CDN) повышает доступность и надежность контента, снижая при этом расходы на пропускную способность. Как правило, статические файлы, такие как изображения и видео, поставляются из CDN. Мы можем использовать такие сервисы, как Amazon CloudFront или Cloudflare CDN для этого случая использования.
Выявление и устранение узких мест
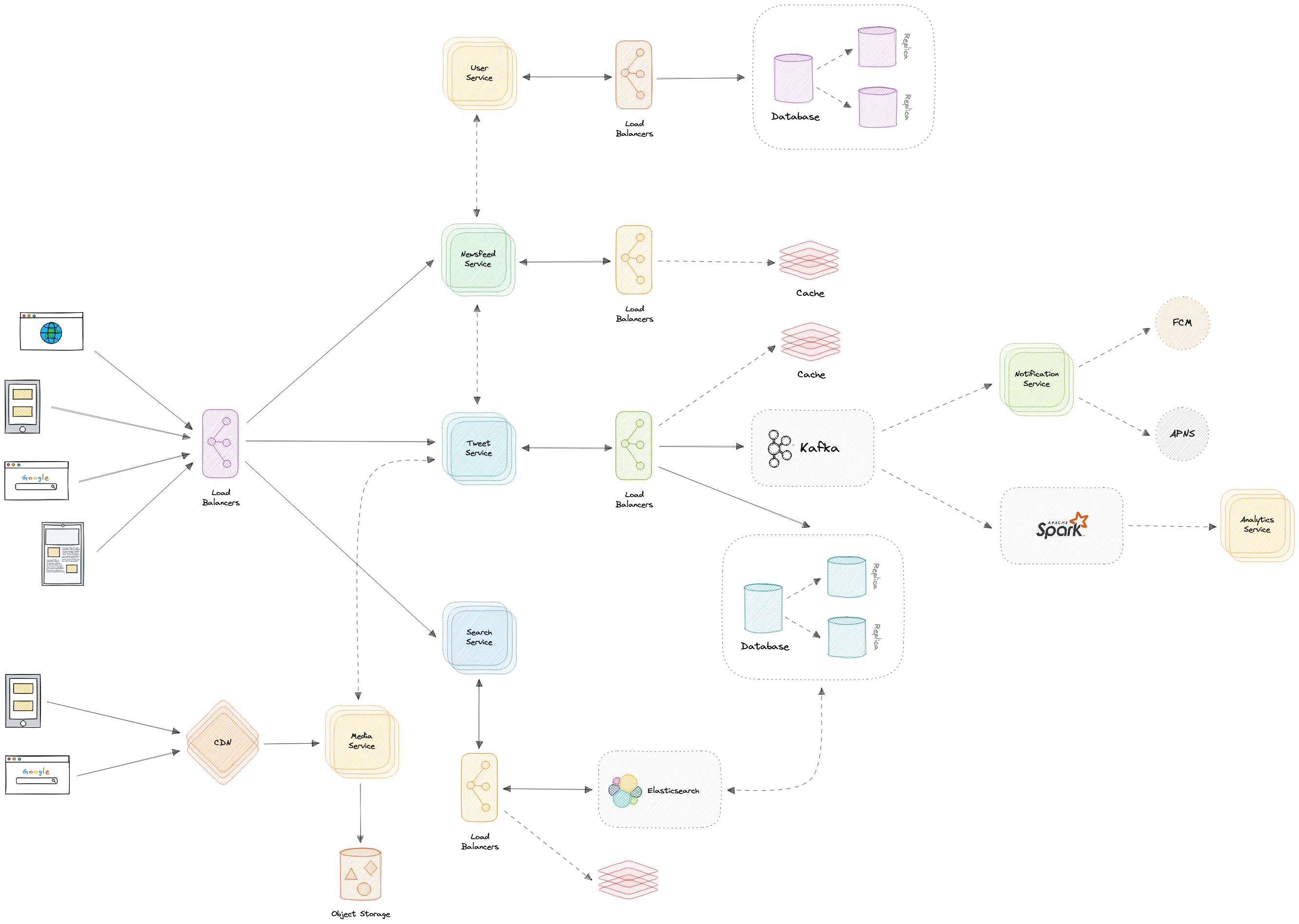
Давайте выявим и устраним узкие места, такие как единственные точки отказа в нашем дизайне:
- "Что произойдет, если один из наших сервисов выйдет из строя?"
- "Как мы распределим наш трафик между компонентами?"
- "Как мы можем снизить нагрузку на нашу базу данных?"
- "Как улучшить доступность нашего кэша?"
- "Как мы можем сделать нашу систему уведомлений более надежной?"
- "Как мы можем снизить затраты на хранение медиафайлов?"
Чтобы сделать нашу систему более надежной, мы можем сделать следующее:
- Запустить несколько экземпляров каждого из наших сервисов.
- Внедрить балансировщики нагрузки между клиентами, серверами, базами данных и кэш-серверами.
- Использовать несколько реплик для чтения наших баз данных.
- Несколько экземпляров и реплик для нашего распределенного кэша.
- Обеспечить гарантированную доставку и сохранение порядка сообщений в распределенной системе сложно, поэтому мы можем использовать специализированный брокер сообщений, такой как Apache Kafka или NATS, чтобы сделать нашу систему уведомлений более надежной.
- Мы можем добавить возможности обработки и сжатия медиафайлов в медиа-сервисе для сжатия больших файлов, что сэкономит много места на хранение и снизит затраты.
Netflix
Давайте разработаем сервис потокового видео, похожий на Netflix, такие как Amazon Prime Video, Disney Plus, Hulu, Youtube, Vimeo и другие.
Что такое Netflix?
Netflix - это подписной сервис потокового воспроизведения видео, который позволяет своим пользователям смотреть телешоу и фильмы на подключенных к интернету устройствах. Он доступен на таких платформах, как веб, iOS, Android, ТВ и т. д.
Требования
Наша система должна соответствовать следующим требованиям:
Функциональные требования
- Пользователи должны иметь возможность потокового воспроизведения и обмена видео.
- Команда контента (или пользователи в случае YouTube) должны иметь возможность загружать новые видео (фильмы, сериалы, эпизоды и другой контент).
- Пользователи должны иметь возможность искать видео по названиям или тегам.
- Пользователи должны иметь возможность комментировать видео, аналогично YouTube.
Нефункциональные требования
- Высокая доступность с минимальной задержкой.
- Высокая надежность, загрузки не должны быть потеряны.
- Система должна быть масштабируемой и эффективной.
Расширенные требования
- Определенный контент должен быть гео-блокирован.
- Возможность возобновления воспроизведения видео с того момента, на котором пользователь остановился.
- Запись метрик и аналитики видео.
Оценка и ограничения
Давайте начнем с оценки и ограничений.
Примечание: убедитесь в правильности всех предположений относительно масштаба или трафика с вашим интервьюером.
Трафик
Это будет система с высокой загрузкой на чтение, допустим, у нас есть 1 миллиард пользователей с общим числом пользователей 200 миллионов активных ежедневно (DAU), и в среднем каждый пользователь смотрит 5 видео в день. Это дает нам 1 миллиард просмотров видео в день.
$$ 200 \space миллионов \times 5 \space видео = 1 \space миллиард/день $$
Предположим соотношение чтения/записи 200:1, примерно 5 миллионов видео будет загружено ежедневно.
$$ \frac{1}{200} \times 1 \space миллиард = 5 \space миллионов/день $$
Какова будет скорость запросов в секунду (RPS) для нашей системы?
1 миллиард запросов в день превращаются в 12К запросов в секунду.
$$ \frac{1 \space миллиард}{(24 \space часа \times 3600 \space секунд)} = \sim 12K \space запросов/секунду $$
Хранение
Если мы предположим, что каждое видео в среднем составляет 100 МБ, нам понадобится около 500 ТБ хранилища ежедневно.
$$ 5 \space миллионов \times 100 \space МБ = 500 \space ТБ/день $$
И на 10 лет нам потребуется поразительных 1,825 ПБ хранилища.
$$ 500 \space ТБ \times 365 \space дней \times 10 \space лет = \sim 1,825 \space ПБ $$
Пропускная способность
Поскольку наша система обрабатывает 500 ТБ входного трафика ежедневно, нам понадобится минимальная пропускная способность около 5,8 ГБ в секунду.
$$ \frac{500 \space ТБ}{(24 \space часа \times 3600 \space секунд)} = \sim 5.8 \space ГБ/секунду $$
Оценка на высоком уровне
Вот наша оценка на высоком уровне:
| Тип | Оценка |
|---|---|
| Ежедневные активные пользователи (DAU) | 200 миллионов |
| Запросы в секунду (RPS) | 12K/секунду |
| Хранилище (в день) | ~500 ТБ |
| Хранилище (10 лет) | ~1,825 ПБ |
| Пропускная способность | ~5.8 ГБ/сек |
Проектирование модели данных
Это общая модель данных, отражающая наши требования.
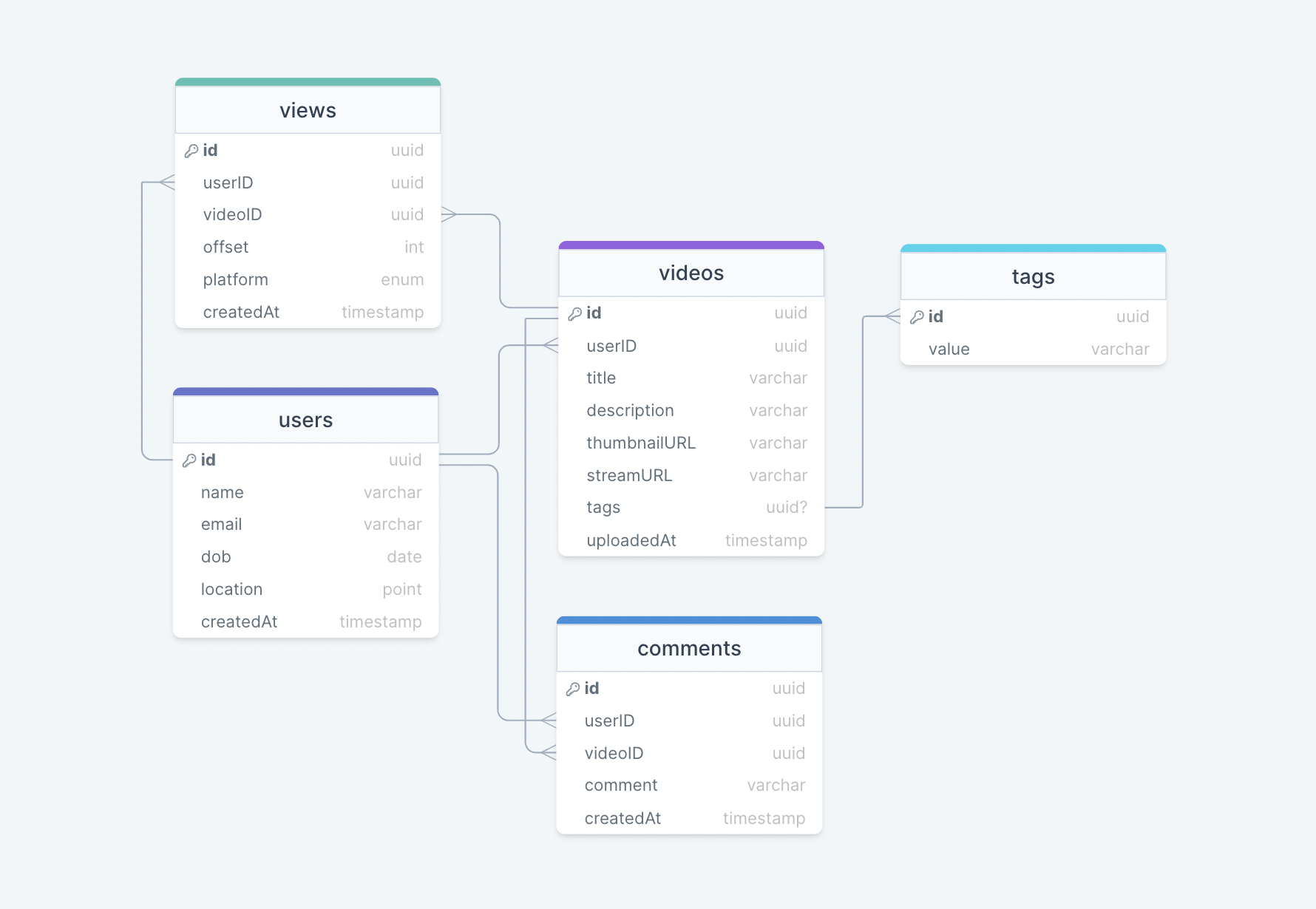
У нас есть следующие таблицы:
users
Эта таблица будет содержать информацию о пользователе, такую как name, email, dob и другие детали.
videos
Как следует из названия, эта таблица будет хранить видео и их свойства, такие как title, streamURL, tags и т. д. Мы также будем хранить соответствующий userID.
tags
Эта таблица будет просто хранить теги, связанные с видео.
views
Эта таблица помогает нам хранить все просмотры видео.
comments
Эта таблица хранит все комментарии, полученные на видео (как YouTube).
Какую базу данных следует использовать?
Хотя наша модель данных кажется достаточно реляционной, нам не обязательно нужно хранить все в одной базе данных, поскольку это может ограничить нашу масштабируемость и быстро стать узким местом.
Мы разделим данные между различными сервисами, каждый из которых будет владеть определенной таблицей. Затем мы можем использовать реляционную базу данных, такую как PostgreSQL или распределенную базу данных NoSQL, такую как Apache Cassandra для нашего случая использования.
Проектирование API
Давайте сделаем базовый дизайн API для наших сервисов:
Загрузка видео
Учитывая поток байтов, это API позволяет загружать видео в наш сервис.
uploadVideo(title: string, description: string, data: Stream<byte>, tags?: string[]): boolean
Параметры
Title (string): Название нового видео.
Description (string): Описание нового видео.
Data (byte[]): Поток байтов данных видео.
Tags (string[]): Теги для видео (опционально).
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Потоковое воспроизведение видео
Это API позволяет нашим пользователям потоково воспроизводить видео с предпочтительным кодеком и разрешением.
streamVideo(videoID: UUID, codec: Enum<string>, resolution: Tuple<int>, offset?: int): VideoStream
Параметры
ID видео (UUID): ID видео, которое нужно воспроизвести.
Кодек (Enum<string>): Требуемый кодек запрашиваемого видео, такой как h.265, h.264, VP9 и т. д.
Разрешение (Tuple<int>): Разрешение запрашиваемого видео.
Смещение (int): Смещение потока видео в секундах для передачи данных с любой точки в видео (опционально).
Возвращает
Поток (VideoStream): Поток данных запрошенного видео.
Поиск видео
Это API позволит нашим пользователям искать видео по его названию или тегам.
searchVideo(query: string, nextPage?: string): Video[]
Параметры
Запрос (string): Поисковый запрос пользователя.
Следующая страница (string): Токен для следующей страницы, это можно использовать для пагинации (опционально).
Возвращает
Видео (Video[]): Все видео, доступные для определенного поискового запроса.
Добавление комментария
Это API позволит нашим пользователям оставлять комментарии к видео (как на YouTube).
comment(videoID: UUID, comment: string): boolean
Параметры
ID видео (UUID): ID видео, на которое пользователь хочет оставить комментарий.
Комментарий (string): Текстовое содержание комментария.
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Проектирование высокого уровня
Теперь давайте сделаем высокоуровневый дизайн нашей системы.
Архитектура
Мы будем использовать архитектуру микросервисов, поскольку это облегчит горизонтальное масштабирование и разделит наши сервисы. Каждый сервис будет владеть своей собственной моделью данных. Давайте попробуем разделить нашу систему на некоторые основные сервисы.
Сервис пользователя
Этот сервис обрабатывает пользовательские запросы, такие как аутентификация и информация о пользователе.
Сервис потоковой передачи
Сервис потоковой передачи будет обрабатывать функциональность потоковой передачи видео.
Сервис поиска
Этот сервис отвечает за обработку поисковых запросов. Он будет подробно рассмотрен отдельно.
Сервис медиафайлов
Этот сервис будет обрабатывать загрузку и обработку видео. Он будет подробно рассмотрен отдельно.
Сервис аналитики
Этот сервис будет использоваться для метрических и аналитических случаев.
Что насчет межсервисного взаимодействия и обнаружения сервисов?
Поскольку наша архитектура основана на микросервисах, сервисы будут общаться друг с другом. Обычно REST или HTTP хорошо справляются, но мы можем дополнительно улучшить производительность, используя gRPC, который более легковесен и эффективен.
Обнаружение сервисов - это еще одна вещь, которую мы должны учитывать. Мы также можем использовать сеть сервисов, которая обеспечивает управляемое, наблюдаемое и безопасное взаимодействие между отдельными сервисами.
Примечание: Узнайте больше о REST, GraphQL, gRPC и о том, как они сравниваются между собой.
Обработка видео
Когда дело доходит до обработки видео, в игре участвует множество переменных. Например, средний размер данных двухчасовой необработанной видеозаписи 8K от высококачественной камеры может легко составлять до 4 ТБ, поэтому нам нужно иметь какой-то процесс обработки, чтобы уменьшить как затраты на хранение, так и доставку.
Вот как мы можем обрабатывать видео после их загрузки командой контента (или пользователями в случае YouTube), когда они находятся в очереди на обработку в нашей очереди сообщений.
Давайте обсудим, как это работает:
- Файловый разделитель
Это первый шаг нашего конвейера обработки. Разделение файла - это процесс разделения файла на более мелкие части, называемые кусками. Это позволяет нам устранить повторяющиеся копии повторяющихся данных на хранении и уменьшить объем передаваемых данных по сети, выбирая только измененные куски.
Обычно видеофайл можно разбить на части одинакового размера на основе временных меток, но Netflix вместо этого разбивает куски на сцены. Это небольшое изменение становится огромным фактором для лучшего пользовательского опыта, поскольку каждый раз, когда клиент запрашивает кусок у сервера, вероятность прерывания меньше, так как будет получен полный сюжет.
- Фильтр контента
Этот шаг проверяет, соответствует ли видео политике контента платформы. Это может быть предварительно утверждено, как в случае с Netflix в соответствии с рейтингом контента или может быть строго принудительным, как в случае с YouTube.
Всю эту обработку выполняет модель машинного обучения, которая выполняет проверку авторских прав, борьбу с пиратством и содержание NSFW. Если найдены проблемы, мы можем отправить задачу в очередь мертвых писем (DLQ), и кто-то из команды модерации может провести дополнительную проверку.
- Транскодер
Транскодирование - это процесс, при котором исходные данные декодируются в промежуточный несжатый формат, который затем кодируется в целевой формат. В этом процессе используются разные кодеки для выполнения регулировки битрейта, уменьшения размера изображения или повторного кодирования медиафайла.
Это приводит к файлу меньшего размера и гораздо более оптимизированному формату для целевых устройств. Можно использовать автономные решения, такие как FFmpeg или облачные решения, такие как AWS Elemental MediaConvert для реализации этого шага конвейера.
- Конвертация качества
Это последний шаг конвейера обработки, и, как следует из названия, этот шаг обрабатывает конвертацию транскодированного медиа из предыдущего шага в разные разрешения, такие как 4K, 1440p, 1080p, 720p и т. д.
Это позволяет нам получать желаемое качество видео в соответствии с запросом пользователя, и после завершения обработки медиафайл загружается в распределенное файловое хранилище, такое как HDFS, GlusterFS или объектное хранилище, такое как Amazon S3 для последующего извлечения во время потоковой передачи.
Примечание: Мы можем добавить дополнительные шаги, такие как генерация субтитров и миниатюр, как часть нашего конвейера.
Почему мы используем очередь сообщений?
Обработ
ка видео как долгосрочной задачи и использование очереди сообщений имеет гораздо больший смысл. Это также отделяет наш конвейер обработки видео от функциональности загрузки. Мы можем использовать что-то вроде Amazon SQS или RabbitMQ для поддержки этого.
Видеопоток
Потоковая передача видео является сложной задачей как с точки зрения клиента, так и с точки зрения сервера. Более того, скорости интернет-подключения весьма различаются у разных пользователей. Чтобы пользователи не повторно запрашивали тот же контент, мы можем использовать сеть доставки контента (CDN).
Netflix уходит еще дальше с программой Open Connect. В этом подходе они сотрудничают с тысячами поставщиков интернет-услуг (ISP), чтобы локализовать свой трафик и доставлять свой контент более эффективно.
В чем разница между Open Connect от Netflix и традиционной сетью доставки контента (CDN)?
Netflix Open Connect - это специализированная сеть доставки контента (CDN), отвечающая за обслуживание видеотрафика Netflix. Около 95% трафика глобально доставляется через прямые соединения между Open Connect и поставщиками услуг Интернета, которые используются их клиентами для доступа в Интернет.
В настоящее время у них есть устройства Open Connect Appliances (OCAs) в более чем 1000 отдельных местах по всему миру. В случае проблем устройства Open Connect Appliances (OCAs) могут переключаться на резервные каналы, и трафик может быть перенаправлен на серверы Netflix.
Дополнительно мы можем использовать протоколы адаптивного потокового вещания Adaptive bitrate streaming, такие как HTTP Live Streaming (HLS), который разработан для надежности и динамически адаптируется к сетевым условиям, оптимизируя воспроизведение для доступной скорости соединения.
Наконец, для воспроизведения видео с того момента, где пользователь остановился (часть наших расширенных требований), мы можем просто использовать свойство offset, которое мы сохраняем в таблице views, чтобы извлечь кусок сцены в этот конкретный момент времени и возобновить воспроизведение для пользователя.
Поиск
Иногда традиционные СУБД недостаточно производительны, нам нужно что-то, что позволяет нам хранить, искать и анализировать огромные объемы данных быстро и в режиме близком к реальному времени и предоставлять результаты в течение нескольких миллисекунд. Elasticsearch может помочь нам в этом случае.
Elasticsearch - это распределенный, бесплатный и открытый поисковый и аналитический движок для всех типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные данные. Он построен на основе Apache Lucene.
Как мы определяем актуальный контент?
Функциональность трендов будет основана на основе функциональности поиска. Мы можем кэшировать наиболее часто зап
рашиваемые запросы в последние N секунд и обновлять их каждые M секунд с помощью механизма пакетной обработки.
Обмен
Обмен контентом - важная часть любой платформы, для этого у нас может быть в наличии сервис сокращения URL, который может генерировать короткие URL-адреса для пользователей для обмена.
Для получения дополнительной информации обратитесь к URL Shortener системному проектированию.
Подробное проектирование
Пришло время обсудить наши решения по детальному проектированию.
Разделение данных
Чтобы масштабировать наши базы данных, нам нужно будет разделить наши данные. Горизонтальное разделение (также известное как Шардинг) может быть хорошим первым шагом. Мы можем использовать схемы разделения, такие как:
- Основанное на хеше разделение
- Разделение на основе списка
- Разделение на основе диапазона
- Композитное разделение
Вышеперечисленные подходы могут все же вызывать неравномерное распределение данных и нагрузки, мы можем решить это, используя Консистентное хеширование.
Для получения дополнительной информации обратитесь к Шардинг и Консистентное хеширование.
Гео-блокировка
Платформы, такие как Netflix и YouTube, используют гео-блокировку, чтобы ограничивать контент в определенных географических областях или странах. Это в основном делается из-за законов о правах на распространение, которым Netflix должен следовать при заключении сделок с производственными и распространительными компаниями. В случае YouTube это будет контролироваться пользователем во время публикации контента.
Мы можем определить местоположение пользователя, используя их IP-адрес или региональные настройки в их профиле, а затем использовать услуги, такие как Amazon CloudFront, которая поддерживает функцию географических ограничений, или политику маршрутизации по геолокации с Amazon Route53, чтобы ограничить контент и перенаправить пользователя на страницу ошибки, если контент недоступен в этом конкретном регионе или стране.
Рекомендации
Netflix использует модель машинного обучения, которая использует историю просмотров пользователя, чтобы предсказать, что пользователь мог бы захотеть посмотреть дальше, может использоваться алгоритм вроде Коллаборативной фильтрации.
Однако Netflix (как и YouTube) использует собственный алгоритм под названием Netflix Recommendation Engine, который может отслеживать несколько данных, таких как:
- Информация о профиле пользователя, такая как возраст, пол и местоположение.
- Поведение пользователя при просмотре и прокрутке.
- Время и дата, когда пользователь просмотрел заголовок.
- Устройство, которое использовалось для потоковой передачи контента.
- Количество запросов и термины поиска.
Дополнительные сведения можно найти в исследованиях Netflix о рекомендациях.
Метрики и аналитика
Запись аналитики и метрик - одно из наших расширенных требований. Мы можем собирать данные из различных служб и проводить аналитику данных с использованием Apache Spark, который является открытым масштабируемым движком аналитики для обработки данных большого объема. Кроме того, мы можем хранить важные метаданные в таблице views для увеличения количества точек данных в нашем наборе данных.
Кэширование
В потоковой платформе кэширование важно. Мы должны иметь возможность кэшировать как можно больше статического медиаконтента, чтобы улучшить пользовательский опыт. Мы можем использовать решения, такие как Redis или Memcached, но какая политика вытеснения кэша лучше всего подходит для наших нужд?
Какую политику вытеснения кэша использовать?
Наименее используемый недавно (LRU) может быть хорошей политикой для нашей системы. В этой политике мы сначала отбрасываем наименее используемый ключ.
Как обрабатывать промах кэша?
В случае промаха кэша наши серверы могут обращаться к базе данных напрямую и обновлять кэш новыми записями.
Дополнительные сведения можно найти в Кэшировании.
Медиа-стриминг и хранение
Поскольку большая часть нашего пространства хранения будет использоваться для хранения медиафайлов, таких как миниатюры и видео. Согласно нашему предыдущему обсуждению, сервис медиа будет обрабатывать как загрузку, так и обработку медиафайлов.
Мы будем использовать распределенное файловое хранилище, такое как HDFS, GlusterFS или объектное хранилище, такое как Amazon S3, для хранения и потоковой передачи контента.
Сеть доставки контента (CDN)
Сеть доставки контента (CDN) увеличивает доступность и надежность контента, снижая при этом затраты на пропускную способность. Обычно статические файлы, такие как изображения и видео, обслуживаются с CDN. Мы можем использовать услуги, такие как Amazon CloudFront или Cloudflare CDN для этого случая использования.
Выявление и устранение узких мест
Позвольте нам выявить и устранить узкие места, такие как единичные точки отказа в нашем дизайне:
- "Что если один из наших сервисов упадет?"
- "Как мы распределим наш трафик между компонентами?"
- "Как мы можем снизить нагрузку на нашу базу данных?"
- "Как улучшить доступность нашего кэша?"
Чтобы сделать нашу систему более устойчивой, мы можем сделать следующее:
- Запуск нескольких экземпляров каждого из наших сервисов.
- Внедрение балансировщиков нагрузки между клиентами, серверами, базами данных и серверами кэша.
- Использование нескольких реплик для наших баз данных.
- Несколько экземпляров и реплик для нашего распределенного кэша.
Uber
Давайте разработаем сервис заказа такси, подобный Uber, аналогичный сервисам такси, таким как Lyft, OLA Cabs и т. д.
Что такое Uber?
Uber - это поставщик услуг мобильности, позволяющий пользователям заказывать поездки, а водителям транспортировать их аналогично такси. Он доступен на веб-платформе и мобильных платформах, таких как Android и iOS.
Требования
Наша система должна соответствовать следующим требованиям:
Функциональные требования
Мы разработаем нашу систему для двух типов пользователей: Клиентов и Водителей.
Клиенты
- Клиенты должны иметь возможность видеть все такси в окрестностях с информацией о времени прибытия и цене.
- Клиенты должны иметь возможность заказать такси до места назначения.
- Клиенты должны иметь возможность видеть местоположение водителя.
Водители
- Водители должны иметь возможность принять или отклонить заказ клиента.
- После принятия водитель должен видеть место подачи клиента.
- Водители должны иметь возможность отметить поездку как завершенную при достижении места назначения.
Нефункциональные требования
- Высокая надежность.
- Высокая доступность с минимальной задержкой.
- Система должна быть масштабируемой и эффективной.
Дополнительные требования
- Клиенты могут оценивать поездку после ее завершения.
- Обработка платежей.
- Метрики и аналитика.
Оценка и Ограничения
Давайте начнем с оценки и ограничений.
Примечание: Убедитесь, что все предположения о масштабе или трафике согласованы с вашим интервьюером.
Трафик
Давайте предположим, что у нас есть 100 миллионов активных пользователей ежедневно (DAU) с 1 миллионом водителей, и в среднем наша платформа обеспечивает 10 миллионов поездок ежедневно.
Если в среднем каждый пользователь выполняет 10 действий (таких как запрос на доступные поездки, тарифы, заказ поездок и т. д.), нам придется обрабатывать 1 миллиард запросов ежедневно.
$$ 100 \space миллионов \times 10 \space действий = 1 \space миллиард/день $$
Какова будет скорость запросов в секунду (RPS) для нашей системы?
1 миллиард запросов в день переводятся в 12 тысяч запросов в секунду.
$$ \frac{1 \space миллиард}{(24 \space часа \times 3600 \space секунд)} = \sim 12K \space запросов/секунду $$
Хранение данных
Если мы предположим, что каждое сообщение в среднем составляет 400 байт, нам потребуется около 400 ГБ базового хранилища данных ежедневно.
$$ 1 \space миллиард \times 400 \space байт = \sim 400 \space ГБ/день $$
И на протяжении 10 лет нам потребуется около 1,4 ПБ хранилища.
$$ 400 \space ГБ \times 10 \space лет \times 365 \space дней = \sim 1,4 \space ПБ $$
Пропускная способность
Поскольку наша система обрабатывает 400 ГБ входящего трафика каждый день, нам потребуется минимальная пропускная способность около 5 МБ в секунду.
$$ \frac{400 \space ГБ}{(24 \space часа \times 3600 \space секунд)} = \sim 5 \space МБ/секунду $$
Высокоуровневая оценка
Вот наша высокоуровневая оценка:
| Тип | Оценка |
|---|---|
| Ежедневные активные пользователи (DAU) | 100 миллионов |
| Запросы в секунду (RPS) | 12K/с |
| Хранилище (ежедневно) | ~400 ГБ |
| Хранилище (10 лет) | ~1,4 ПБ |
| Пропускная способность | ~5 МБ/с |
Проектирование структуры данных
Это общая структура данных, отражающая наши требования.

У нас есть следующие таблицы:
клиенты
Эта таблица будет содержать информацию о клиентах, такую как имя, электронная почта и другие детали.
водители
Эта таблица будет содержать информацию о водителях, такую как имя, электронная почта, дата рождения и другие детали.
поездки
Эта таблица представляет собой поездку, совершенную клиентом, и содержит данные, такие как источник, назначение и статус поездки.
такси
Эта таблица хранит данные, такие как регистрационный номер и тип (например, Uber Go, Uber XL и т. Д.) такси, которым будет управлять водитель.
рейтинги
Как следует
из названия, эта таблица содержит рейтинг и отзыв о поездке.
платежи
Таблица платежей содержит данные, относящиеся к платежам, с соответствующим tripID.
Какую базу данных следует использовать?
Хотя наша модель данных достаточно реляционна, нам не обязательно нужно хранить все в одной базе данных, так как это может ограничить нашу масштабируемость и быстро стать узким местом. Мы разделим данные между разными службами, каждая из которых будет владеть определенной таблицей. Затем мы можем использовать реляционную базу данных, такую как PostgreSQL или распределенную NoSQL базу данных, такую как Apache Cassandra для нашего случая использования.
Проектирование API
Давайте разработаем базовый дизайн API для наших служб:
Запрос на поездку
Через это API клиенты смогут заказать поездку.
requestRide(customerID: UUID, source: Tuple<float>, destination: Tuple<float>, cabType: Enum<string>, paymentMethod: Enum<string>): Ride
Параметры
Customer ID (UUID): Идентификатор клиента.
Источник (Tuple<float>): Кортеж, содержащий широту и долготу начального местоположения поездки.
Назначение (Tuple<float>): Кортеж, содержащий широту и долготу места назначения поездки.
Возвращает
Результат (Ride): Информация о заказанной поездке.
Отмена поездки
Это API позволит клиентам отменить поездку.
cancelRide(customerID: UUID, reason?: string): boolean
Параметры
Customer ID (UUID): Идентификатор клиента.
Причина (UUID): Причина отмены поездки (необязательно).
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Принять или отклонить поездку
Это API позволит водителю принять или отклонить поездку.
acceptRide(driverID: UUID, rideID: UUID): boolean
denyRide(driverID: UUID, rideID: UUID): boolean
Параметры
Driver ID (UUID): Идентификатор водителя.
Ride ID (UUID): Идентификатор заказанной клиентом поездки.
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Начать или закончить поездку
С помощью этого API водитель сможет начать и закончить поездку.
startTrip(driverID: UUID, tripID: UUID): boolean
endTrip(driverID: UUID, tripID: UUID): boolean
Параметры
Driver ID (UUID): Идентификатор водителя.
Trip ID (UUID): Идентификатор запрошенной поездки.
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Оценить поездку
Это API позволит клиентам оценить поездку.
rateTrip(customerID: UUID, tripID: UUID, rating: int, feedback?: string): boolean
Параметры
Customer ID (UUID): Идентификатор клиента.
Trip ID (UUID): Идентификатор завершенной поездки.
Rating (int): Оценка поездки.
Feedback (string): Обратная связь о поездке от клиента (необязательно).
Возвращает
Результат (boolean): Показывает, успешно ли выполнена операция или нет.
Высокоуровневый дизайн
Теперь давайте разработаем высокоуровневый дизайн нашей системы.
Архитектура
Мы будем использовать архитектуру микросервисов, так как она облегчит горизонтальное масштабирование и разделение наших служб. Каждая служба будет иметь свою собственную модель данных. Давайте попробуем разделить нашу систему на несколько основных служб.
Служба клиентов
Эта служба обрабатывает все вопросы, связанные с клиентами, такие как аутентификация и информация о клиентах.
Служба водителей
Эта служба обрабатывает все вопросы, связанные с водителями, такие как аутентификация и информация о водителях.
Служба поездок
Эта служба будет отвечать за сопоставление поездок и агрегацию квадродерева. Она будет рассмотрена более подробно отдельно.
Служба поездок
Эта служба отвечает за функциональность, связанную с поездками в нашей системе.
Служба платежей
Эта служба будет отвечать за обработку платежей в нашей системе.
Служба уведомлений
Эта служба просто будет отправлять уведомления пользователям. Она будет рассмотрена более подробно отдельно.
Служба аналитики
Эта служба будет использоваться для метрик и аналитики.
Что насчет межсервисного взаимодействия и обнаружения служб?
Поскольку наша архитектура основана на микросервисах, службы будут взаимодействовать друг с другом. Обычно REST или HTTP хорошо справляются, но мы можем дополнительно улучшить производительность, используя gRPC, который более легкий и эффективный.
Обнаружение служб - еще один аспект, который мы должны учитывать. Мы также можем использовать сеть служб, которая обеспечивает управляемое, наблюдаемое и безопасное взаимодействие между отдельными службами.
Примечание: Узнайте больше о REST, GraphQL, gRPC и их сравнении между собой.
Как ожидается работа службы?
Вот как ожидается работа нашей службы:
- Клиент заказывает поездку, указывая место отправления, место назначения, тип машины, способ оплаты и т. д.
- Служба поездок регистрирует этот запрос, находит ближайших водителей и рассчитывает предполагаемое время прибытия (ETA).
- Запрос затем транслируется ближайшим водителям для их принятия или отклонения.
- Если водитель принимает, клиент получает уведомление о текущем местоположении водителя с предполагаемым временем прибытия (ETA) в ожидании подачи.
- Клиент подбирается, и водитель может начать поездку.
- Как только достигнут пункт назначения, водитель отмечает поездку как завершенную и получает оплату.
- После завершения оплаты клиент может оставить оценку и обратную связь о поездке, если он хочет.
Отслеживание местоположения
Как эффективно отправлять и получать данные о текущем местоположении от клиента (клиентов и водителей) нашему серверу? У нас есть два разных варианта:
Модель опроса
Клиент может периодически отправлять HTTP-запросы на сервер для сообщения о текущем местоположении и получения информации о времени прибытия (ETA) и ценообразовании. Это можно сделать с помощью метода, такого как Длинные опросы.
Модель отправки
Клиент открывает долговременное соединение с сервером, и как только новые данные станут доступны, они будут отправлены клиенту. Мы можем использовать WebSockets или [События, отправленные сервером (SSE)]
(https://karanpratapsingh.com/courses/system-design/long-polling-websockets-server-sent-events#server-sent-events-sse) для этого.
Подход модели опроса не масштабируется, так как он создает ненужную нагрузку запросов на наши серверы, и большую часть времени ответ будет пустым, что приведет к излишнему расходу ресурсов. Для минимизации задержки лучше всего использовать модель отправки с WebSockets, так как тогда мы можем отправлять данные клиенту сразу же, как только они станут доступны, без задержек, при условии, что соединение открыто с клиентом. Кроме того, WebSockets обеспечивают полнодуплексное взаимодействие, в отличие от Событий, отправленных сервером (SSE), которые работают только в одном направлении.
Кроме того, приложение клиента должно иметь механизм фоновой задачи для опроса GPS-местоположения, пока приложение находится в фоновом режиме.
Для получения дополнительной информации ознакомьтесь с Длинными опросами, WebSockets, Событиями, отправленными сервером (SSE).
Сопоставление поездок
Нам нужен способ эффективного хранения и запроса ближайших водителей. Давайте рассмотрим различные решения, которые мы можем внедрить в наш дизайн.
SQL
У нас уже есть доступ к широте и долготе наших клиентов, и с помощью баз данных, таких как PostgreSQL и MySQL, мы можем выполнить запрос для поиска ближайших местоположений водителей, задав широту и долготу (X, Y) в пределах радиуса (R).
SELECT * FROM locations WHERE lat BETWEEN X-R AND X+R AND long BETWEEN Y-R AND Y+R
Однако это не масштабируется, и выполнение этого запроса на больших объемах данных будет довольно медленным.
Geohashing
Геокодирование - это метод геокодирования, используемый для кодирования географических координат, таких как широта и долгота, в короткие алфавитно-цифровые строки. Он был создан Густаво Нимейер в 2008 году.
Geohash - это иерархический пространственный индекс, который использует кодирование алфавитом Base-32, где первый символ в геохеше определяет начальное местоположение в одной из 32 ячеек. Эта ячейка также содержит 32 ячейки. Это означает, что для представления точки мир рекурсивно делится на все меньшие и меньшие ячейки с каждым дополнительным битом до достижения желаемой точности. Фактор точности также определяет размер ячейки.
Например, Сан-Франциско с координатами 37.7564, -122.4016 может быть представлен в виде геохеша как 9q8yy9mf.
Теперь, используя геохеш клиента, мы можем определить ближайшего доступного водителя простым сравнением его с геохешем водителя. Для повышения производительности мы проиндексируем и сохраним геохеш водителя в памяти для более быстрого извлечения.
Квадродеревья
[Квадродеревья](https://karanpratapsingh.com/courses/system-design/geohashing-and-quadtrees#
quadtrees) - это древовидная структура данных, в которой каждый внутренний узел имеет ровно четыре дочерних узла. Они часто используются для разделения двумерного пространства путем рекурсивного его подразделения на четыре квадранта или региона. Каждый дочерний или листовой узел содержит пространственную информацию. Квадродеревья являются двумерным аналогом Октодеревьев, которые используются для разделения трехмерного пространства.
Квадродеревья позволяют эффективно искать точки внутри двумерного диапазона, где эти точки определены как координаты широты/долготы или как декартовы (x, y) координаты.
Мы можем сэкономить дополнительные вычисления, разбив узел только после достижения определенного порога.
Квадродеревья кажутся идеальным выбором для нашего случая использования, мы можем обновлять квадродерево каждый раз, когда получаем новое обновление местоположения от водителя. Чтобы снизить нагрузку на серверы квадродерева, мы можем использовать хранилище данных в памяти, такое как Redis, для кэширования последних обновлений. И с применением алгоритмов отображения, таких как Кривая Хилберта, мы можем выполнять эффективные диапазонные запросы для поиска ближайших водителей для клиента.
Что насчет гонок?
Гонки могут легко возникать, когда большое количество клиентов одновременно будет запрашивать поездки. Чтобы избежать этого, мы можем обернуть нашу логику сопоставления поездок в Мьютекс для избегания любых гонок. Кроме того, каждое действие должно быть транзакционным по своей природе.
Для получения дополнительной информации обратитесь к Транзакциям и Распределенным транзакциям.
Как найти лучших водителей поблизости?
После получения списка ближайших водителей от серверов квадродерева мы можем выполнить какую-то сортировку на основе параметров, таких как средние оценки, актуальность, обратная связь от прошлых клиентов и т. д. Это позволит нам в первую очередь отправлять уведомления лучшим доступным водителям.
Работа с повышенным спросом
В случае повышенного спроса мы можем использовать концепцию Динамической Ценообразования. Динамическое ценообразование - это метод динамического изменения цен в ответ на увеличение спроса и в основном ограниченное предложение. Эту динамическую цену можно добавить к базовой цене поездки.
Для получения дополнительной информации узнайте, как работает динамическое ценообразование с Uber.
Платежи
Обработка платежей в масштабе представляет собой сложную задачу, для упрощения нашей системы мы можем использовать сторонний процессор платежей, такой как Stripe или PayPal. После завершения платежа процессор платежей перенаправит пользователя обратно на наше приложение, и мы можем настроить вебхук для захвата всех данных, связанных с платежом.
Уведомления
Push-уведомления будут неотъемлемой частью нашей платформы. Мы можем использовать очередь сообщений или брокера сообщений, таких как Apache Kafka, с сервисом уведомлений для отправки запросов в Firebase Cloud Messaging (FCM) или Apple Push Notification Service (APNS), который будет обрабатывать доставку push-уведомлений на устройства пользователей.
Дополнительные подробности смотрите в системе уведомлений WhatsApp, где мы подробно обсуждаем push-уведомления.
Подробный дизайн
Пришло время обсудить наши дизайнерские решения подробнее.
Разделение данных
Для масштабирования наших баз данных нам потребуется разделить наши данные. Горизонтальное разделение (также известное как шардинг) может быть хорошим первым шагом. Мы можем шардировать нашу базу данных либо на основе существующих схем разделения, либо по регионам. Если мы разделим местоположения на регионы, используя, скажем, почтовые индексы, мы можем эффективно хранить все данные в данном регионе на фиксированном узле. Но это все равно может вызвать неравномерное распределение данных и нагрузки, мы можем решить это, используя Согласованное хеширование.
Дополнительные подробности смотрите в Шардинге и Согласованном хешировании.
Метрики и аналитика
Запись аналитики и метрик является одним из наших расширенных требований. Мы можем захватывать данные из различных сервисов и выполнять аналитику данных с помощью Apache Spark, который является открытым аналитическим движком для обработки данных большого масштаба. Кроме того, мы можем хранить критически важные метаданные в таблице представлений, чтобы увеличить количество точек данных в наших данных.
Кэширование
В платформе на основе сервисов местоположения кэширование важно. Мы должны иметь возможность кэшировать последние местоположения клиентов и водителей для быстрого извлечения. Мы можем использовать решения, такие как Redis или Memcached, но какая политика вытеснения кэша лучше всего подходит нашим потребностям?
Какую политику вытеснения кэша использовать?
[Наименее
недавно использованный (LRU)](https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_recently_used_(LRU)) может быть хорошей политикой для нашей системы. В этой политике мы сначала отбрасываем ключ, который использовался наименее недавно.
Как обрабатывать промах кэша?
В случае промаха кэша наши серверы могут обращаться к базе данных напрямую и обновлять кэш новыми записями.
Дополнительные подробности смотрите в Кэшировании.
Выявление и устранение узких мест
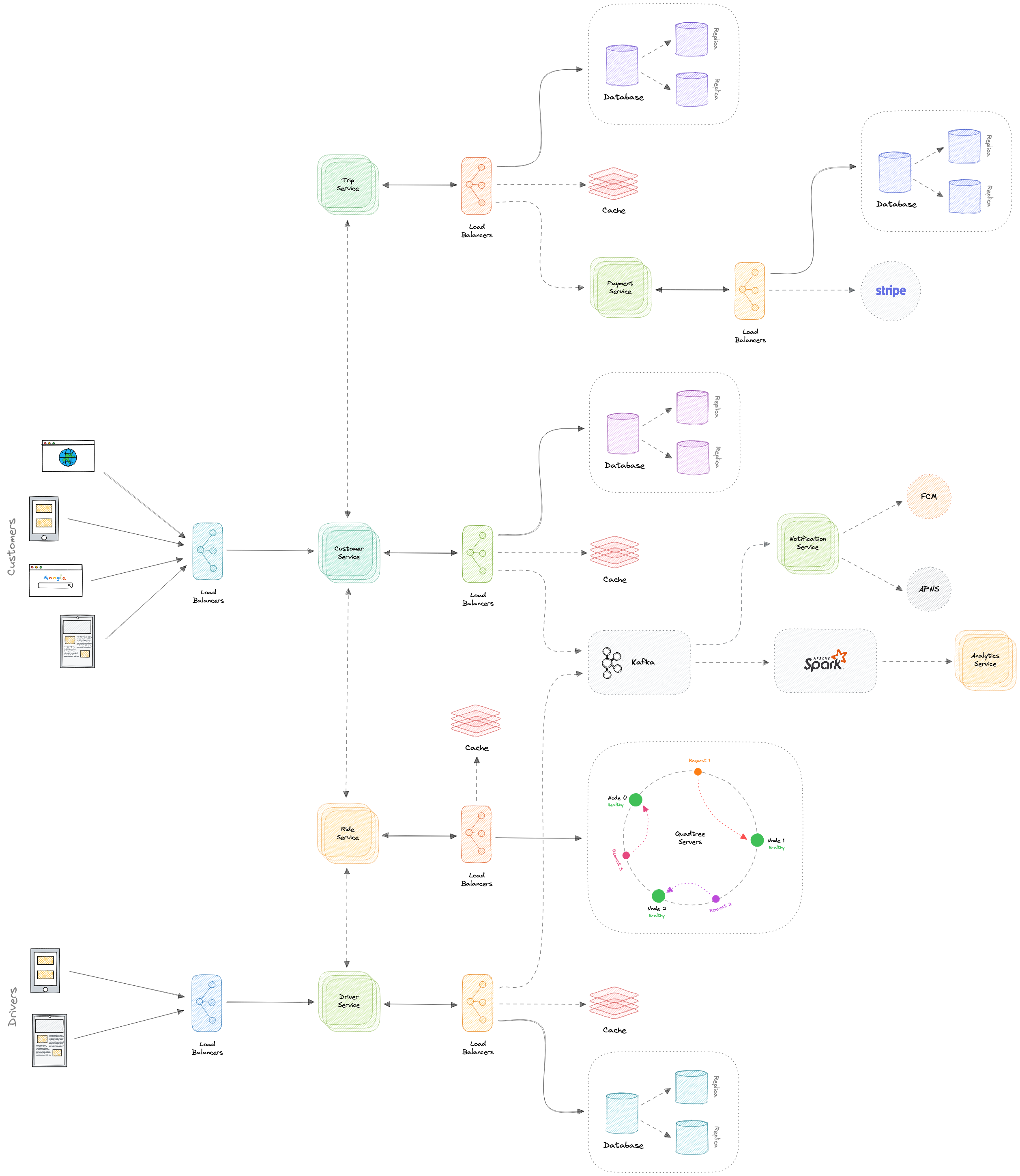
Давайте выявим и устраним узкие места, такие как единственные точки отказа в нашем дизайне:
- "Что, если один из наших сервисов выйдет из строя?"
- "Как мы будем распределять наш трафик между нашими компонентами?"
- "Как мы можем снизить нагрузку на нашу базу данных?"
- "Как улучшить доступность нашего кэша?"
- "Как мы можем сделать нашу систему уведомлений более надежной?"
Чтобы сделать нашу систему более надежной, мы можем сделать следующее:
- Запуск нескольких экземпляров каждого из наших сервисов.
- Внедрение балансировщиков нагрузки между клиентами, серверами, базами данных и серверами кэша.
- Использование нескольких реплик для чтения наших баз данных.
- Несколько экземпляров и реплик для нашего распределенного кэша.
- Доставка ровно одного раза и упорядочивание сообщений являются сложными задачами в распределенной системе, мы можем использовать специализированный брокер сообщений, такой как Apache Kafka или NATS, чтобы сделать нашу систему уведомлений более надежной.
Что дальше?
Поздравляю, вы завершили курс!
Теперь, когда вы знаете основы проектирования систем, вот несколько дополнительных ресурсов:
- Распределенные системы (Dr. Martin Kleppmann)
- Проектирование систем. Подробный гид
- Микросервисы (Chris Richardson)
- Вычисления без сервера
- Kubernetes
Также рекомендуется активно следить за блогами инженерных команд компаний, которые успешно применяют то, что мы изучили в курсе:
- Инженерия Microsoft
- Блог исследований Google
- Технический блог Netflix
- Блог AWS
- Инженерия Facebook
- Технический блог Uber
- Инженерия Airbnb
- Технический блог GitHub
- Блог программного обеспечения Intel
- Инженерия LinkedIn
- Блог разработчика PayPal
- Инженерия Twitter
И, конечно же, стоит активно участвовать в новых проектах в вашей компании и учиться у старших инженеров и архитекторов, чтобы дальше совершенствовать свои навыки в проектировании систем.
Я надеюсь, этот курс был для вас отличным учебным опытом. Буду рад услышать ваш отзыв.
Желаю вам успехов в дальнейшем обучении!
Полезные ссылки
Вот ресурсы, на которые мы ссылались при создании этого курса.
- Центр обучения Cloudflare
- Блоги IBM
- Блоги Fastly
- Блоги NS1
- Система Дизайн Интервью
- Шаблоны дизайна микросервисов
- System Design Primer
- Блоги AWS
- Архитектурные шаблоны от Microsoft
- Martin Fowler
- Ресурсы PagerDuty
- Блоги VMWare
Все диаграммы были созданы с использованием Excalidraw и доступны здесь.
